
为了提供高可用能力、避免数据丢失,在分布式数据库或存储系统中需要设立数据副本机制,而副本的引入,可以说是分布式存储中的“万恶之源”。多副本之间应该满足强一致吗?强一致会导致请求延迟增加多少?强一致约束下能提供哪些可用性?诸如此类,种种问题,不一而足。
此外,分布式系统中的 CAP 原理可以被表述为:在网络分区存在的情况下,强一致与可用性是不可兼得的。由此发展出符合 BASE 标准的 NoSQL 数据库,在这类数据库中,以最终一致性取代强一致性。
那么,我们所说的强一致和最终一致究竟是指什么呢?
强一致意味着多副本数据间的绝对一致吗?显然,在分布式系统中,由于网络通信延迟的存在,多副本的严格一致是不可能的。
那是代表返回写入请求时多副本已经达到完全一致了吗?熟悉 Raft 的朋友会立即指出,不一定,Raft 就只需要在 quorum 中(超过半数)副本达成一致即可返回写入成功。
抑或是只需要 quorum 的一致即可吗?这取决于具体的算法,如果我们不限定读取操作只被 leader 处理,那么,达成 quorum 一致之后仍然可能读取到旧数据。
而在实际系统中,一致性问题的解法可能更加复杂,需要在一致性、读写延迟中做出权衡。
以时序数据库TDengine为例,我们为元数据的读写提供强一致性;时序数据在部分场景中则需要降低读写延迟、提高吞吐,仅需满足最终一致即可;而在另一些场景中,时序数据又需要有强一致保证。
为了更好地探讨一致性的相关问题,我们首先需要为不同的一致性级别下一个定义。
从并发模型中的一致性到分布式多副本一致性
一致性模型(consistency model)最早是定义在并发模型上的[1]。常用的一致性级别定义包括以下 5 种:
严格一致性(strict consistency)
线性一致性(linearizability,又译可线性化)
顺序一致性(sequential consistency)
因果一致性(casual consistency)
FIFO 一致性(FIFO consistency, 又称 PRAM consistency, pipelined RAM concsistency)。
之所以能够从并发模型直接推广到分布式多副本系统,是因为它们都可以建立在抽象的多读者、多写者寄存器(MWMR register, multiple writer multiple reader register)模型之上[2]。
值得注意的是,这里的寄存器是抽象的概念,并不是硬件寄存器。它泛指定义了读、写操作的一系列值的存储对象。
在并发系统中,读操作与写操作可能是多线程并发地在不同 CPU 上执行;在分布式系统中,它们可能是多进程被分布在不同的物理节点上执行。但相同的是,这两类系统中的读操作与写操作都有一定的延迟,不是瞬间完成的。
为了便于理解,我们不会照搬形式化的定义,而是提供一些更符合直觉,但不失准确的描述。
线性一致性:
假设在分布式系统中存在绝对的物理时钟(真实时间),进程与进程之间不存在时间的漂移。那么,我们将读写操作的开始与结束的真实时间记录下来,为每个操作从开始到结束的持续时间段中选择一个时刻点,视该操作为在此时刻瞬间完成。如此,所有操作都可以被等效为一个进程在真实时间轴上瞬时完成的读写操作。若所有的读操作得到的都是上一次写操作的结果,那么,该系统满足线性一致性。
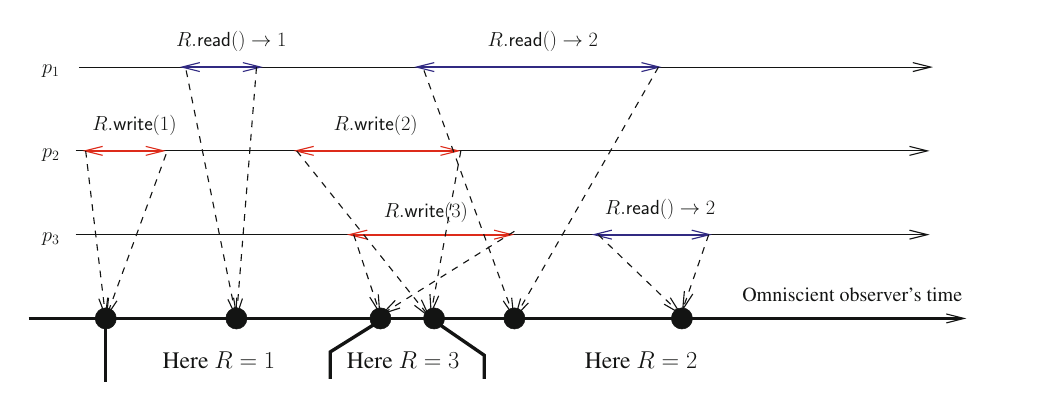
图 1
可以看到,进程 p3 的写操作 R.write(3)开始和结束都分别晚于进程 p2 的写操作 R.write(2)的开始与结束,但由于它们时间有交叠,R.write(3)的线性化点(操作的等效时刻)可以先于 R.write(2)。因此,图 1 系统满足线性一致性。
顺序一致性:
但是在实际的分布式系统中,并不存在绝对的真实时间[3]。因此,在外部的观察者看来,任意单个进程的操作顺序是确定的,但考虑所有操作的某种全序关系时,一个进程的读写操作可以被插入到其他进程的任意两个操作之间。不同的插入方式,会生成不同的全序关系,只要能保证存在一个合法的全序关系,则满足顺序一致性。
所谓的合法是指:1.全序化后读操作必须读到上一个写操作的值;2.单个进程内的操作先后顺序与在全序关系中的操作先后顺序一致。
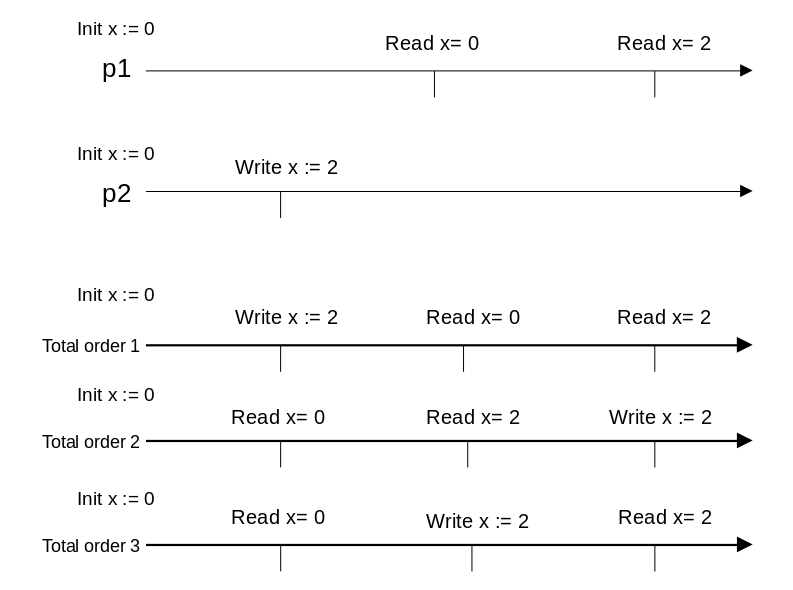
图 2

图 3
由于不存在绝对时间,我们不再要求画出读写操作的起止时刻,而将其视为瞬间完成的操作。在图 2 中,全序 1、2、3 中,只有 3 是一个合法的全序,因此图 2 中的读写满足顺序一致性。而在图 3 中,不存在一个合法的全序,因此,图 3 中的读写不满足顺序一致性。
由此可见,线性一致性可以被看作顺序一致性在存在绝对时间的系统模型下的特例。
因果一致性:
由于进程 p2 是读取了进程 p1 写入的结果之后写入,进程 p2 的写入值和进程 p1 的写入值可能存在因果关系。那么,所有在同一个进程内的连续读操作都不可以先读到进程 p2 的写入值,再读到进程 p1 的写入值。
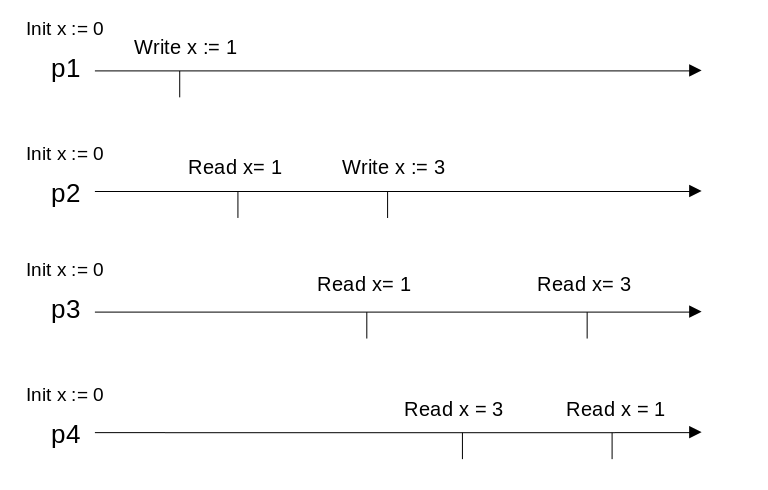
图 4

图 5
图 4 中,进程 p1 和 p2,p2 先读到了 p1 写 x:=1 的结果,然后写 x:=3。写 x:=3 可能是由读 x=1 计算而来,因此存在因果关系。p3 满足了因果一致性,p4 则违背了因果一致性。
图 5 中,p2 不再读 x=1,因此不存在因果关系。该系统满足因果一致性,但不满足顺序一致性。
FIFO 一致性:
FIFO 一致性不会考虑多个进程之间的操作排序。对任意一个进程的写操作 1 与写操作 2,若写操作 1 先于写操作 2 完成,那么任何进程不可以先读到写操作 2 的值,再读到写操作 1 的值。
图 3 就是一个违背 FIFO 一致性的例子。图 4 与图 5 中,由于不存在同一个进程中的多个写操作,因此都满足 FIFO 一致性。
最终一致性(Eventual consistency):
最终一致性,可以这样定义,若系统中不再发生写操作,经过一段时间后,所有的读操作都会得到同样的值。
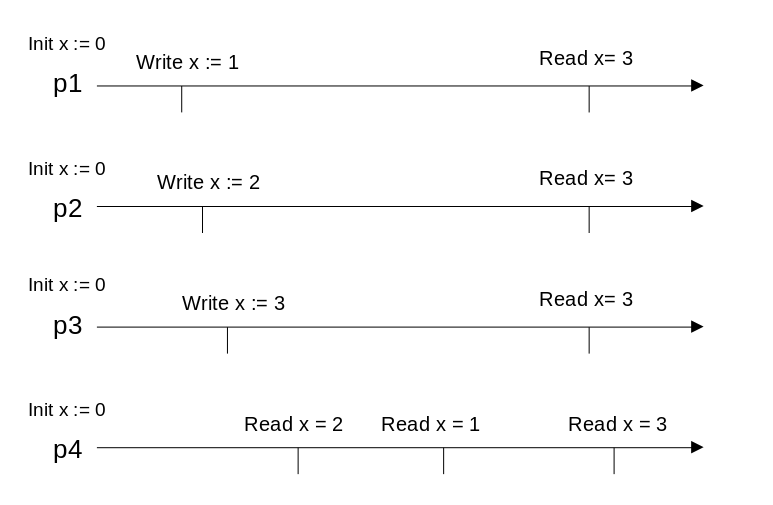
图 6
以图 6 为例,最终一致的结果,既可能是 1,又可能是 2,还可能是 3(在不存在绝对时间的系统,甚至无法定义最后写入的值是 1、2 还是 3),但所有进程再足够长的时间后的读结果都必须保持一致。
多副本的一致性级别是由并发模型中的一致性级别直接应用到分布式系统中的结果,但有少许差别。细心的朋友可能注意到,我们并没有提及严格一致性,那是因为严格一致性要求数据被立即同步(比如在 CPU 的下一个时钟周期可见),这只能存在于单机系统中,并不存在于存在消息延迟的分布式系统中[4]。
我们通常所说的强一致,通常是指线性一致性或顺序一致性[5][6]。线性一致性与顺序一致性之间的区别,也可以被理解为系统模型的区别,即系统中是否存在绝对时间。弱于顺序一致性的一致性级别都可被称为弱一致,而最终一致性是弱一致性的一种形式。
探讨一致性级别时,一个常犯的错误是与事务的隔离级别混淆,事实上,虽然它们之间存在一定的联系,但并不是同一回事。当一个数据库在隔离级别上满足可串行化(Serializable),在一致性上满足线性一致性,则称为严格可串行化(Strict Serializable),这是一个统一了一致性级别与隔离级别的定义。
另一个常犯的错误是将一致性(consistency)与共识(consensus)混淆。共识问题是在分布式系统中有明确定义的一类问题,解决共识问题的经典算法是 paxos;强一致读写可以通过一系列的全序共识实现,Raft 便是这样一种算法。
以上定义的一致性级别可以被认为是以数据为中心(Data-centric)的一致性级别,另一种定义方式是以客户端为中心(Client-centric),还可以定义出写后读、读后写、单调写、单调读的一致性,此处不再赘述[4]。
一致性级别分析:以 Raft 为例
下面我们以 Raft 为例分析其一致性级别。在正常情况下,Raft 是在 leader 上完成读与写操作的,可以被看作单读单写的系统,若这个系统中将 leader 的时间视为绝对时间,则可认为提供了线性一致性。
但是,我们还需要考虑异常情况,当消息延迟时,Raft 可能出现短暂的双主;若出现网络分区,可能持续处于多主状态。
一种实现方式是,假如每个 leader 在提供读服务时都不做额外操作,那么,如果多数派分区的 leader 已经完成了新的写入,少数派分区的 leader 仍然提供读服务,就可能读到旧数据。
这个问题的一种解决方法是,让少数派分区的 leader 直接拒绝读服务。这如何实现呢?让 leader 在与客户端交互,完成读操作前发送一个 no-op 并至少得到半数回应,由于少数派分区的 leader 无法得到半数回应,因此无法提供读服务。
关于如何在 Raft 中获得线性一致性的详细探讨可详见 Raft 论文[7]中第 8 节 Client Interaction。
TDengine 提供的一致性级别
在上述的分析中可以看到,Raft 中实现线性一致性会为读操作和写操作都带来至少 2 个 RTT 的延迟(client 视角,从 client 到 leader,再由 leader 到 follower);即使仅实现顺序一致性,也会在写时带来至少 2 个 RTT 的延迟。
在 TDengine 中,为了降低写入数据的延迟、提高吞吐量,我们为元数据(表数据、表的标签数据)提供强一致性,为时序数据提供最终一致性与强一致性两种可选的一致性级别。当用户选择最终一致同步,写入的延迟可以被降低到 1 个 RTT(从 client 到 leader),这大大优于 Raft 这类强一致复制协议提供的性能。
随着 TDengine 集群版的开源,用户数量与日俱增,TDengine 被应用到了多种多样复杂的环境中。当集群中存在网络分区、或节点连续宕机等异常情况下,TDengine 中可能无法保证严格的强一致性,因此,在即将到来的 3.0 版本中,我们将以 Raft 算法为基础重构选主、强一致复制等一系列流程,同时,仍然为时序数据提供最终一致与强一致两种同步模式,给用户提供灵活的选择,帮助用户适应最复杂的业务场景需求。
参考文献:
[1]Lamport, Leslie (Sep 1979). "How to make a multiprocessor computer that correctly executes multiprocess programs". IEEE Transactions on Computers. C-28 (9): 690–691. doi:10.1109/TC.1979.1675439.
[2]RAYNAL, M. (2018). FAULT-TOLERANT MESSAGE-PASSING DISTRIBUTED SYSTEMS: an algorithmic approach.
[3]Leslie Lamport. 1978. Time, clocks, and the ordering of events in a distributed system. Commun. ACM 21, 7 (July 1978), 558–565. doi:10.1145/359545.359563
[4]Sukumar Ghosh. 2014. Distributed Systems: An Algorithmic Approach, Second Edition (2nd. ed.). Chapman & Hall/CRC.
[5]Kemme, B., Schiper, A., Ramalingam, G., & Shapiro, M. (2014). Dagstuhl seminar review: Consistency in distributed systems. ACM SIGACT News, 45(1), 67-89.
[6]Kleppmann, M. (2015). Designing data-intensive applications.
[7]Ongaro, D., & Ousterhout, J. (2013). In search of an understandable consensus algorithm (extended version).




