
360 系统部成立于 2010 年,负责整个集团的大数据底层基础平台建设(包括分布式存储、分布式计算、大数据搜索、图计算等各类大数据服务),目前服务于整个集团 30+部门,1000+用户,服务器 25000+,存储数据量 EB 级。
奇麟(Qirin),是由系统部研发的一站式大数据平台,完整覆盖了大数据的采、存、管、算、用整个大数据开发和处理流程,可以帮助业务部门快速构建自己的数据平台及数据产品。
本文从整体层面介绍了奇麟大数据平台以及对每个功能模块进行概述,后续将有其他文章,对主要模块进行详细介绍。
奇麟大数据平台架构
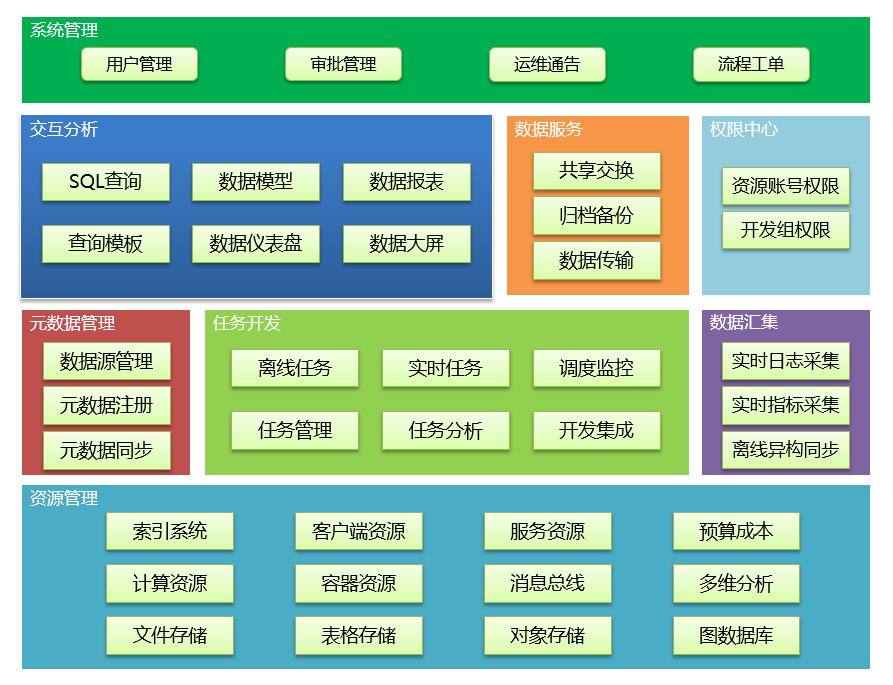
奇麟大数据平台功能架构图
从功能上,奇麟主要由以下模块构成(自底向上):
(1) 资源管理:用于各类大数据服务资源的申请和管理,以及访问权限的申请与管理,包括存储资源、计算资源等;
(2) 元数据管理:基于资源管理,为其他模块提供统一视图,将整个大数据处理平台(流程)贯穿起来。元数据管理一方面支持奇麟系统平台资源,同时也支持用户导入外部自有资源,进而托管应用;
(3) 数据汇集:用于将外部数据汇集到大数据存储中,包括实时和离线的数据汇集;
(4) 任务开发:批流合一的任务平台,用于开发、调度、监控实时和离线数据处理任务;
(5) 交互分析:用于使用 SQL 快速查询探索数据,以及简单的可视化分析和结果展示;
(6) 数据服务:基于以上各子系统能力,提供满足若干场景的 SaaS 服务,比如数据归档备份、跨集群的数据传输,以及对外提供数据共享等;
(7) 权限中心:用于管理资源账号权限以及开发组权限;
(8) 系统管理:提供一些系统基础功能的管理;
面向业务,奇麟思考的是通过提供简单易用的一站式大数据处理的平台,降低使用门槛,简化大数据平台工作,帮助业务释放数据价值,赋能业务。
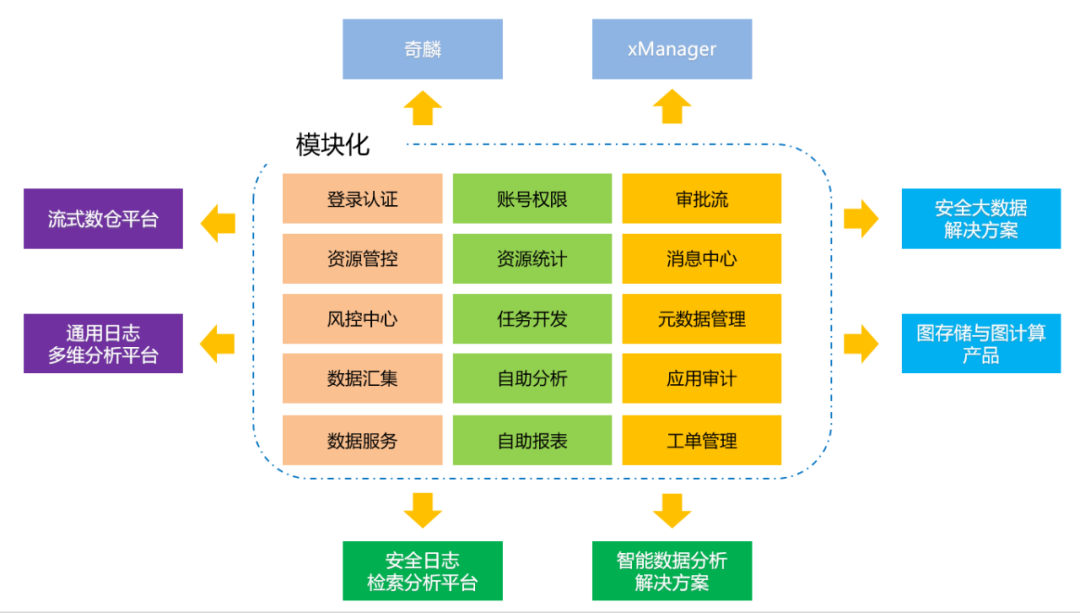
奇麟模块化视图
奇麟通过模块化设计,使得各个模块可以灵活组装和运行,针对不同的司内外业务场景,可以快速形成不同的大数据解决方案和产品。
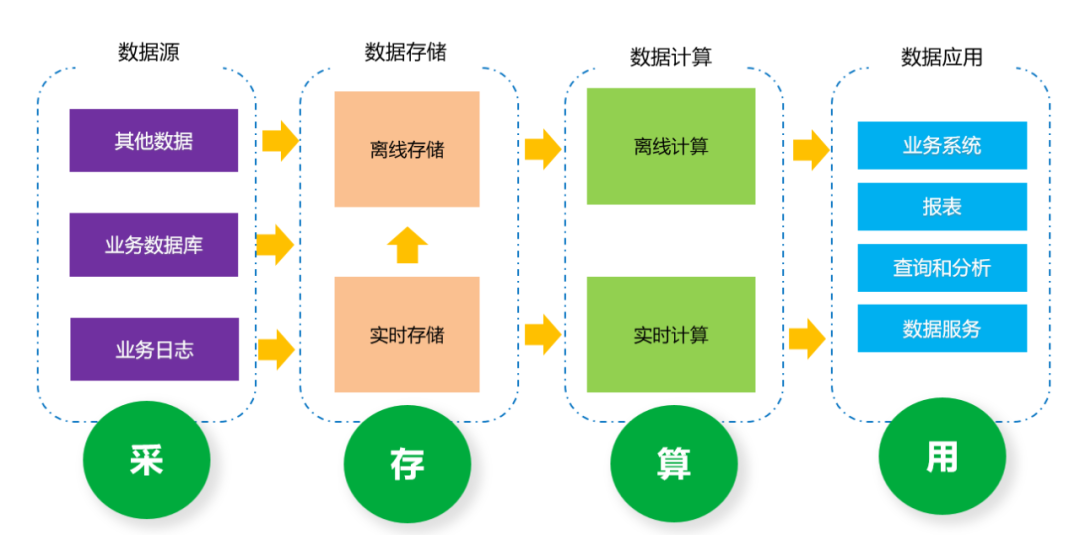
一个典型的大数据处理流程
接下来,本文将以一个典型的大数据处理流程为例,介绍如何通过奇麟来一站式完成。
奇麟资源账号
面向多租户,奇麟使用部门、资源组、项目账号对多租户进行存储、资源、权限的管理与隔离。
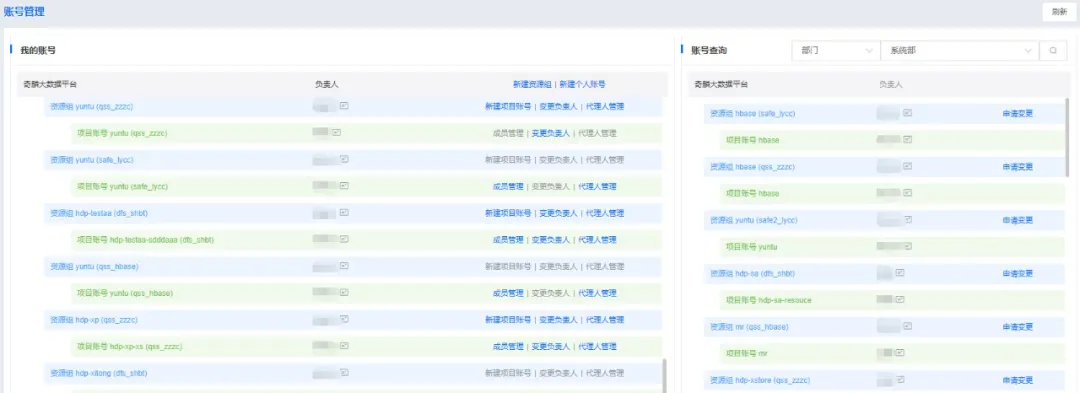
奇麟资源账号管理
使用奇麟平台,首先需要在权限中心à账号管理下,申请创建资源组和项目账号。
其中,资源组是对业务主题的定义/分类,项目账号用于访问大数据存储,提交大数据任务,对应操作系统中的一个真实账号。
大数据存储和计算资源的申请,成本的归属,均以项目账号来进行。一般不允许使用个人账号来使用大数据存储和计算资源。
奇麟资源管理
系统部管理和维护着各类大数据集群,并面向多租户提供服务,必须有一套资源管理系统来进行这些大数据资源的管理,否则运维管理成本是极高的。
资源管理模块可以对系统部提供的以下大数据资源进行申请:
(1) 存储资源:文件存储、表格存储、对象存储 HDFS/Hive/HBase/Cassandra
(2)计算资源:YARN 资源、容器资源
(3)消息总线资源:Kafka、QBus、NSQ
(4)多维分析资源:Druid、Doris
(5)索引系统资源:Poseidon、ElasticSearch
(6)服务资源:ScribeQ 、
(7)客户端资源:客户端部署、客户端账号
(8)资源预算和成本:预算申请、成本统计
用户需要使用大数据资源,需要到奇麟平台à资源管理模块进行资源申请,由运维管理员进行审批。
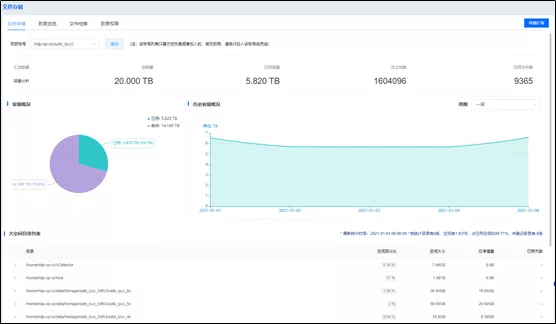
奇麟资源管理
奇麟资源管理模块,以项目账号为维度,展示了该项目账号下各类资源的使用情况,在资源不足时,可以进行资源扩容申请。
另外,各项目账号可以对自己资源中的权限进行管理,比如:HDFS 目录权限,Hive/HBase 表权限等。
注:
1.服务资源 ScribeQ:用来兼容历史上广泛使用的 scribe 数据采集,申请 ScribeQ 资源后, 在数据汇集系统可以将数据打入 scribe,进而落地到 HDFS 之上。
2.客户端资源:由于历史上采用客户端方式部署,导致客户端分散难以管理,未来会将公司内部客户端资源收敛,而后将客户端资源的模式关闭。
奇麟元数据管理
元数据管理旨在统一元数据视图,贯穿起数据开发的各个环节;同时具备开放能力,通过 API 支撑业务构建数据资产、数据管理等能力。
元数据管理通过将分散的数据资源信息进行描述、定位、检索、评估、分析,实现了数据资源信息的描述和分类的结构化,从而为数据任务开发、数据治理、数据资源分析提供了有效的依据。
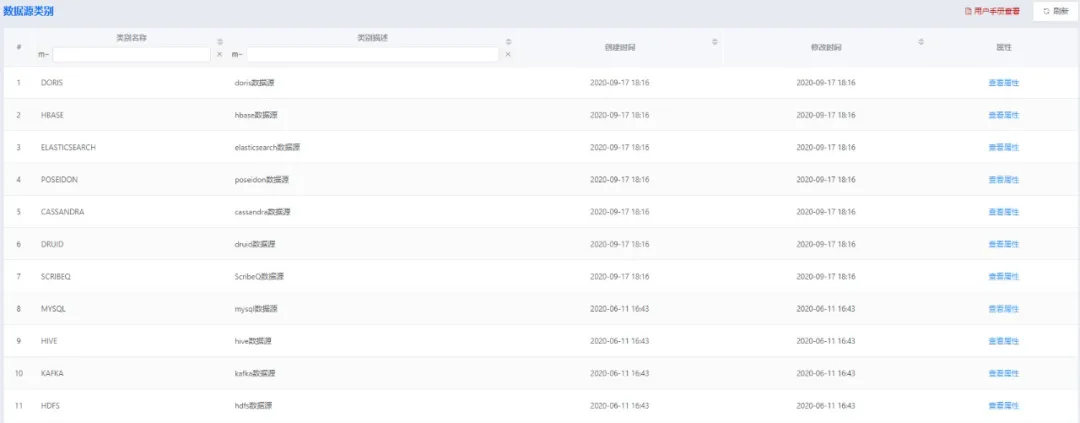
奇麟元数据管理
整个元数据管理从功能层面分为两层,一是数据源管理,二是元数据管理。数据源是指元数据管理平台所支持的元数据来源的方式。提供直连多种不同类型的数据源,目前包括:MySQL 数据库、Hive 数据库、Kafka、HDFS。元数据指各个数据源中具体的数据对象,比如表、Topic、HDFS 路径等。
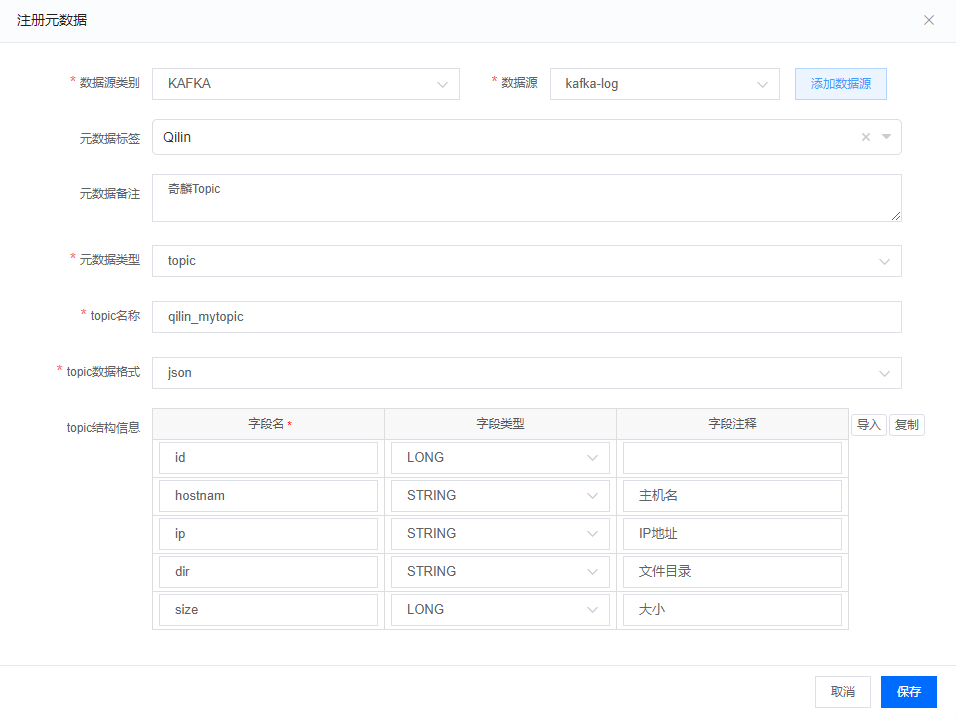
一个 Kafka Topic 元数据
奇麟数据汇集
奇麟提供的数据汇集模块 xCollector,主要用于业务日志及其他数据的实时采集。用户通过界面化的配置,即可完成对数据的实时采集,并展示监控实时速率。
目前支持文本文件、Kafka 等数据源类型的数据采集,通过总线流转,输出至 Kafka、HDFS、ElasticSearch 中,为上层提供数据支撑。
通过数据汇集,用户可以将自有的业务数据汇集到大数据平台中。
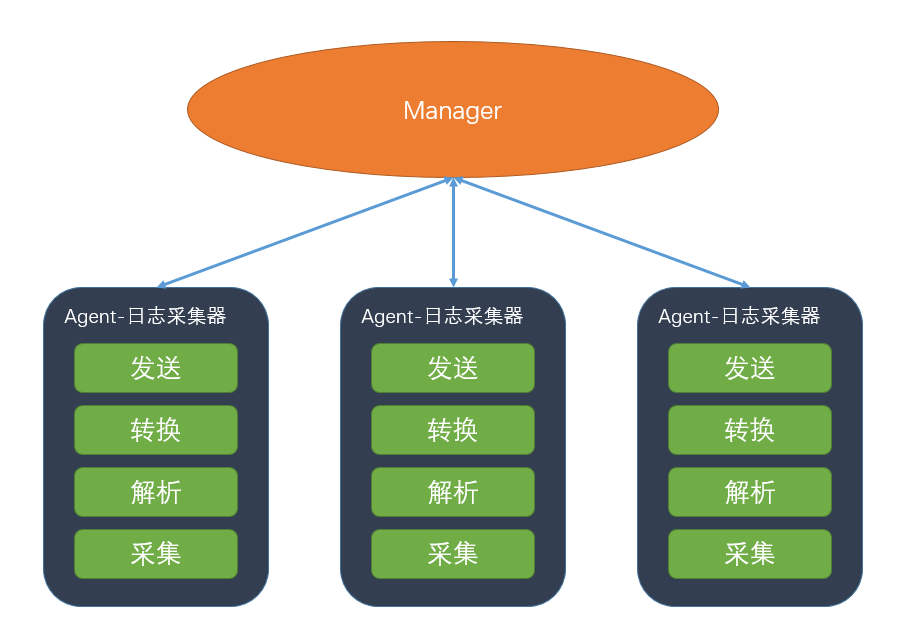
数据汇集架构图
数据汇集包含采集à解析à转换à发送四个步骤,均在采集端完成,在消耗资源较小的情况下,可以在采集端完成对数据的解析和转换(边缘计算),减小数据的传输量以及后续的计算量。
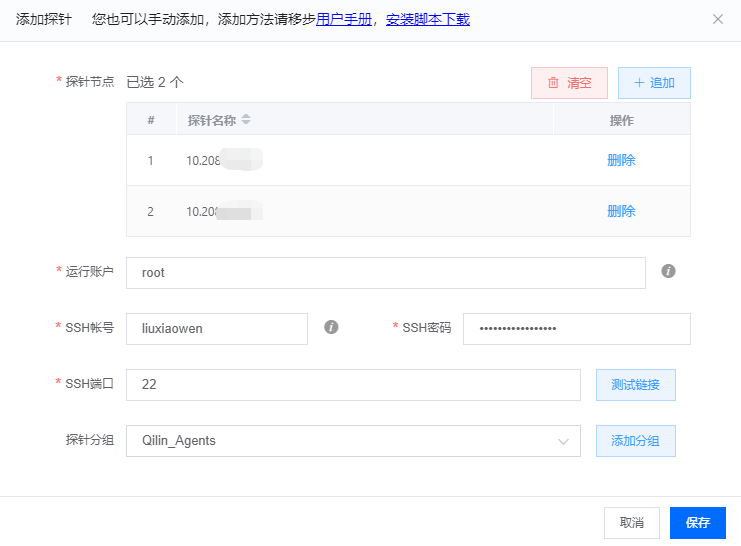
奇麟数据汇集-添加探针
使用数据汇集实时收集服务器上的日志,需要先在服务器上安装探针。可以在界面上通过输入 SSH 用户名密码来安装,也可以下载安装脚本,线下手动安装。
有了探针之后,可以在汇集任务页面创建任务,在画布中拖拽任务类型,通过配置即可完成。
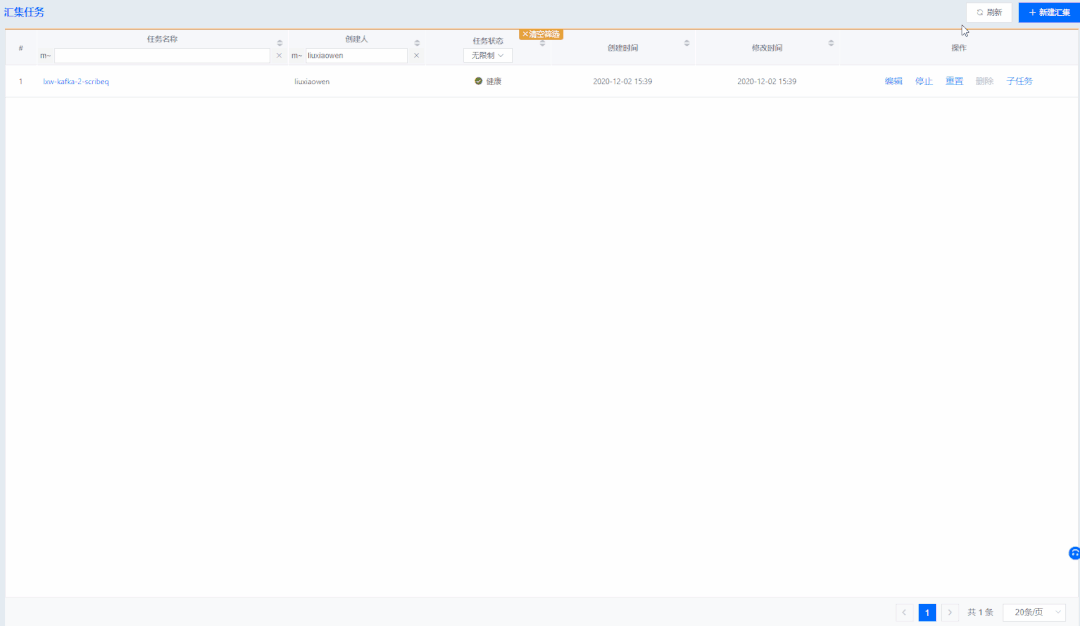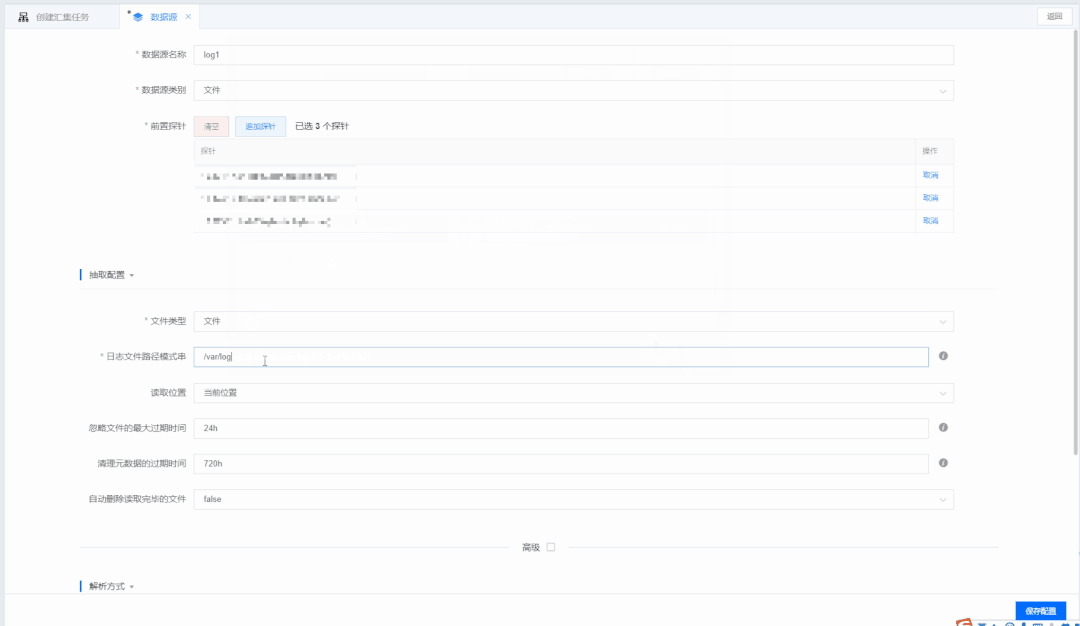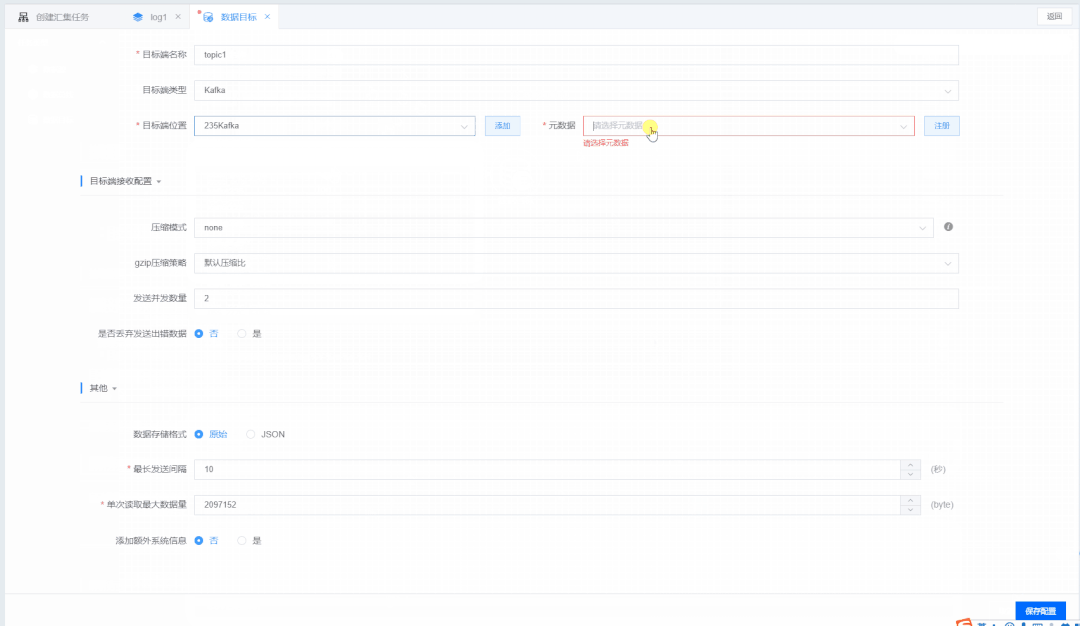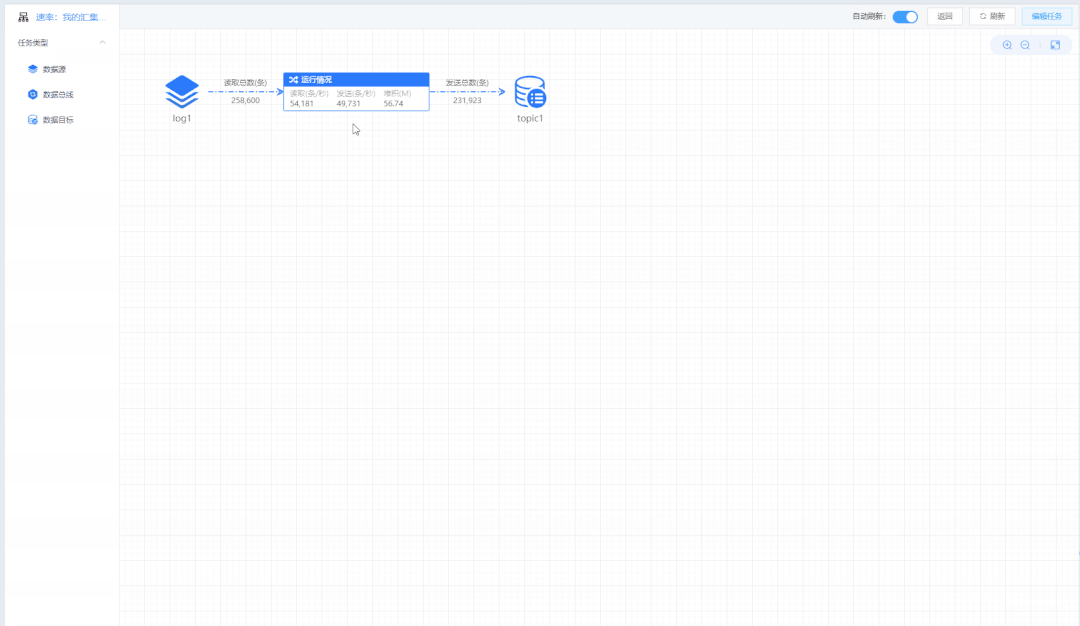
通过画布创建数据汇集任务
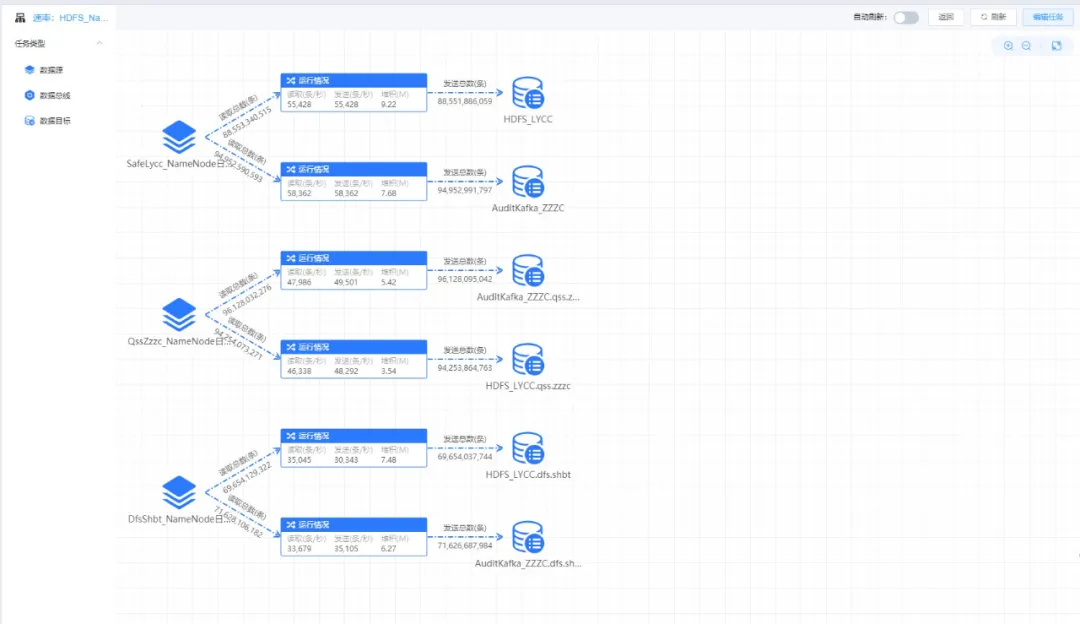
实时展示数据汇集任务速率
奇麟任务开发
奇麟任务开发平台提供多种编程形式,支持在线进行可视化的流程编排和代码编写,高效完成大数据离线计算和实时计算的核心业务开发,并对计算任务进行任务调度管理、运行情况监控和告警等在线运维管理。
通过任务开发平台,用户可以完成大数据的离线/实时处理任务。
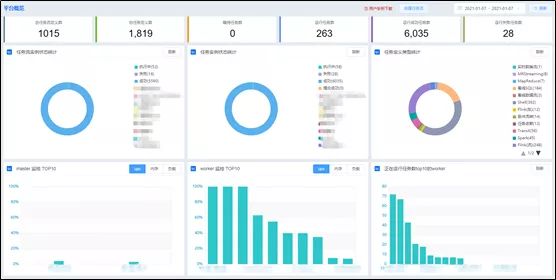
奇麟任务开发平台概览
奇麟任务开发平台支持以下任务类型:
• 基础任务:Shell、TransX、条件流转、任务依赖、数据检查;
• 离线计算:MapReduce、MRStreaming、Spark、Flink(批)、离线 SQL;
• 实时计算:Flink(流)、FlinkSQL(流);
• 开放 API:与其他业务系统对接数据处理流程;
用户可以在任务开发平台中通过拖拽、配置以及简单的开发,完成业务数据处理流程。
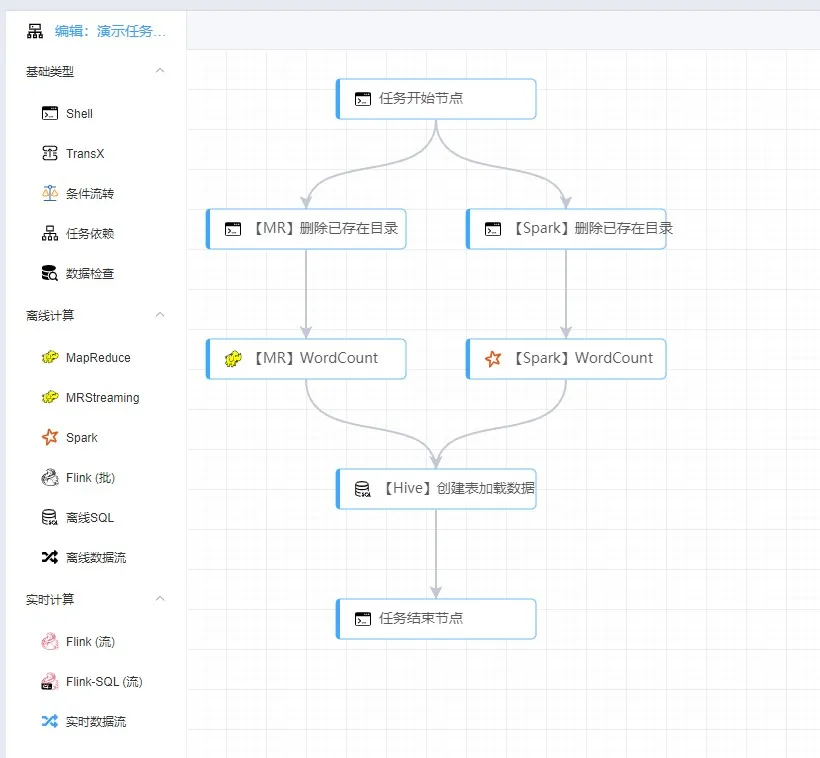
奇麟任务开发平台任务流
可以为每个任务流设置定时运行策略。
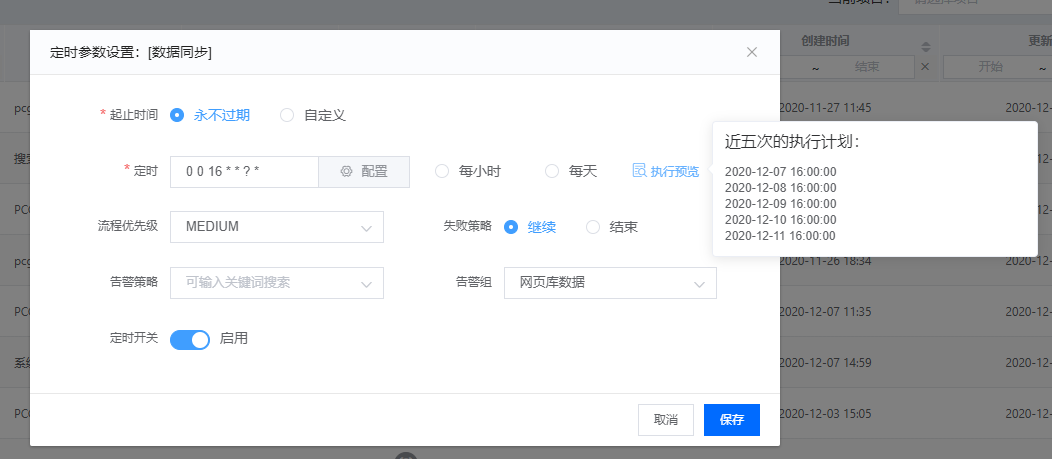
奇麟任务开发平台定时调度
查看每次运行实例的记录,包括运行状态、开始/结束时间、耗时、运行时长、运行主机、日志等。
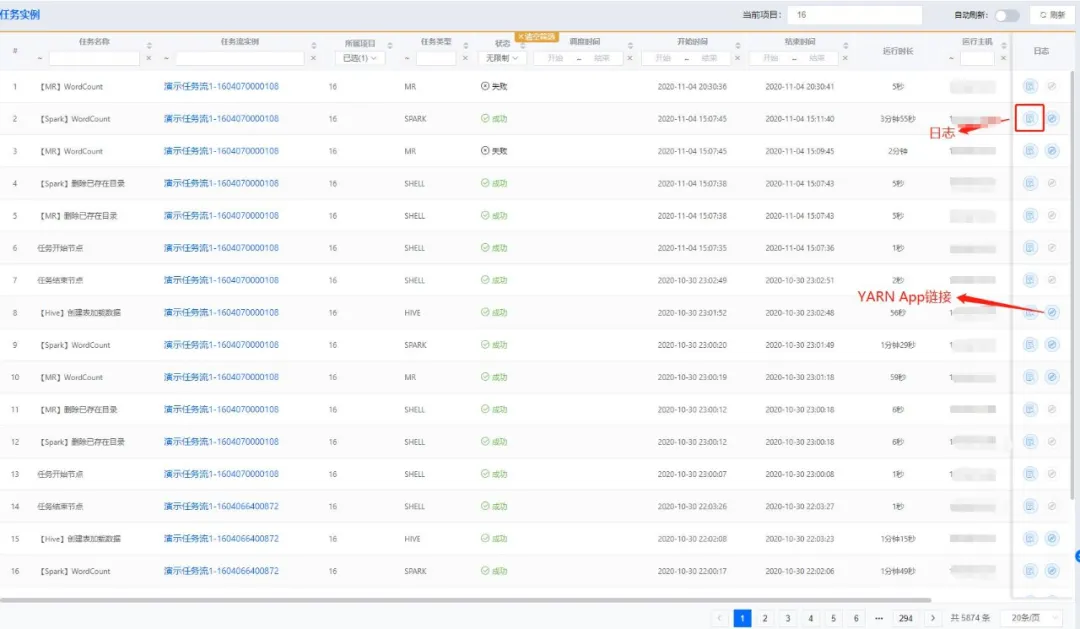
奇麟任务开发平台任务运行记录
奇麟任务开发平台同时提供了开放 API,可以与业务系统集成,完成一些异步的数据处理流程。
奇麟交互查询
交互查询,是奇麟提供的用于快速查询探索各类数据源的功能模块,其底层使用系统部最新自主研发的跨数据源分布式统一查询 SQL 引擎 ---- BigSQL 。通过交互查询,用户可以很方便的查询/探索已有数据。(BigSQL 的架构和实现,会在后续的文章中详细介绍)
交互查询支持的数据源包括:Hive、MySQL、Druid、ElasticSearch、HBase 等,未来会覆盖奇麟资源管理菜单中所有的存储资源。
交互查询支持跨数据源进行查询,比如:MySQL 表关联 Hive 表。
查询引擎包括 JDBC、Spark、Hive、Presto,系统默认根据规则自动选择执行引擎;用户也可以自己选择执行引擎;
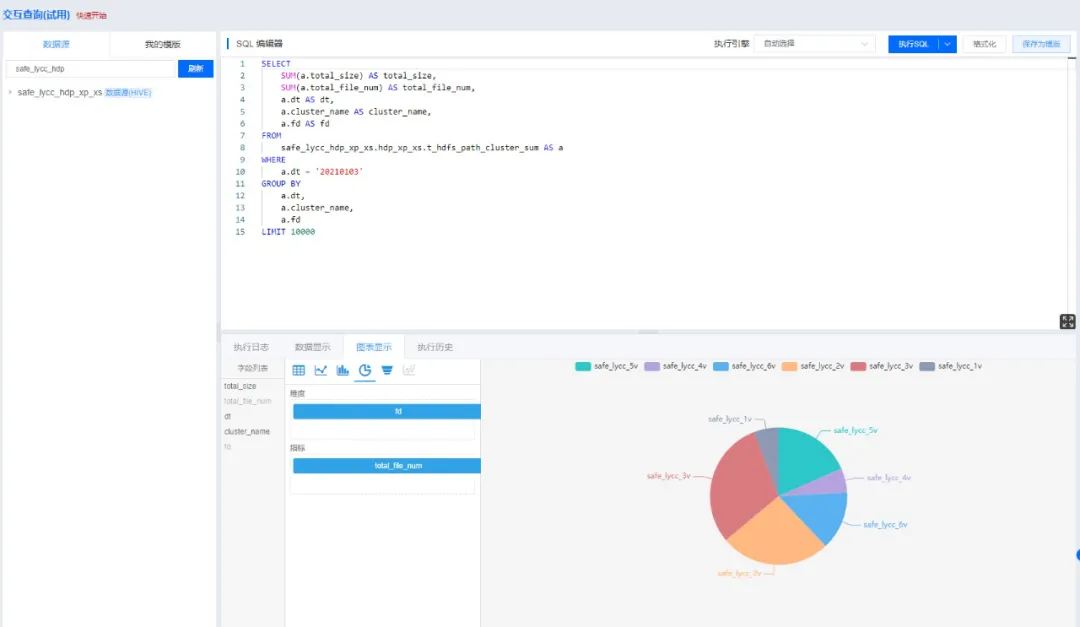
奇麟交互查询
查询结果可以下载和简单的图形化分析。对于一些常用的查询,可以保存或者创建查询模板,下次直接使用。
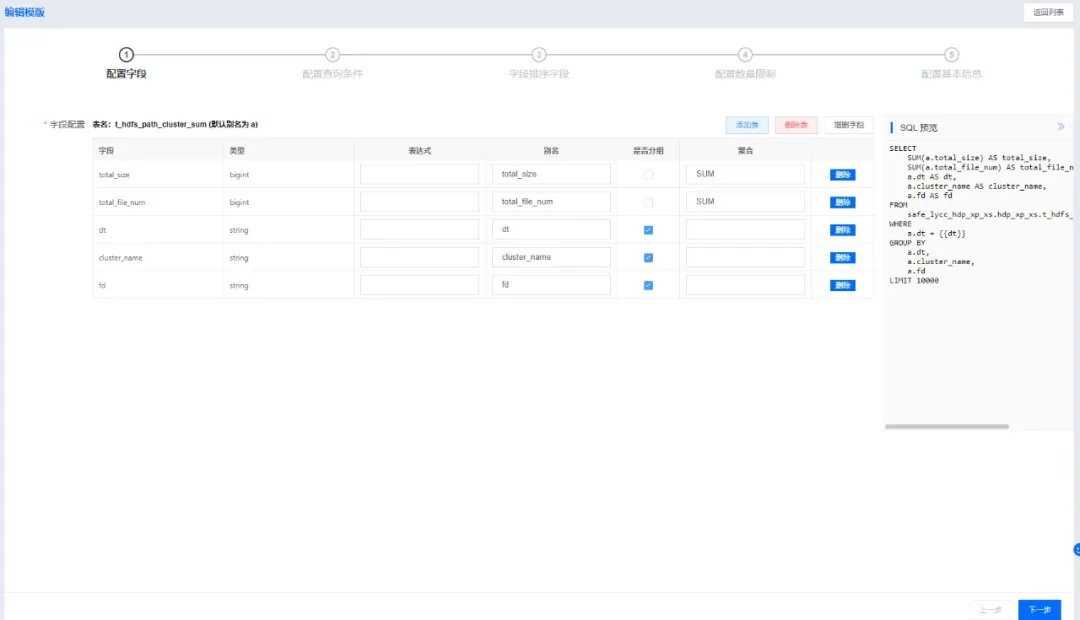
奇麟交互查询模板
奇麟自助分析
自助分析是交互式查询的自然延伸。是奇麟基于开源组件,提供的用于多维分析/报表的轻量级、简单的可视化工具,提供初级的数据可视化功能。用户可以基于已有的表/SQL,构建维度分析模型,从而在页面上通过拖拽和配置,即可进行可视化分析,对分析结果可以保存成报表及仪表盘。
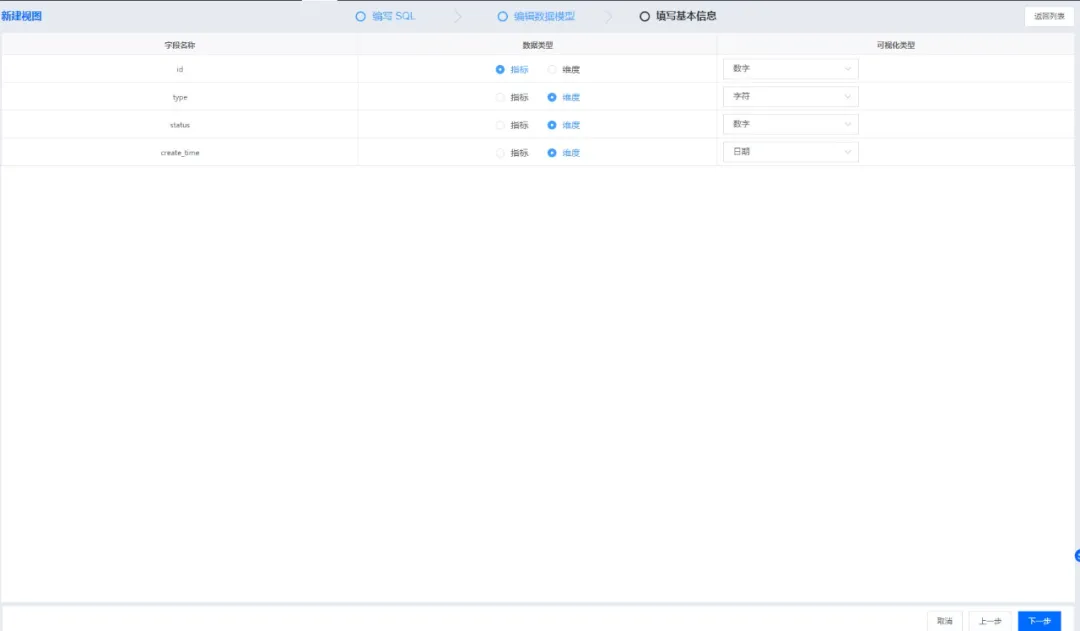
奇麟自助分析-创建分析模型
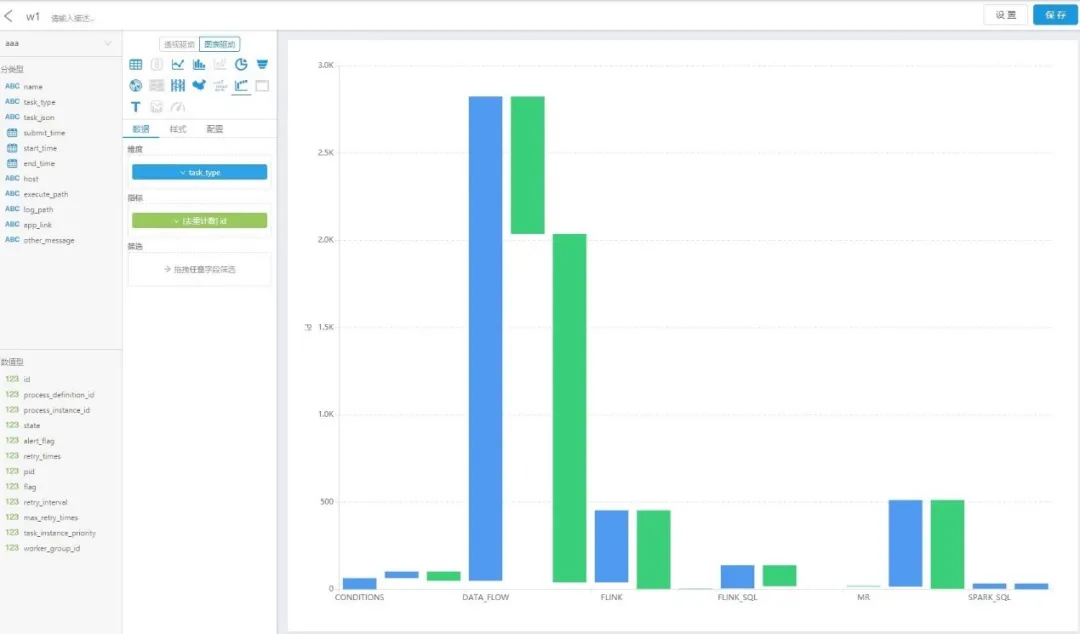
奇麟自助分析-可视化分析报表
对于保存好的报表和仪表盘,可以通过分享链接集成到其他系统中。
奇麟未来规划
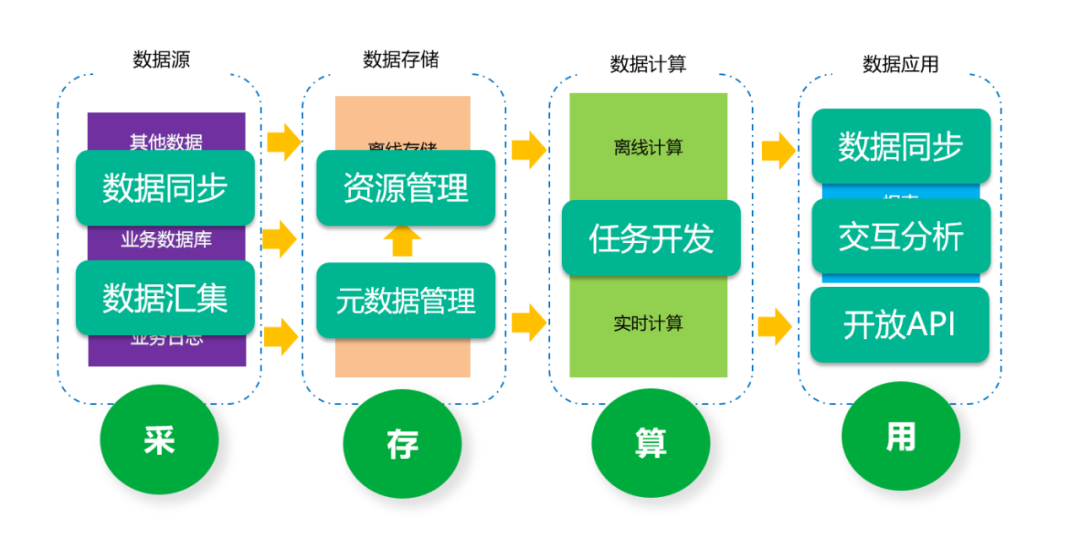
通过奇麟平台完成典型数据处理流程
目前,奇麟平台基本具备了整个大数据开发和数据处理流程的能力,对于后续规划,我们将:
(1) 能力持续增强:元数据管理、任务开发、数据汇集、交互分析能力继续优化和增强。
(2) 开放更多 API,支撑上层数据治理,与业务共建数据平台/产品/服务;
(3) 依据司内业务场景需求,提供更多大数据资源管理和服务能力;
(4) 沉淀通用解决方案:对外项目中提供大数据相关的平台解决方案;
(5) 融入容器云管理, 提供云化弹性的大数据平台能力;
写在最后
奇麟 1.0 从立项开发到目前的现状,只有短短的 6 个多月的时间,。系统部基于多年的大数据系统资源管理和分布式平台优化和定制化开发的经验,对大数据分布式组件进行封装, 提供一站式 Kernel-Lib-Interface 的大数据操作系统和开发平台。围绕着元数据管理,覆盖了大数据的开发链条中的数据采集、存储、计算、调度以及简单的数据可视化能力。我们会长期投入聚焦大数据平台的产品化和服务化,提供通用的 API,简化大数据业务逻辑、支撑上层数据治理平台的开发构建。
文章转载自: 360 技术(ID:qihoo_tech)
原文链接:360一站式大数据资源管理与开发平台详解




