
语音助手是大模型最佳的落地场景之一,可以将语音助手看作是一个现成的智能体。如何为大模型定义语音助手业务,如何为语音助手场景定制优化模型,是我们需要解决的重点问题。在效果提升的同时,如何平衡成本与性能也成为是否可以大规模扩展的关键问题。
在不久前举办的 AICon 全球人工智能开发与应用大会上小米小爱高级算法工程师杞坚玮为我们带来了精彩专题演讲“小爱同学大模型在业务应用中的升级之路”,演讲分享将逐一介绍小爱同学在这些问题上的工作与尝试。
内容亮点:
了解大模型在实际应用中的困难与可行解决方案;
了解语音助手场景下对大模型的特殊要求;
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
智能语音助手的变革
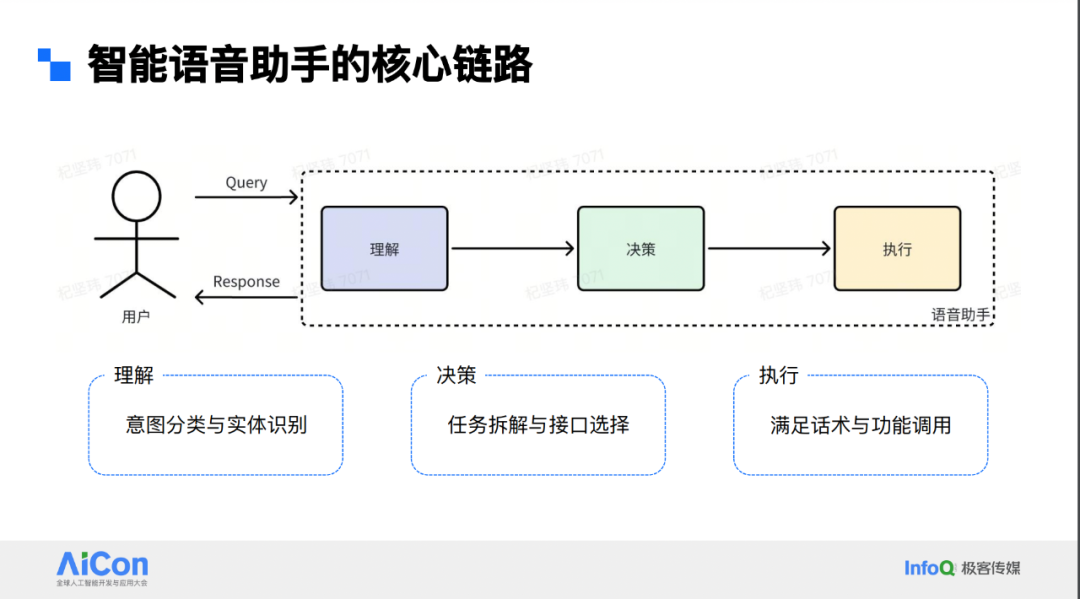
智能语音助手的核心链路
智能语音助手是 ARP 领域一个相对传统的存在。早期像 Alexa、谷歌的 Siri 等都属于传统语音助手。从技术模块来看,语音助手可拆解为理解、决策和执行三个步骤。在理解阶段,主要是进行意图分类和实体识别,比如用户问“武汉今天的天气”,我们要识别出用户在询问天气,且询问的是武汉今天的天气情况。
有了意图识别结果后,进入决策阶段,依据结果确定调用何种接口,如小爱内部可能调用某三方 API 获取天气信息,需选好接口并填入相应参数。到了执行阶段,调用接口获取返回信息后,如北京现在的温度、是否下雨等,再生成话术作为 response 返回给用户,这就是常见语音助手的工作链路。
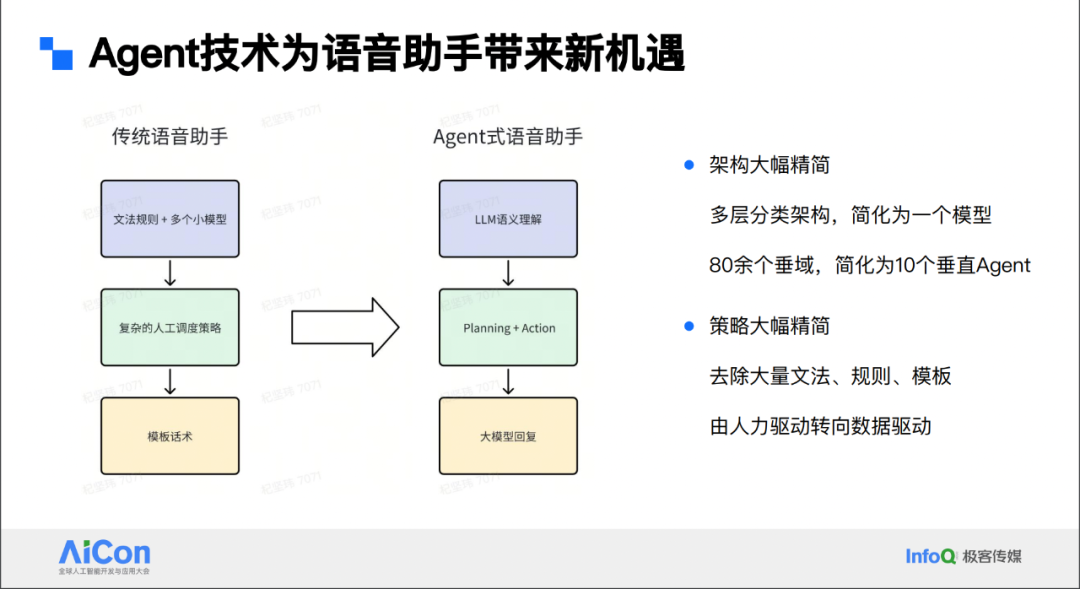
Agent 技术为语音助手带来新机遇
在这个过程中,Agent 主要在两个方面发挥作用,即架构和策略上的大幅精简。先说架构上的精简,之前整个链路中各模块能力有限,需通过多层级分类架构将用户 query 准确分到特定意图,或借助诸多先验后置规则确定实体。如今借助大模型进行语义理解,可简化为一个模型完成意图理解。
再看策略上的精简,过去为满足能力不足,需写上百条正则匹配各类场景,如今大模型能较好解决这些问题,且从人力驱动向数据驱动转变。Agent 技术为语音助手带来了新的机遇,通过大幅精简架构和策略,使架构更简洁,策略更高效,推动语音助手技术发展。
Agent 技术在小爱中的成功实践
我们在小爱中实践相关技术面临四个方面的挑战。
首先是语义理解,它本质上是一个传统的判别任务,而大模型是生成式任务,Agent 中还涉及 planning 问题,如何将它们有效结合是一大挑战。
其次,小爱主打人车家全生态,拥有众多 API,包括上百种功能的一方和三方 API,如何让 Agent 掌握如此多的 Tool Use 是个问题。
再者,Agent 的一大亮点是能与环境协同成长,小爱有 1 亿日活的庞大用户体量,如何利用这些数据助力小爱持续成长也是关键。
最后,作为面向消费者的商业应用,用户对小爱的时延较为敏感,如何保持较高响应速度至关重要。接下来,我们会分四块详细介绍这些内容。
语义理解与 Planning 能力的结合
传统语义理解范式是意图理解加槽位抽取,存在局限性。其类别和槽位都是人工预设的,难以应对用户长尾问题,当有新需求时,需产品梳理后设计新意图。且这种一级意图分类及槽位范式,不利于模型推理复杂逻辑关系。
为解决此问题,我们采用代码式语义表示,将语义理解任务转化为 query to code 任务,用类似 Python 代码形式翻译用户需求。比如“打开后排座椅加热”这一常见需求,传统是意图槽位范式,转为代码语义后,就变成 function calling 过程。
这样做的好处有:一是发挥大模型推理优势,我们只定义简单原子能力,如“打开”用 open 表示,实体如“后排座椅”用 device 表示等;二是大模型输出代码是其擅长领域,其预训练数据中约 1/5 是代码领域数据,能很好结合大模型能力。
再看规划方面,仅通过一个例子难以看出规划过程,我们可以参考下图这个更复杂例子。我们定义查天气和定闹钟两个 function,有实体约束和函数注释,便于后续校验大模型输出代码,及数据增广、标注时指引。当用户 query 是“明天早上 8 点叫我起床,告诉我会不会下雨”,融合了两种意图。大模型理解后,能将两个 function 结合,构成完整代码表述过程,发挥大模型 planning 能力,解决产品未想到的用户需求。只要告诉模型小爱具备原子能力,它就能自由组合衍生新表示方法。这就是语义理解与大模型 planning 能力结合的过程。

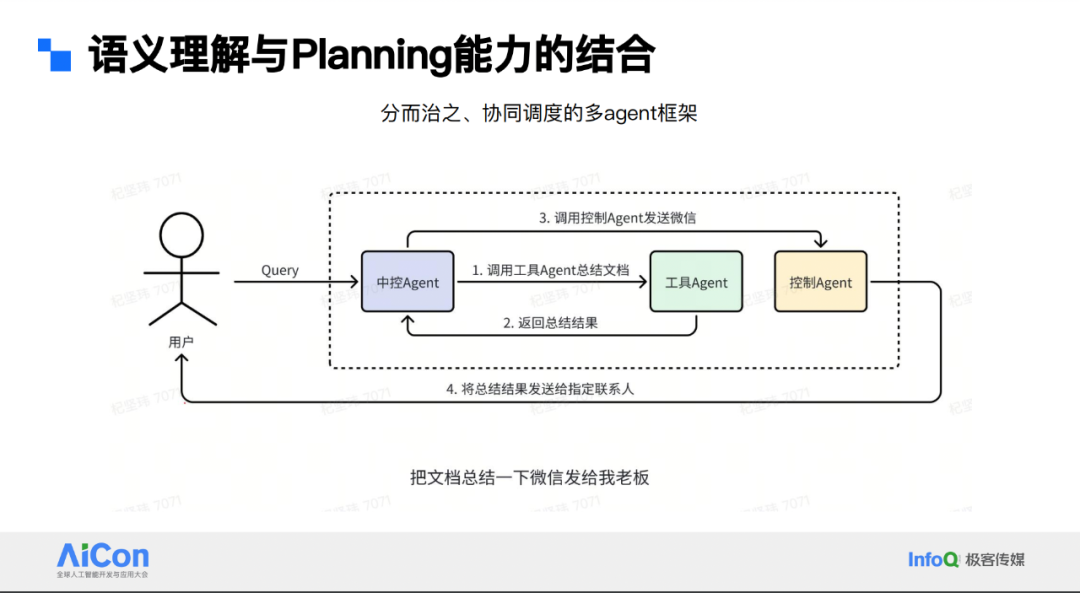
我们有十个垂直的 Agent,每个 Agent 负责其领域内的一系列过程。例如,工具 Agent 负责总结文档、定闹钟等,控制 Agent 负责手机 APP 操控,内容 Agent 负责内容播放等。在实际应用中,会遇到跨垂域调度的问题。对此,我们采取分而制之协同调度的思路。
具体来说,有一个中控 Agent,它不直接看到众多原子能力,而是知晓每个 Agent 最擅长及能做的事。中控 Agent 负责调度垂直 Agent。比如,对于“把这篇文档总结一下,微信发给我老板”这样的 query,中控 Agent 先让工具 Agent 总结文档,工具 Agent 返回结果后,再注入到控制 Agent 的微信发送流程中,从而完成跨 Agent 协作流程。
提升 Agent 在垂直场景中的表现
要提升 agent 在垂直场景中的表现,虽已定义众多 API 接口的原子能力,但大模型难以平滑适应多任务。常见问题有:一是归一化错误,大模型具通识性,在业务叫法对齐不足时,易将省电模式误归为低电量模式;二是长尾表达理解不清,如“屏幕上的字这么小怎么看得清”,本意调大字,却因“小”字理解成字体调小;三是业务实体与功能熟悉度不够,像小爱多种音色,用户想换深沉音色,却不知对应的音色名“星河”,希望大模型能精准预测;四是业务功能中独有的小众词汇,如小爱的抽屉模式,涉及应用管理,需大模型适应这些特殊场景,解决相应问题。
大模型优化链路相对类似,主要靠持续预训练加精细化微调。从技术角度看并无特别新内容,因大模型本质是 Decoder Only 架构,任务是预测下一个 token。我们从预训练和近期微调两板块入手。首先是持续预训练,小爱作为业务团队,难以从零训练基座模型。我们会依据评估指标,如知识、代码、推理能力等,从业界及公司内部基座模型中选出最佳版本,作为底座模型进行领域能力持续训练。这主要解决像“星河”代表深沉音色、抽屉模式管理应用等知识信息问题。
持续训练用到三种数据来源:一是线上小爱日志挖掘的领域信息;二是内部积累的业务知识,如手机上控制项的目录层级等小米内部知识;三是业界开源语料,但我们会做相关性召回,筛选与小爱支持功能相关部分,而非全盘接收。拿到数据后,做质量配比实验,确认领域内数据最佳占比,并通过 scaling Law 实验,确定不同模型尺寸和数据量下的数据占比,进而开始模型训练,得到小爱基座模型,供各 Agent 在此基础上做持续预训练。
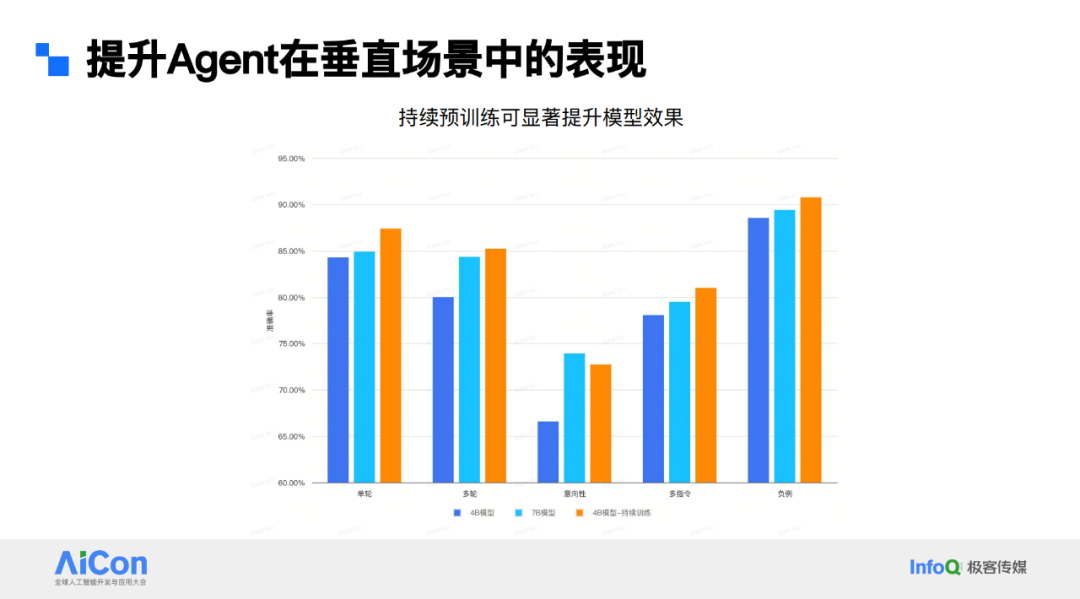
下图展示了之前某一版持续预训练的效果。在语音助手场景中,因性能要求严苛,所用模型参数不会过大。最初线上使用的是 6~7B 尺寸的模型。为适应公司战略节奏,推广大模型,我们压缩模型尺寸至 4B。从图表看,4B 模型起初与 7B 模型有明显差距。通过持续预训练,4B 模型在多场景上可媲美 7B 模型。
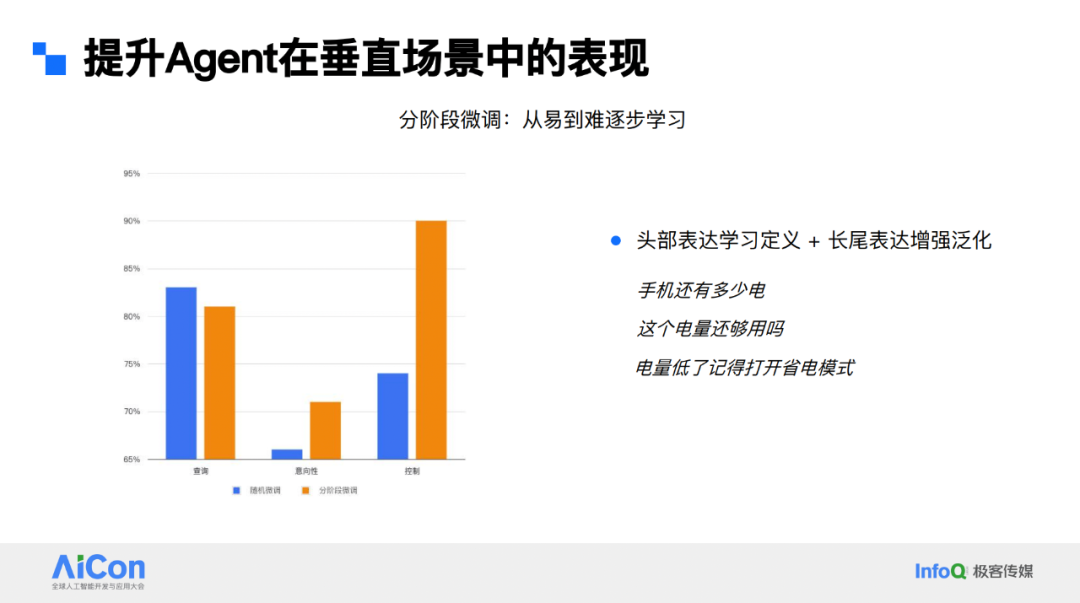
在小爱场景下,主要分享分阶段微调。小爱 query 分布中,有大量头部表达及中长尾表达,若将这些数据混合给模型学习,效果不佳。我们采用分阶段微调,先让模型学习头部表达及相关 function 定义,打好基础后,再提高后续 batch 中采样长尾表达的概率。这种分阶段微调使模型逐步掌握定义功能,从图表看,在各评测集上分阶段微调有较大提升。
Agent 在与用户交互中成长
小爱作为语音助手能获取大量用户反馈。显式反馈如用户点赞、点踩、投诉或提交官方反馈,但这种方式量级较小,并非所有用户都有热情助力完善。我们更多采用的是隐式反馈,需借助先验信息挖掘。
比如用户打断小爱播报,说明回复很可能不符合用户预期;更极端的是用户听完部分播报后骂小爱蠢;在内容垂域,如用户让小爱放歌,刚播开头就中断,表明歌曲可能非用户所想。基于这些特征,我们建立负反馈挖掘逻辑,借助大模型辅助判断哪些反馈真实且需关注,尤其是与理解问题强相关的反馈,据此构建 case 助力语音助手提升。
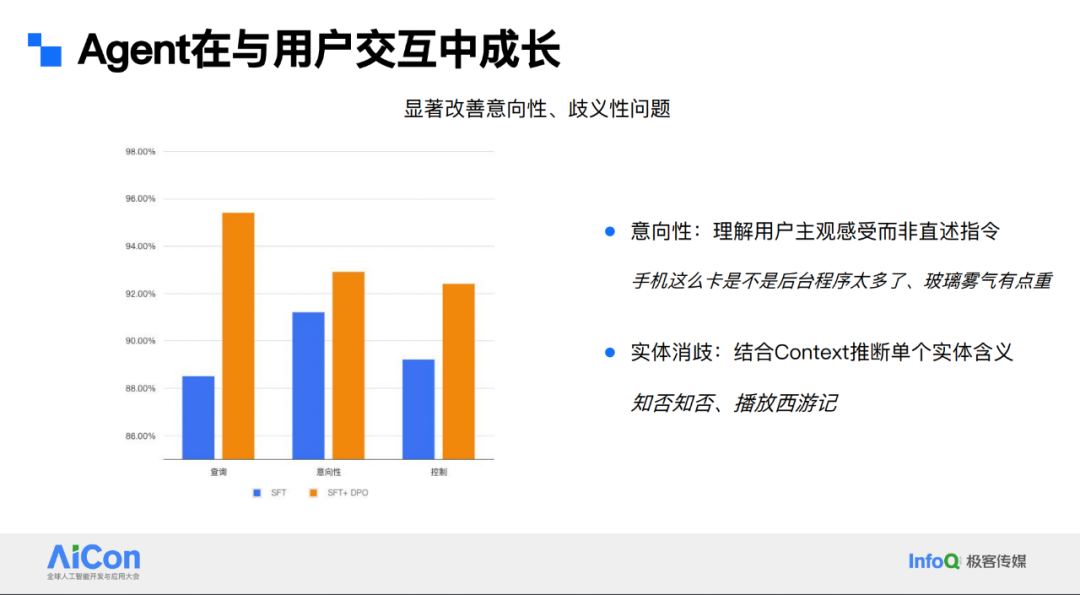
整个过程是基于反馈学习的强化学习链路。业务方面,基于小爱语义理解基座模型,各业务开展 post training,SFT 对齐后线上部署业务模型。线上运作产生日志,经负反馈挖掘和大模型辅助标注,能快速收集大量偏好数据。这里的偏好指模型预测结果用户不喜欢时,我们会调用更大模型如 72B 等查看用户真实需求,经人工 review 后作为正例,原模型预测结果为负例。通过这种方式累积偏好数据,再以数据飞轮形式持续迭代线上模型。
这种方法主要解决中长尾的意向性和歧义问题。中长尾问题典型表现为用户 query 表达主观感受而非陈述指令。比如在车上说“玻璃上的雾气有点重”,或在手机上说“我的手机这么卡,是不是后台程序太多了”,与直接说“我要打开前车窗除雾”这种指令相比,更偏长尾。早期模型常将“玻璃雾气有点重”理解为问答需求,向用户解释车窗有雾气的原因,但用户实际想打开车窗除雾功能。
实体消歧方面,语义理解不仅依据 query,还结合用户 context,如之前的使用偏好、年龄段、请求设备等。这可能导致推送结果并非最适合用户。例如“知否知否”,成年女性可能是想看电视剧,小孩子可能是想了解李清照的词。内容垂域的语义理解会因 context 不同而有不同结果,存在正负偏好问题。
提升 Agent 服务响应速度
先从模型本身分析大模型性能问题。大模型是 decoder 模型,包含 attention 计算过程,该过程与序列长度密切相关。且 decoder 结构是逐 token 解码,语义理解场景需完整结果才能执行后续策略,整包延迟受解码影响。另外,模型参数量大,即使压缩到 4B,部署时并发也不高,因模型占显存空间大。
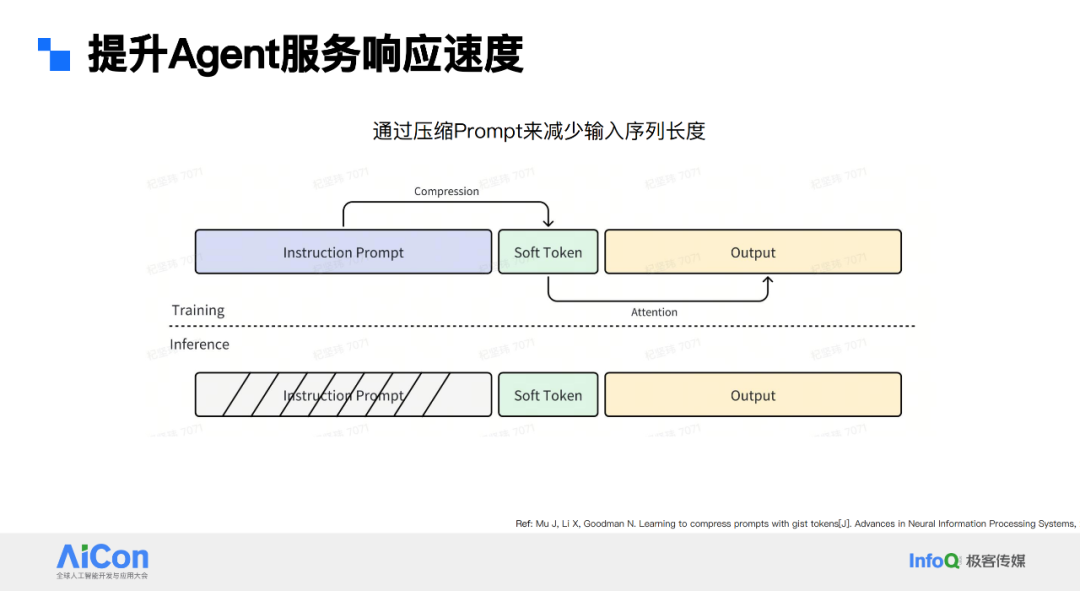
为解决这些问题,首先是压缩 prompt 序列问题。在 post training 中会给模型长 instruction,若线上也用长 instruction,prefilling 过程会很长。于是采用压缩方式,在训练时插入 soft token 结构,将 instruction 信息量压缩到 soft token 中,训练出后续 output。线上推理时,可去掉整段 instruction,模型预测 output 只看到 soft token,不会带来效果偏差。
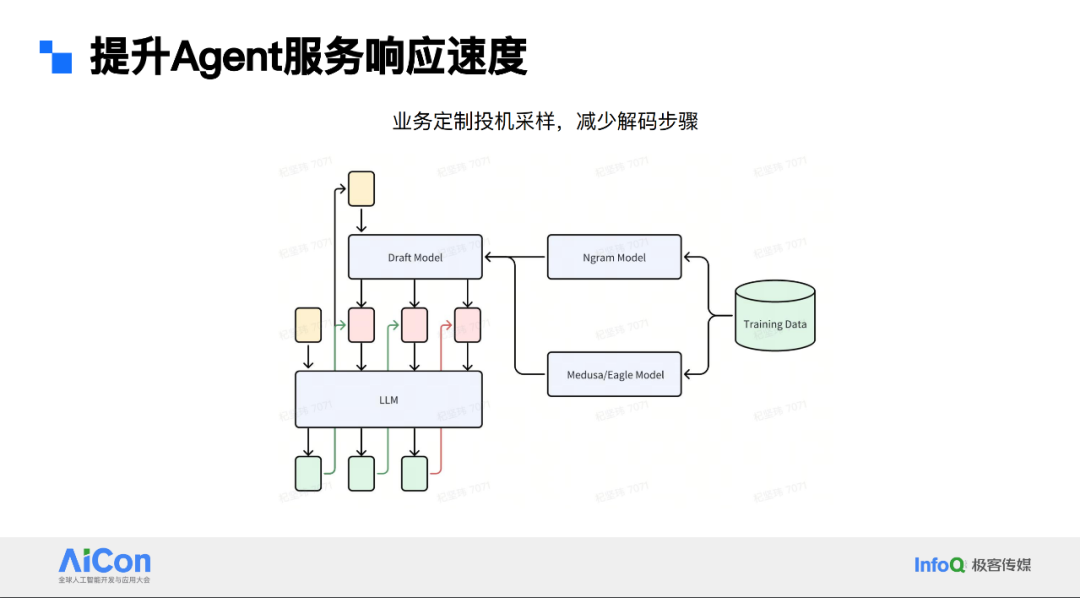
第二个解决办法是基于业务定制的投机采样过程。投机采样在大模型行业常见,用于解决逐 token 解码问题。简单说是有小模型即 draft model,基于当前输入预测未来若干 token,统一交大模型判别。若小模型输出的 token 都被大模型接受,就只用大模型做一次推理。
结合业务,希望大模型输出具结构性代码,function 下参数较固定,适合用 ngram draft model。参数值位置可能语义相关,需用美杜莎或 EGO 等语义 draft model 范式。线上操作时,结合上下两种模型,先用 ngram model 预测,若大模型未判定成功,再用美杜莎判定结果,这种混合投机采样方式效率更高。
在模型量化方面,我们遵循业界主流思路,采用 FP8 量化范式进行线上模型推理,主要目的是减少模型参数频繁加载到显存过程中产生的 IO 消耗。从线上效果看,FP8 量化相比 FP16,性能有明显提升。
小结
从 Agent 视角总结语音助手升级情况,首先解决方案变得更通用,优化链路简化,能更专注解决长尾问题,泛化能力增强。其次业务更端到端,减少诸多业务模块,投入更少人力提升迭代效率。最后是数据驱动,依据线上业务反馈结果驱动模型持续优化。
升级后带来的收益,如前两个月发布的超级小爱,相较于原小爱支持更多新颖能力。例如从单指令到多指令,从精准指令到意向性表达需求,以及包含多个操作的复杂任务和带逻辑关系的表达,在这些任务上,超级小爱或经 Agent 技术赋能的小爱,相比原判别式语义理解有更强表现。
未来优化方向
未来超级小爱可从以下方面进一步优化。
首先是实现主动智能,目前小爱与用户交互以用户主导,对话始于用户唤醒,执行指令时无法提供更多参考信息。我们希望小爱能主动向用户提供解决方案、确认细节,如在点咖啡、订票等场景中,用户首轮指令难含全量信息,需多轮确认;还可依据用户习惯主动推荐,像用户常在特定时间从公司打车回家,后续到该时间离开公司地理范围时,主动弹窗询问是否叫车;以及提前感知温度,上车前主动打开座椅加热等,提升主动智能交互体验。
其次是增强多模态能力,已有相关尝试,在 GUI 界面上感知用户手机界面及 query,实现深度操控。目前主要通过 API 与三方 APP 交互,但收集三方 APP 交互能力难,且 APP 升级后接口易变。我们希望实现更端到端、直接的交互,手机屏幕交互是更自然形式。目前以生活服务类场景为主,推进多模态交互能力。
总 结
在本次演讲中,我们深入探讨了如何将 Agent 技术应用于智能语音助手,并提出了四个核心问题以及相应的解决方案,同时展望了未来的优化方向。
我们讨论了如何在语义理解中发挥 Agent Planning 的作用。我们采用了代码式语义理解,通过多 Agent 协同的架构,使得 Agent 能够更准确地把握用户的意图和需求。
我们关注了如何让 Agent 掌握各类功能使用方式。通过持续预训练与精细化微调,Agent 能够更好地理解和执行各种任务,提高其在实际应用中的效能。
我们着重于如何让 Agent 在交互中不断优化。我们利用基于用户反馈的强化学习,使 Agent 能够根据用户的反馈进行自我调整和学习,从而提供更加个性化和精准的服务。
我们还解决了如何保证 Agent 在运行中的响应速度问题。通过序列压缩、解码提效、模型压缩等技术手段,我们显著提升了 Agent 的运行效率,确保了用户体验的流畅性。
展望了未来的优化方向,我们希望能够实现更加主动智能的交互体验,让 Agent 能够更主动地为用户提供服务,而不仅仅是响应用户的指令。同时,我们也在探索结合多模态信息的深度理解与控制,以实现更加丰富和自然的交互方式。
会议推荐
在 AI 大模型技术如汹涌浪潮席卷软件开发领域的当下,变革与机遇交织,挑战与突破共生。2025 年 4 月 10 - 12 日,QCon 全球软件开发大会将在北京召开,以 “智能融合,引领未来” 为年度主题,汇聚各领域的技术先行者以及创新实践者,为行业发展拨云见日。现在报名可以享受 8 折优惠,单张门票立省 1360 元,详情可联系票务经理 18514549229 咨询。




