
背景
之前介绍了缓存治理的实践,具体参考:国内酒店稳定性治理实践之缓存治理 。在做完缓存治理后,我们并没有止步。
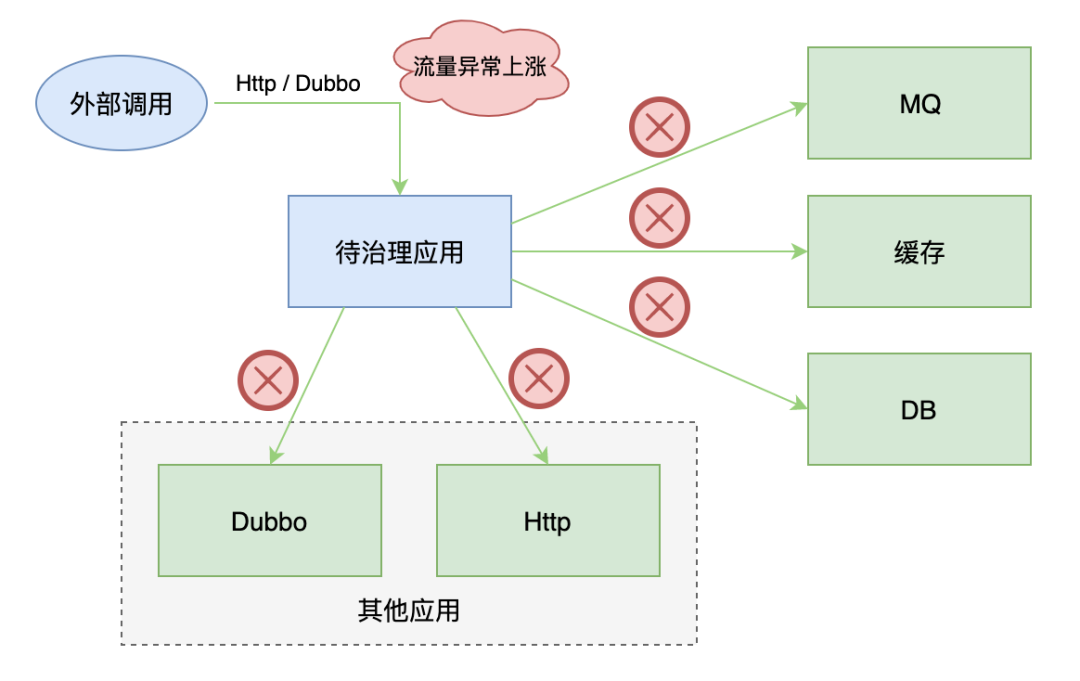
我们的应用还依赖了很多外部组件、接口,也同时对外提供了一些接口,所有这些依赖都有出现故障的可能,而且个别场景在故障时影响可能很大。因此在缓存治理之后,我们开始了覆盖度更广的稳定性治理。
本篇文章重点讲述对系统间依赖的治理,主要包括系统依赖的外部组件、依赖的外部接口、对外提供的接口,比如 Dubbo、Http、DB、MQ 等。
治理方案
服务定级及依赖治理
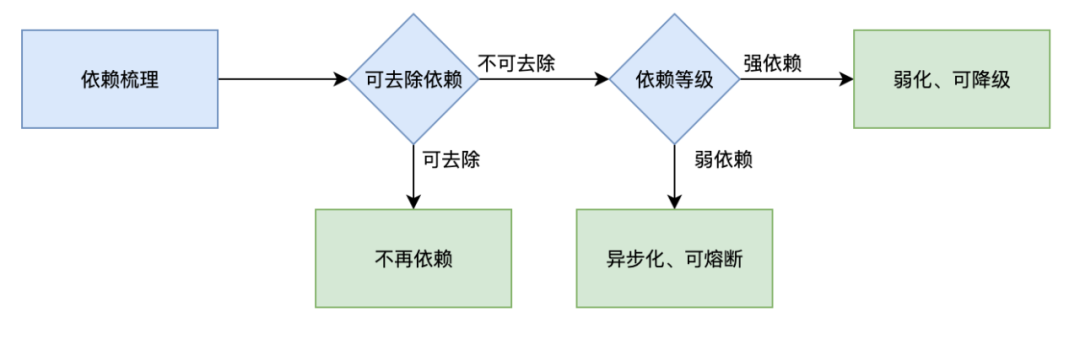
1)根据业务核心程度及影响,标记每个应用的等级(P1、P2、P3,按核心程度 P1>P2>P3),并梳理依赖等级。
2)P1 应用保证多机房部署,同时保证:正常情况下,任何一个 P1 应用在任何一个机房的在线机器数不超过该应用整个在线机器数的一半。这样调整部署之后,单机房的网络和个别组件故障时,核心业务的影响明显减小。
3)对于强依赖,进行弱化,做到可降级;对于弱依赖,进行异步化,做到可熔断;同时去除一些非必要的依赖。对于 P1 应用接口调用的 P3 应用接口,我们提前对调用做好异常处理,并支持熔断,之后在线上演练摘掉所有 P3 应用在线机器,P1 应用接口可以不受影响;对于 P1 应用接口调用 P1 应用接口,我们提前准备好降级方案,通过多通道、多副本等手段来保证调用端可以快速进行故障恢复。提前评估这些强、弱依赖出故障的影响,并准备好处理手段,这样才能减少故障次数、降低故障时影响。
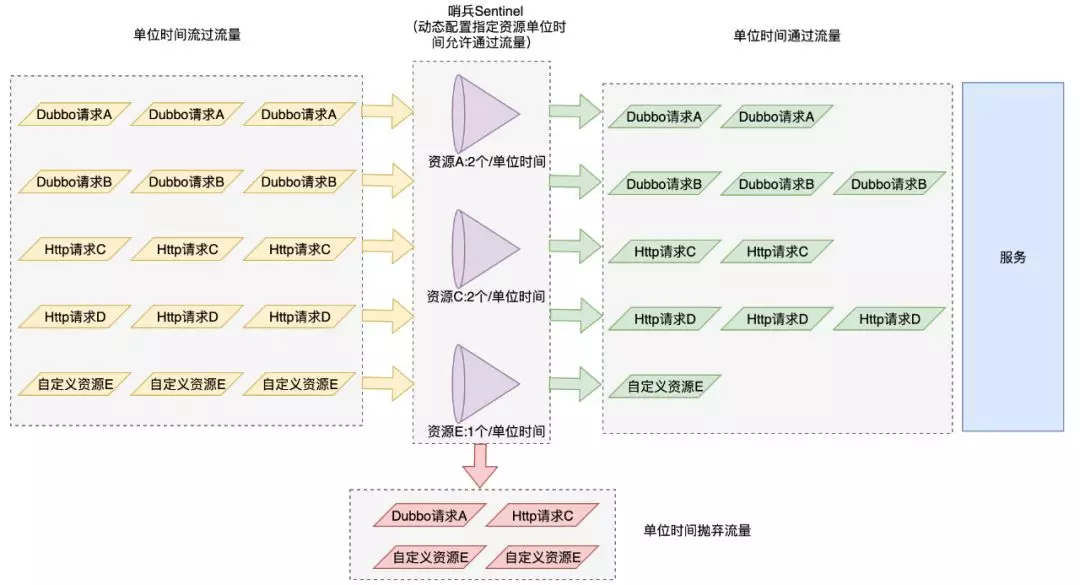
限流
这个主要应对的是流量突然变大导致应用可能扛不住的场景。我们选择统一接入封装后的 sentinel 组件,主要使用的功能包含:
1)应用级别单机 Dubbo 动态限流:允许动态配置对所有 Dubbo 接口的限流。
2)应用级别单机 Http 动态限流:允许动态配置对所有 Http 接口的限流。
3)业务埋点限流:根据个别参数特殊的值进行单机(或者集群)限流。比如对于核心的接口,我们不能只具备接口维度的整体限流,还要能对一些特殊的参数进行限流,典型的例子就是酒店报价接口可以通过参数区分来源是 app 或 pc,目前来自 app 的请求量远远大于 pc 端,当 pc 端流量异常上涨时,可以单独增加对 pc 端请求的限流,这样就不会影响到 app 端的请求。
4)应用级别接口的集群动态限流:从系统保护层面来说,这个不是必须的,只对某些特殊场景有用,目前我们主要使用上面三种。
sentinel 这个组件允许直接从接口层面限制住流量上限,如果真有异常量级流量进来时,我们可以配置相关规则拒绝一定量级的请求,根据当前集群的能力尽可能对外提供服务。这样异常量级流量就不至于把应用所在集群所有机器打死,导致应用无法提供服务或者提供服务能力锐减等。
需要注意的是,限流本质上会影响请求的处理,可能会对用户体验造成影响,因此在系统能扛得住的时候我们是不希望使用限流的。应用流量可能在某些节假日或者活动时异常上涨,这些都是正常的用户流量,这个时候我们更期望的是应用能正常处理这些流量。这时我们不光要提前准备好限流手段,更需要提前预估流量,做好压测,评估应用是否需要扩容及扩容的机器数量。
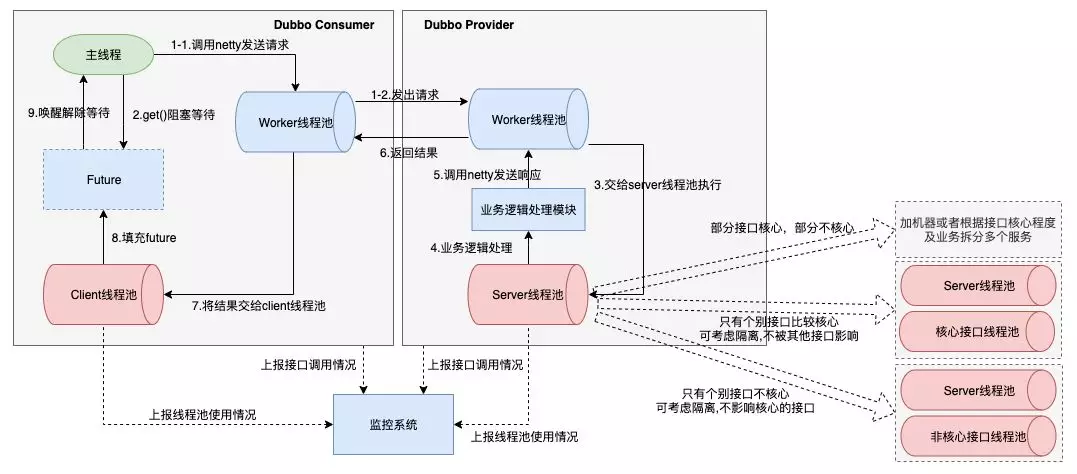
Dubbo 治理
这个主要应对一些 Dubbo 线程池被打满及下游 Dubbo 服务超时的场景。
1)Dubbo 线程池监控:这是很容易被忽略的点,尽可能避免线上 Dubbo 线程池不够时才想起临时增加机器或者增大线程数,也方便做一些需求评估。provider 端业务线程池默认共用同 1 个线程池,每增加一个接口都会消耗这个默认线程池的资源。qunar 内部的 Dubbo 线程池做过一些调整,consumer 的业务线程池也是共用的同一个。
2)Dubbo 线程池隔离:可以隔离出核心接口,也可以把个别非核心接口隔离。主要防止非核心接口出问题时打满 Dubbo 线程池,影响核心接口的服务能力。举个实际的场景,某核心应用增加了一个非核心的 Dubbo 接口,量级大而且响应时间较长,这个接口不断抢占 provider 的线程池资源,导致这个应用的核心 Dubbo 接口出现拿不到连接的情况,这时候就可以将这个非核心的 Dubbo 接口隔离使用单独的线程池,就可以不影响核心接口了。
3)Dubbo 接口超时时间合理化配置:要根据接口正常响应时间配置,consumer 端的超时时间一定要配置,且不能大于 provider 端的超时时间。
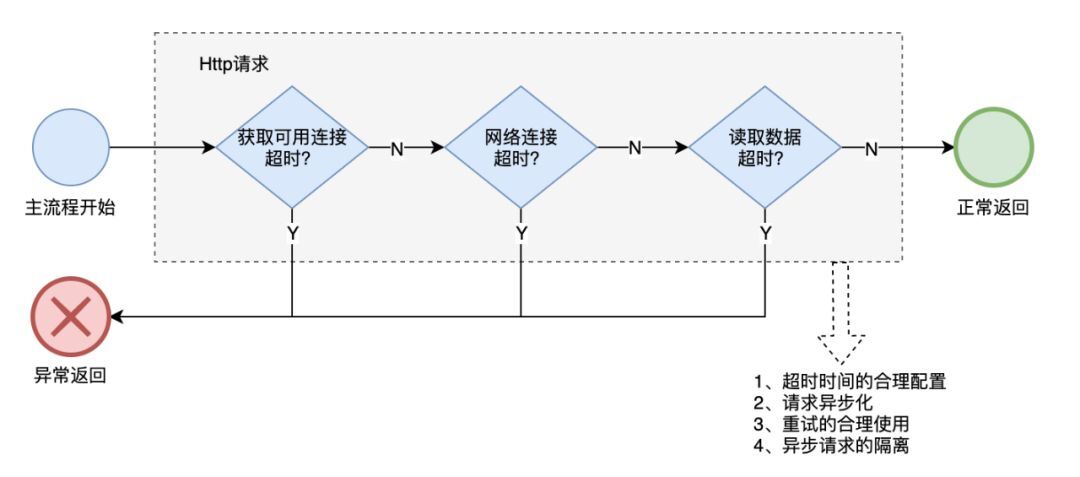
Http 治理
这个主要针对调用外部 Http 接口出现大量超时及异常的场景。
1)超时配置检查:根据接口实际情况,配置合理的超时时间(比 P99 大一些),同时支持动态配置超时相关的参数值。超时是目前组内应用异常最多的地方,超时时间过大容易出现一直占着主线程最终拖垮服务。
2)异步化:推荐使用异步方式调用,并且支持同步、异步切换。
3)支持重试:业务检查是否可以及是否需要配置重试,不建议同步执行的接口做重试(容易超时)。实际中很多接口重试 1~2 次就可能成功,但需要和下游沟通确认是否可以重试。
4)做好隔离:对于异步调用,做好线程池隔离及 client 隔离,防止不同的接口调用相互影响。
DB 治理
DB 和之前的缓存治理还是很相似的,主要关注的是组件出现问题后的快速恢复,以及核心数据存储做好多副本、多分片。
1)高可用保证:数据多副本存储(主从、DB 存储 redis 缓存)、快速恢复及降级等处理,降低可能的慢查询、DB 宕机等对服务能力的影响。
2)优化存储的无用数据,比如国内酒店相关服务去掉缓存的国际酒店数据。
3)监控平均请求数据集(超出一定数据集增加报警),实现 Mybatis 的 Inteceptor 在切面里完成。
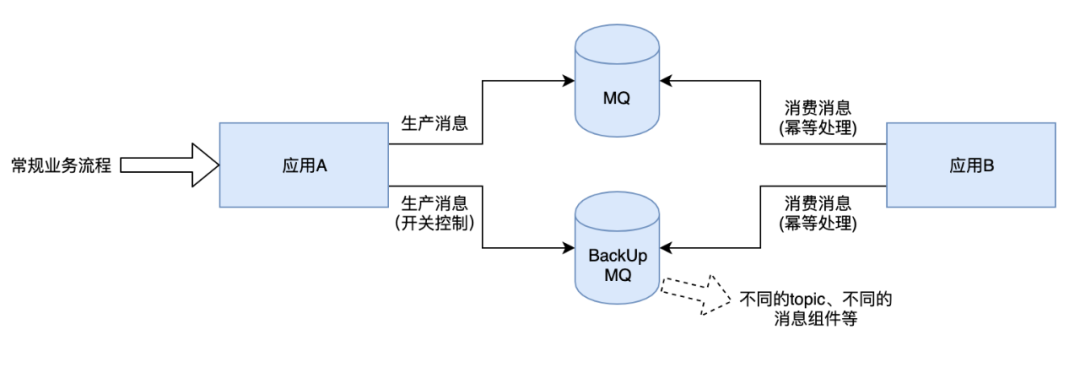
MQ 治理
这个主要应对单个 MQ 无法正常发送消息、或者消费严重堆积的场景。比如之前出现过单个机房 zk 故障导致 MQ 部分 topic 发送失败。
首先确认 MQ 是否可以快速切换到正常的通道,比如将消息屏蔽故障机房、或者将消息漂移到正常的机房。
特别核心的场景准备好多通道:发不同 topic 的消息或者使用两个不同的 MQ 组件,这时需要注意消费时做好幂等,这样挂掉一个集群不会对核心造成影响。
其他
1)检查并完善监控:Dubbo 接口、Http 接口、DB 相关的 Mybatis method 接口等操作成功及异常的 QPS、时间等监控。
2)添加 appcode 维度的各组件及调用的监控面板:方便巡检和故障时快速查看。
3)超时等配置检查及合理性修正:通常 connect timeout 要短,socket timeout 可以根据业务实际情况大一点。实际开发中,很多人都是 copy 的 demo 或者某处使用的代码,而忽略了这些数值是否合理。
治理过程
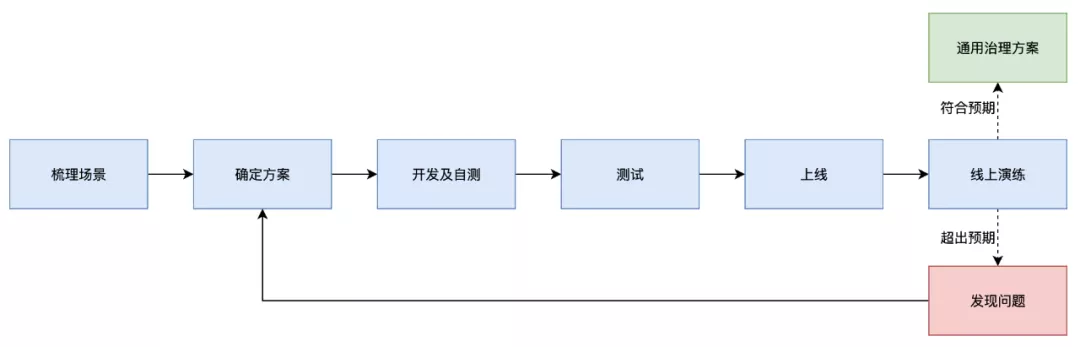
整体过程和之前缓存治理的很像,主要都是“梳理场景 → 确定方案 → 开发及自测 → 测试 → 上线 → 线上演练及改进”。当然也有不同的地方,本次在对相关应用进行治理时,每个应用都是分两次或更多次进行线上发布:
1)先增加限流组件及相关的组件监控:先保证能对异常的流量进行预防,同时为后续治理准备好监控数据。
2)基于完善的监控指标,有针对性的进行参数及流程等的优化。
在这些都做完后,我们继续在线上进行演练。对于超出预期的,我们修正方案继续优化重新演练;对于符合预期的,我们整理成通用的治理方案,作为以后其他应用及新依赖治理的标准。
总结
每次故障后,我们都会做故障 review,然后提出一些改进点。回过头仔细 review 这些改进点,有很多我们可以在故障发生前做好预防,并通过一些治理将影响降低,甚至避免故障的发生。我们做稳定性治理的出发点也是希望在常见的故障前对一些问题和场景准备好处理方案和方法,尽可能降低故障数量、故障持续时间及影响。
做系统间依赖治理并不是一次就 OK 的,目前我们的治理也只是针对目前已有的依赖进行治理。未来我们计划能对这些依赖自动打上标记,并上报到专门做服务治理或相关的系统来管理,在系统里准备好故障时应对手段,这样既能动态识别出新的依赖,又能在故障时快速采取有效的手段进行应对。
本次做完系统间依赖治理后,我们继续对系统内部资源进行了治理,主要采用降级、熔断、隔离等手段,我们下一篇再具体讲解。
头图:Unsplash
作者:郑吉敏
原文:https://mp.weixin.qq.com/s/sWxbyD2srai35PARKk6ugw
原文:国内酒店稳定性治理实践之系统间依赖治理
来源:Qunar 技术沙龙 - 微信公众号 [ID:QunarTL]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




