
WHAT:云原生是什么? 它有啥前世今生?
简单说,云原生(Cloud Native)是在云上构建和运行系统的方法论。最早移植上云的“非原住民”应用程序,往往还沿用私有化部署的技术架构,无法充分发挥云基础设施的优势。随着客户应用的深入,系统必须按照 IaaS 和 PaaS 的原理进行重构,以便跟上业务的爆炸性增长。
按照 CNCF(Cloud Native Computing Foudation)定义,云原生一般包含 CI/CD(持续集成持续交付)、容器化、微服务、存储计算分离、跨云多域、元数据管理等技术要素。
图源:CNCF
老实讲,从我这种从业 20 年数据技术老兵看来,这又是一波 buzzword,很多东西二十年前就有了,十几年前就已经成为互联网技术团队的标配。例如,2007 年 Google 已向 Linux 内核社区贡献 cgroup 补丁;再如,2008 年腾讯阿里招收计算机专业的应届生的面试题里就有 CI/CD 的问题;2013 年我在阿里云 ODPS 团队时,ODPS 的调度器和执行器已加上了 cgroup 能力;6 年前我第一次创业,凭借 docker 容器化这个特点拿到了天使轮。

WHY:投资人不傻,为什么这些概念在创投领域突然变火?
云原生暗合当前行业的发展逻辑,才会受“追捧”。我猜所有重要的创新都要被“发明”两次,一次是从无到有生出来,一次是出圈。
最近业界有个新闻,2020 年,中国 IT 预算里超过 50%的钱花在了云上。这是一个里程碑时刻,在中国这个喜欢私有化部署的市场里,云终于赢了。
大量的应用在云上,就遇到成本和效率的问题。举 2 个例子:第一个例子,云和大数据运维技术含量较高,很多看机房重启机器的传统运维工程师无力承担。但是线上数据、计算和应用规模还在以每年 N 倍的速度增长。如果不采用 CI/CD 而是坚持传统的人肉运维,先别说这种运维工程师的薪酬很高,你可能都招不到这么多合适的人。第二个例子,客户如果把 Hadoop 不加修改直接部署到 ECS 节点上,数据通过 HDFS 存在云磁盘上成本会非常昂贵。客户必须修改 HDFS 底层,把数据存到对象存储上去。
成本和效率问题推动智能数据平台必须走向云原生,从而为用户带来如下收益:
1、提高研发效率
通过微服务、CI/CD、对象体系、DevOps 等一系列技术,提高代码开发、测试、发布效率,降低迭代成本。
2、 降低运维成本
同样,上面这些技术也可以实现开发及运维高效协同,有效提升对故障的响应速度,实现持续集成和交付,使得快速部署应用成为业务流程和企业竞争力的重要组成部分。
3、降低存算成本
大数据基础设施的存储计算成本惊人。存算分离和容器化能够更高效地使用 IaaS 资源,降低存储成本。存储和计算节点分离后,可以在不对存储进行扩容的情况下快速增加计算资源。另一方面,单个容器的启动时间更快,占用空间更小,而且可以根据实际应用的大小来弹性分配资源,无需额外采购服务器。
4、提高治理效率
数据治理是非常重要但“脏”且繁琐的工作。使用跨云治理、元数据管理等技术,会大幅度提高企业积累数据资产的效率,降低安全风险,提高供应商的多样化。
WHO:所有人都在阐释云原生,哪个更符合客户诉求?到底是“谁的云原生”?
讨论云原生时,应该问清楚:“谁的云原生?”
AWS、阿里云、微软云、腾讯云、华为云、京东云、Google 云……每一家都推出了自己云原生技术,以吸引客户搬上自己的云。但技术接口的中立性和跨平台性被有意无意忽略了。
奇点云主张建立 AI 驱动的数据中台,服务于泛零售、金融、电信等行业,其中不乏各行业的头部企业。所以我们有动力做下面两件事:
尽可能优化架构,降低数据应用在 IaaS 上的计算、存储成本。
实现跨云数据治理,帮助客户摆脱某个特定云平台的绑定。总而言之,和客户站在一起。
你会发现,在美国,尽管 AWS 的产品非常强大,但是 snowflake 和 databricks 依旧服务了很多世界五百强企业。原因就是这些头部企业需要把自己的 IaaS 供应商多样化。逻辑很类似。
所以奇点云的云原生,相比常规定义,多强调了几个因素:对象体系、跨平台、自主可控。我们的产品支持 AWS、阿里云、微软云、腾讯云、华为云、京东云、Google 云,并实现跨云的多 workspace 管理,能实现客户数据与应用的跨云治理和迁移。而且系统基本的架构体系设计更开放、更安全、更容易集成。
HOW:对于云原生,数据领域有什么倾向?具体通过哪些技术要素实现云原生?
我们先回顾一下数据技术的演进阶段:
阶段 1
关系性数据库出现,SQL 统一数据开发工业标准,开始区分 OLTP 和 OLAP。**问题:**随着业务成长,数据量爆炸,尤其是互联网影响的深入,传统关系型数据库逐渐扛不住海量数据的压力。
阶段 2
大数据技术出现,支撑海量数据的处理,OLAP 本身又被分成了离线和实时。**问题:**针对不同场景的各种大数据引擎不断出现,反过来又刺激了更多数据的生成。海量数据的成本开始变成沉重的负担,如果不能把数据变成“资产”,帮助业务赚钱或省钱,就没法持续支撑大数据基础设施的持续投入。
阶段 3
数据中台出现,提出一系列的业务方法论,强调积累数据资产。**问题:**数据中台在互联网公司的实践获得了相当大的成功。但是在其他行业,如果纯粹 100%生硬照搬互联网的业务架构和产品形态,会遇到很多水土不服。举个例子,传统行业的企业有大量的线下场景,需要考虑很多数据集成、跨平台治理、数据安全、自主可控的问题。
阶段 4
数据智能深入场景,AI 成为数据中台的入口和出口,业务和数据上云趋势加快,多域数据治理成为刚需,国内用户愿意为自主可控技术买单。 你可以看到,每一阶段技术都是为了解决上一代问题诞生的。 所以,大数据领域的业务特点会推导对云原生的一些倾向性:
1. 数据中台存储海量数据,且作业高吞吐高并发,对存算分离的各项指标要求明显高于其他领域的应用;
2. 大数据集群规模大进程多,天然需要微服务治理和其他智能运维技术;
3. 客户对数据安全、数据确权极其关注,加上 toB 的分级多域数据治理场景非常复杂,产生了对跨平台技术、数据安全技术、合规数据合作技术的强烈需求;
4. 由于目前的国际政经形势,自主可控的大数据引擎,对国内企业而言是一个刚需。 想清楚了这些,“奇点云的云原生”具体做了如下的研发:
容器化编排 :容器化本质上是一种虚拟化技术,一台主机可虚拟出上千个容器。单个容器的启动时间更快,占用空间更小,而且可以根据实际应用的大小来弹性分配资源,无需额外采购服务器,加快研发速度。
对象体系:根据现有业务抽象出核心对象,以标准 RESTful 风格提供 API 服务,解耦核心对象与业务层服务,以应对不同环境、不同业务场景的需求。这一系列正交的核心对象就构成了平台对象体系,上层业务可在此基础上构建应用,高效演进。

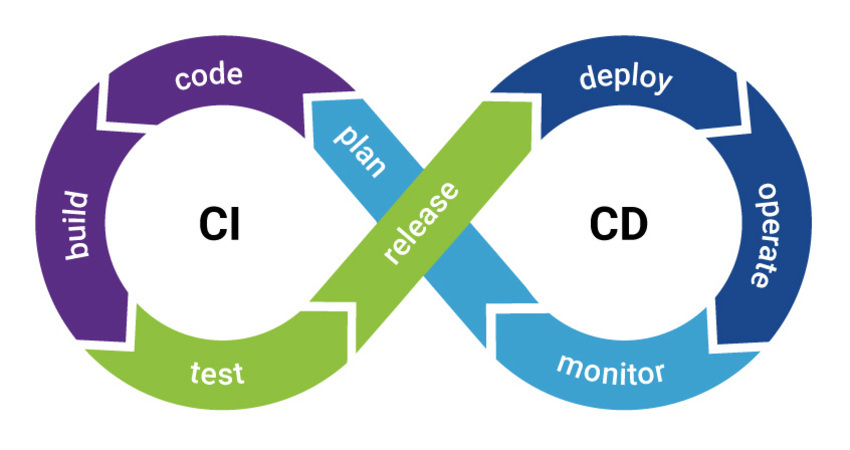
CI/CD :通过版本管理系统和 DevOps 基础设施,实现自动化测试和持续集成。一个典型流程是,程序员提交代码到特定的 tag,触发测试接口自动化测试脚本+开发单测脚本(偏提交代码新功能的)执行并发送报告。由此实现测试、发布和部署自动化。在此基础上构建特定的数据环境,对重要接口和链路进行自动化检测。
存算分离 :如果把 Hadoop、Spark 等常规开源大数据引擎直接应用于云主机,海量数据带来的存储成本和吞吐压力,会很快“压垮”客户。因此,必须引入中间缓存实现计算存储分离,将数据存储到对象存储上,同时兼容 HDFS 协议,能够根据业务需求进行弹性扩容,就能大幅度降低成本,提高集群性能。

跨云治理 :在 AWS、阿里云、华为云、腾讯云、京东云等平台,实现统一账号、权限和审计的多 workspace 的兼容管理,并进一步提供数据安全和可信计算方案,从而提高基础设施的可控性和安全性。
元数据管理 :对数据的结构、指标、标签、权限、上下游血缘、生产作业等元信息进行规范化管理,建立智能数据治理体系,支持数据盘点、安全审计、血缘分析、关键分级等应用,最终实现数据资产化。
WHERE:客户在哪些场景用上了云原生数据中台?
简单举几个客户应用我们的云原生数据中台 DataSimba 的例子吧(均为真实案例,保密原因,不能指明):
案例 1
某互联网 APP,在海内外都很受欢迎。由于地域和法规的要求,他们必须在多个国家的多种 IaaS 上实现数据生产和合规隔离,例如:在印度部署 1 个 workspace 在孟买 AWS 上,在美国部署 1 个 workspace 在 Oracle 云上,在中国部署 1 个 workspace 在阿里云上……同时又实现账号权限、数据审计和安全策略的全局管理。
案例 2
某大型电子设备制造公司,由于战略和业务的原因,必须把自己 IaaS 供应商多样化:部署 1 个 workspace 在华为云上,以便对接政企系统;部署 1 个 workspace 在 AWS 上,以便满足海外客户的审计需求;再部署 1 个 workspace 在阿里云上,以便支持和阿里云的战略合作……同时又要进行全局的数据资产管理。
案例 3
某大型零售品牌集团,本身就有多个互相竞争的子品牌,彼此要求数据做必要隔离和客户隐私保护,同时总部又要进行全面的数据拉通。另一方面,该品牌商会对接多个流量电商平台:在阿里云放一个 workspace 支持双 11,在京东云放一个 workspace 支持 618。再加上几十个线上线下系统的数据的集成和拉通,形成了很复杂的分级多 workspace 的云原生数据治理体系。
案例 4
某流通业的大型集团,各个分公司比较独立,IT 经费充足。这时候总部上一个分级数据治理的多 workspace 数据中台,旗下比较大的分公司有自己独立机房的可以单独部署 workspace,而小一些的公司在阿里云或华为云上开通 workspace。总部对所有 workspace 拥有账号管理和审计的权利,同时控制住数据建模规范标准和指标的版本发布。
不同行业的不同企业,搭建出不一样的云原生跨平台数据治理体系,这其中的业务逻辑复杂微妙。我们再对比一下互联网大厂的数据平台——大一统式的数据打通,跑在几千台节点集群上,就可以发现两边产品上的着眼点并不相同。
作者介绍
地雷,奇点云高级技术专家,奇点云数据智能平台 DataSimba 总负责人,阿里大数据底层核心引擎 ODPS 初代产品经理。曾支持蚂蚁金服、菜鸟等算法与应用建设。




