
本文最初发布于 Miloslav Voloskov 的个人博客,经原作者授权由 InfoQ 中文站翻译并分享。
可扩展性被认为是一个很难解决的问题。人们总是把它看成是一种神奇的东西,是用神秘而特殊的工具完成的,只有身价百万的大块头才能使用。这当然不是真的。其实,那并没有什么神奇之处——那也不过是用普通编程语言编写的普通代码。
首先,要针对工作选择合适工具。你已经看过基准测试了,你知道有些语言在某些方面表现得更好。有些数据库的读取速度更快,而有些数据库的写入速度更快。
即使你已经为任务选择了合适的技术栈,一台服务器也是不够的。这就是有趣的地方。
当然,你可以直接从不同的 AWS 服务级别中进行选择。但是,如果想知道其中的原理,你就应该知道如何在裸金属上实现可扩展的设置。
基本原则
选择恰当的工具
不同的编程语言适用于不同的任务。
例如,Python 有非常丰富的语法糖,非常适合处理数据,而且代码简短而富有表现力。但为了实现这一点,它需要运行在解释器上,在默认情况下,这比编译后在裸金属上运行的 Go 或 C 是要慢的。
NodeJS 的外部工具可能是最丰富的,但它是单线程的。要在多核机器上运行 NodeJS,必须使用像PM2这样的东西,但这样的话,就必须保持代码是无状态的。
数据库也是一样。SQL 提供了图灵完备性来查询和处理数据,但这是有代价的——没有缓存,SQL 几乎总是比 NoSQL 慢。
除此之外,数据库通常是读取优先或写入优先的。这就意味着,它们中的一些在写入数据时速度更快,而另一些在大量读取时性能更佳。
例如,对于需要大量写入、偶尔读取的分析及其他任务,你可能想要选择“写入优先”的数据库,如 Cassandra。
对于显示新闻这样的读取优先任务,最好使用像 MongoDB 这样的东西。
如果两者都需要,就安装两个数据库!这不是不行。这不会造成什么破坏。事情就应该这样做。
多服务器
当一台计算机不够用的时候,可以用两台。当两台不够用的时候,可以买三台,以此类推。
但也有一个陷阱:从 1 到 2 比从 2 到 3 或从 10 到 20 要难得多。
要使用多台计算机,后端应该是无状态的。这意味着你必须将所有数据都存储到数据库中,而后端不保存任何数据。这就是函数式语言在后端如此流行的原因,这也是 Scala 被发明的原因。函数代码默认是无状态的。
无论如何,不同服务器的行为应该完全相同。如果你有大量的有状态服务器,那么根据定义,对相同的输入,它们很容易返回不同的数据作为响应,因为有两个事实来源:数据库和服务器状态。相信我,你不会想让这种事情发生的。
尽快实现无状态。最好从一开始就选择无状态。如果你在使用 NodeJS 和 PM2,如果你想让 PM2 帮你增加运行时以实现负载均衡,那你就必须让代码保持无状态。
负载均衡器会将请求重新路由到最空闲的服务器。显然,对于相同的请求,服务器应该提供完全相同的响应。这就是我们转向无状态的原因。对 NodeJS 来说,PM2 是一个很好的负载均衡选项。如果你用的不是 Node,就选择 Nginx。
会话?把它们保存在 Redis 中,并让所有服务器都可以访问。
缓存和速率限制
想象一下,每 100 毫秒针对每个用户做同样的计算。这将使服务器很容易受到 Slashdot 效应的影响——基本上只是用户访问数据就会导致 DDOS。
增加缓存中间件。只有第一个用户将触发数据查询,其他所有用户将直接从 RAM 接收完全相同的数据。
这也有缺点——默认情况下,数据会过期。通常,缓存中间件允许设置缓存重置时间,数据最终会刷新。
考虑用户和他们的需求,配置相应的缓存。永远不要缓存用户输入。只有服务器输出应该被缓存。
Varnish是一个很好的 HTTP 响应缓存选项,所以它可以用于任何后端。
即使有了缓存,每 10 毫秒就会出现不同的请求,也可能会导致服务器宕机,因为服务器会为它们计算不同的响应。这就是为什么你需要一个速率限制器——如果距离上次请求的时间不够长,正在进行的请求将被拒绝。这将使你的服务器保持活跃。
划分职责
如果你正在使用 SQL 数据库,并且仍然使用后端计算外键,那么你没有充分利用数据库的能力。只需设置记录之间的关系并允许数据库为你计算外键——查询规划器总是比后端更快。
后端应该有不同的职责:哈希、从数据和模板构建网页、管理会话等等。
对于任何与数据管理或数据模型相关的内容,将其作为存储过程或查询移到数据库中。
大数据量
即使是使用数据库集群,最大容量也受限于服务器的主板。你不能只是把无限多的硬盘放在那里。如果想要无限增长,除了使用分布式数据库之外,没有其他选择。它将数据存储在不同的服务器上,最大容量接近所有服务器容量的总和。如果存储空间不足,只需添加另一台服务器即可。
通过主从复制,你可以将 DB 加倍并实现负载均衡,但容量不会无限增长。
可能存在的瓶颈
单线程、有状态、不可扩展的服务器。为了实现负载均衡及运行多台服务器,代码必须是无状态的。
服务器做数据库的工作。将任何与数据相关的工作移到数据库中。
单数据库实例。实现数据库负载均衡,请选用集群。
把读取优先和写入优先搞混了。分析常见任务,有针对性的使用不同类型的数据库。
距离客户端太远。请使用 CDN。
设置举例
小猫

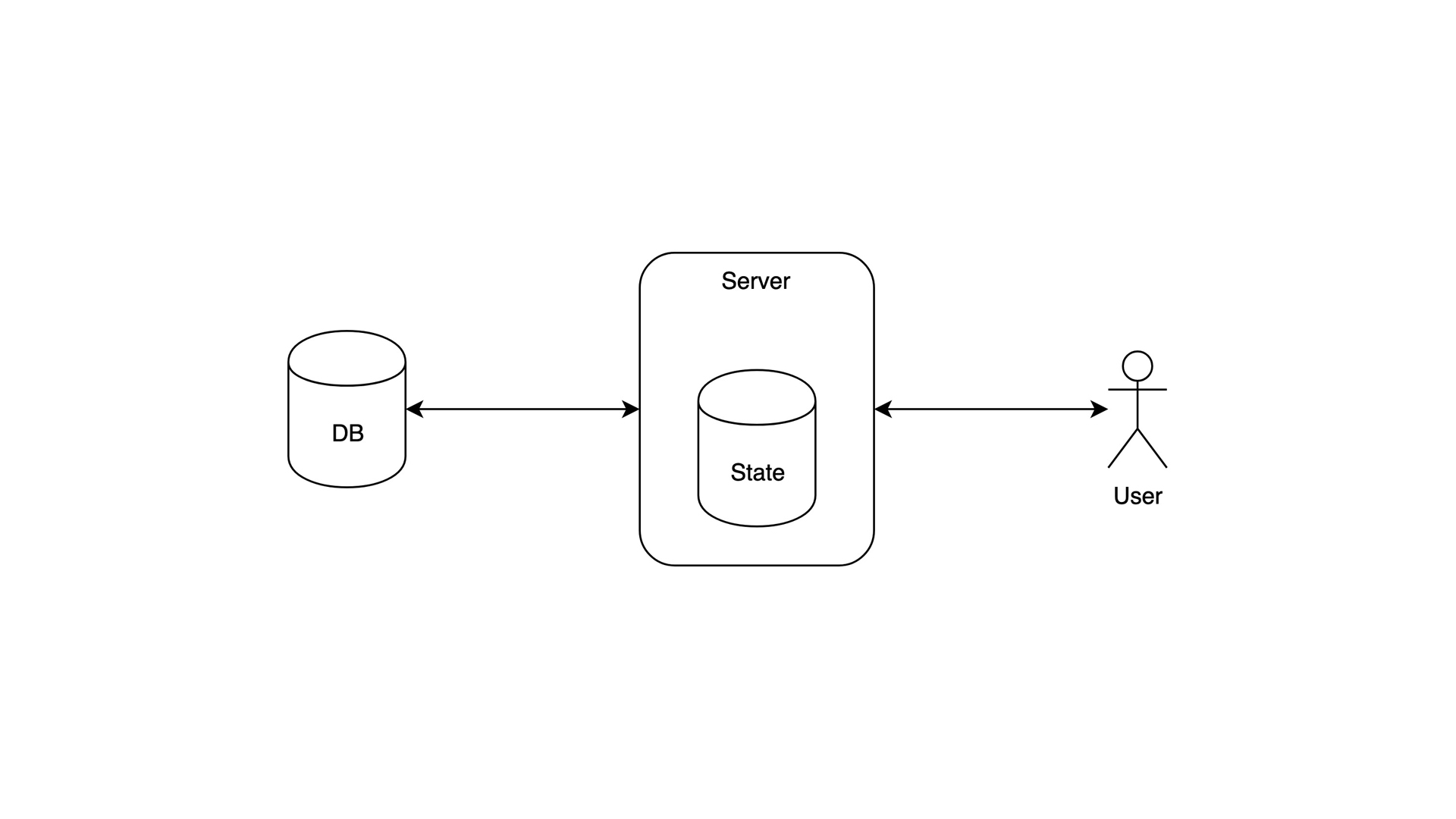
这是你一个晚上就可以在 LAMP 技术栈上构建的基本设置。它是有状态的——它在内存中存储会话和其他杂七杂八的东西。你猜对了,它根本无法扩展。但是,它仍然非常适合小型周末项目。
数据:GB 级
用户:几千
瓶颈:可用性。单服务器,很容易受 Slashdot 效应影响
工具:常规的 LAMP 技术栈
大猫

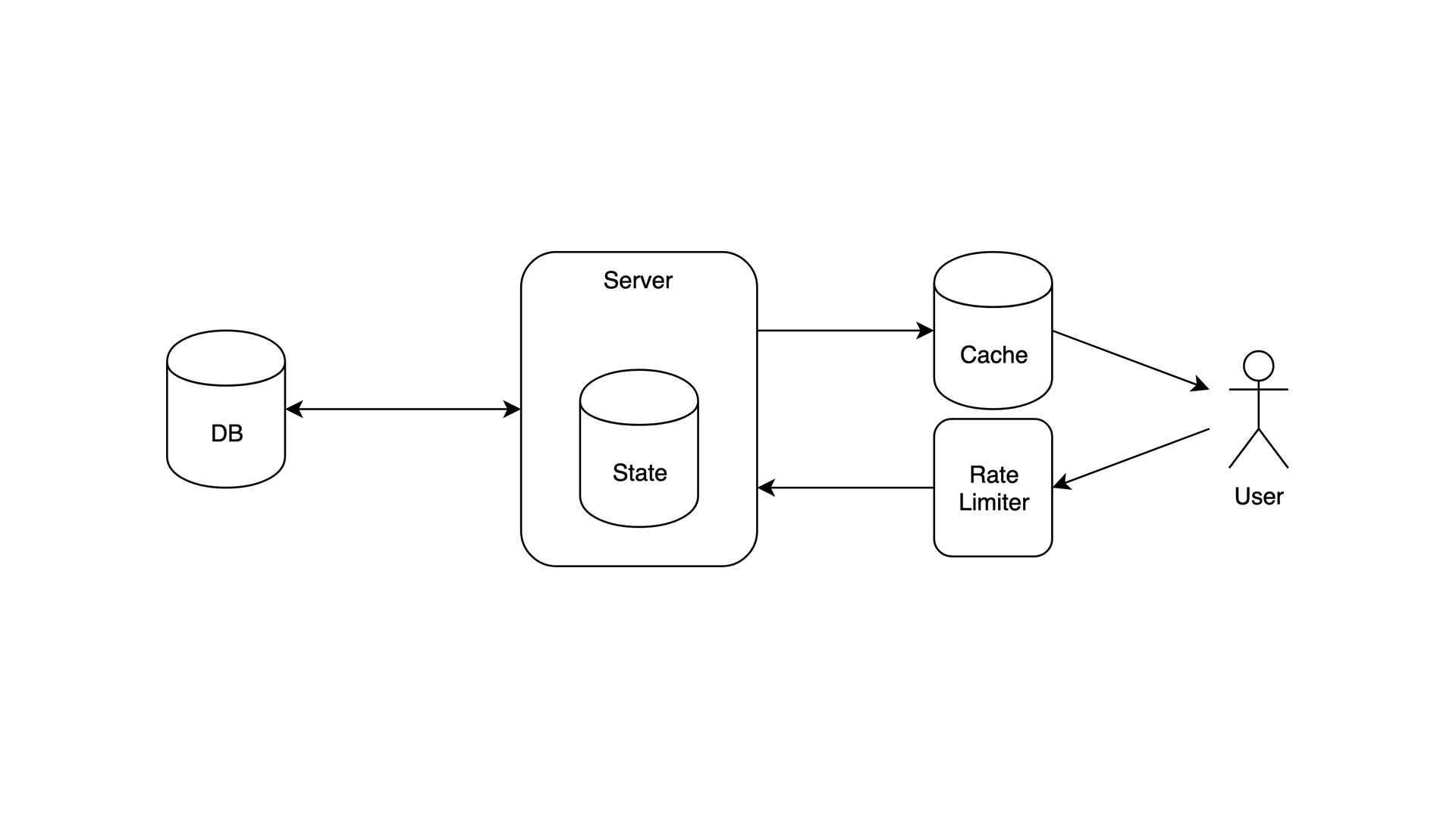
我们添加了缓存。虽然速度提升了,但由于架构是有状态的,所仍然不可扩展。当你的周末项目用户增加时,你应该这样做。
数据:GB 级
用户:几万
瓶颈:有状态服务器。即使有了缓存,服务器仍是不可扩展的
工具:MongoDB、Express 作为速率限制器和内存缓存
猎豹

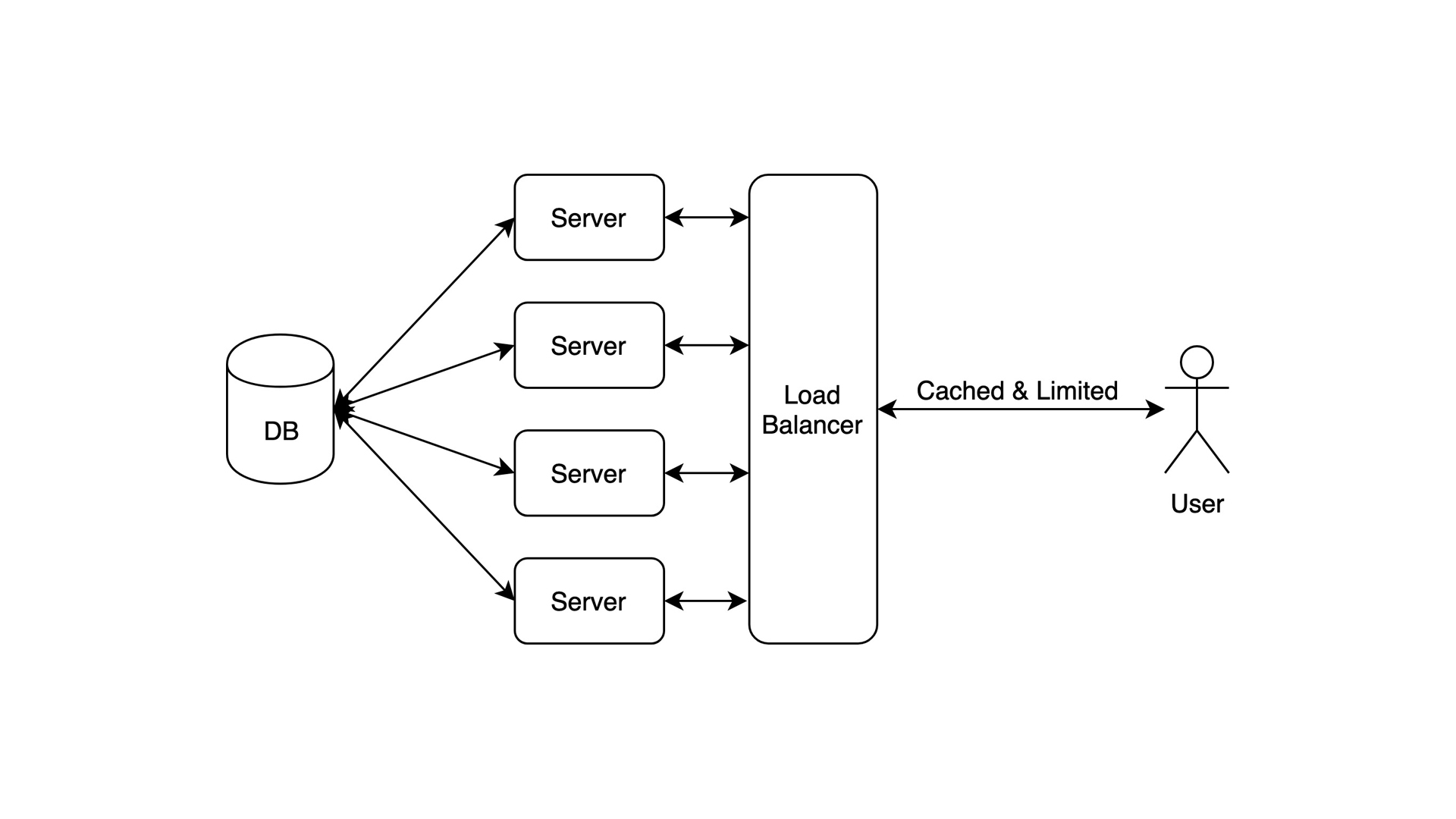
这是可扩展的!你可以拥有任意数量的服务器。现在,你可以处理所有可能导致“大猫”宕机的请求,但数据库仍然是运行单个实例,必须处理所有请求。尽管如此,它还是非常适合小型项目、电子商店或类似的东西。
数据:TB 级
用户:十几万
瓶颈:单数据库。使用函数式语言,服务器是可扩展的。但是单个 DB 可能无法处理大量的请求
工具:Go、Redis 缓存、MongoDB
老虎

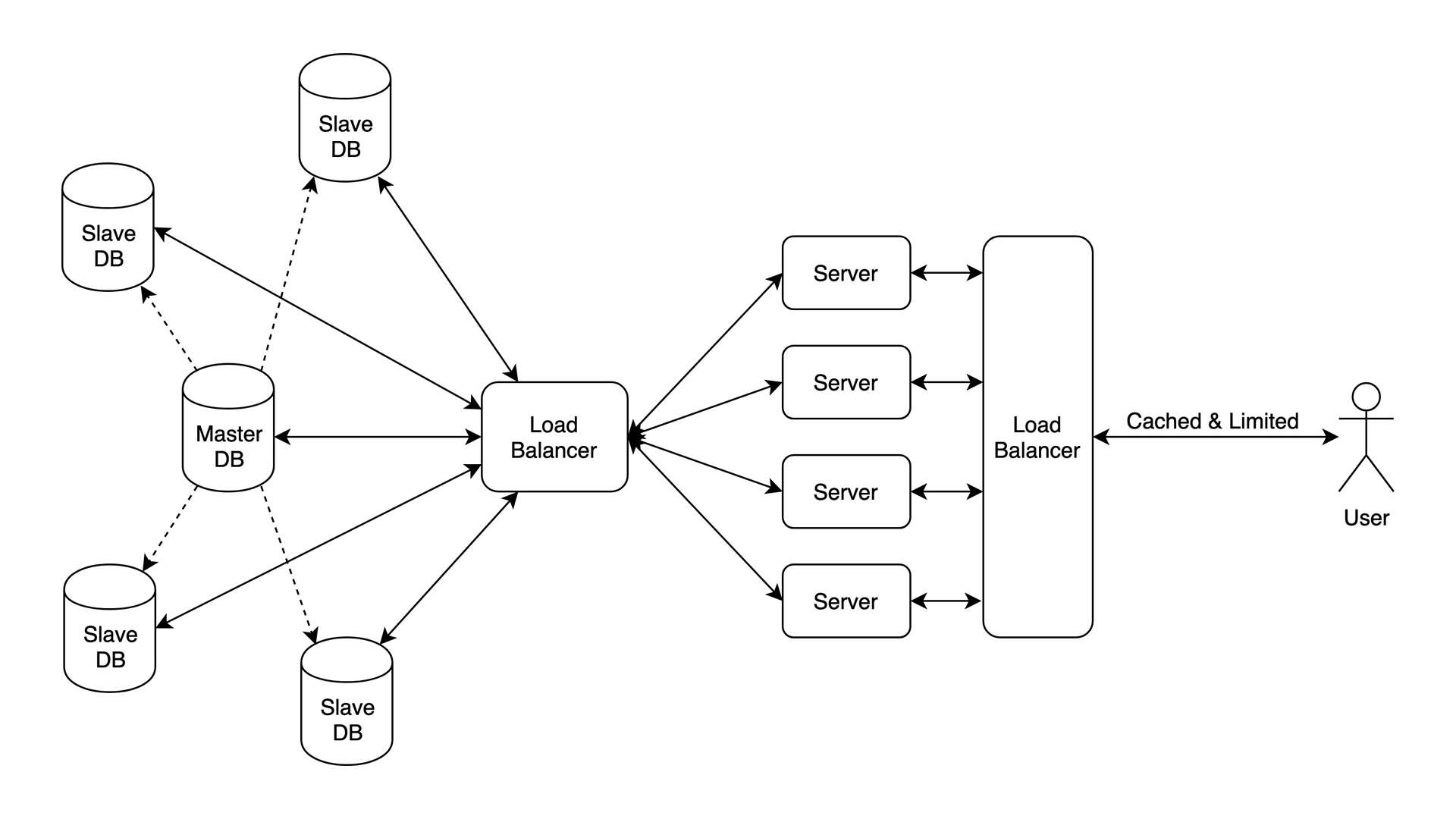
这个架构速度很快,而且可扩展。看它有多漂亮。DB 和后端都做了负载均衡。这里的瓶颈是,当你运行单个服务器或数据中心时,海外用户可能会面临高延迟,因为他们距离很远。但是,这种设置仍然可以应对许多用户,非常适合新闻网站。
数据:数百 TB
用户:上百万
瓶颈:距离。服务器速度很快,但如果用户距离很远,速度也可能会慢
工具:Go、Redis + Cassandra + MongoDB
狮子

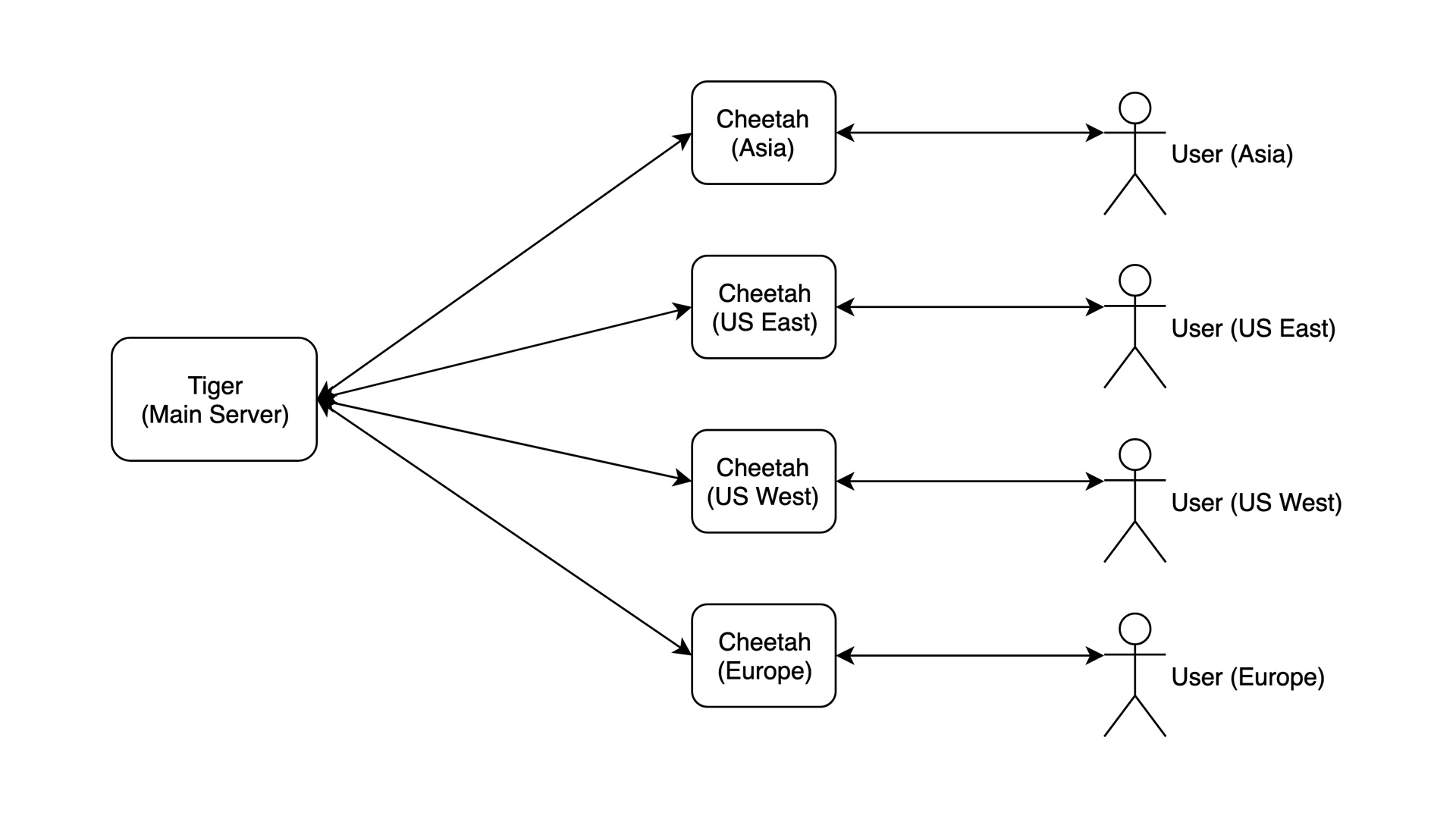
这是一个 CDN——一种完全不同的东西。你在世界各地有多台服务器,它们可以像主服务器一样为请求提供服务。这不像缓存,它们是全功能的。
来自不同大洲的用户通过 DNS 进行隔离。
尽管服务器速度很快,但你仍然受限于一台服务器的容量。你的数据库是主数据库的副本,因此你受限于主数据库的容量。
这非常适合托管提供商、大型电子商务之类的东西。
数据:数百 TB
用户:上千万
瓶颈:大数据量。使用主从复制,无法处理大数据量,你受限于一台 DB 服务器的容量
工具:同上,但 MongoDB 是集群
剑齿虎

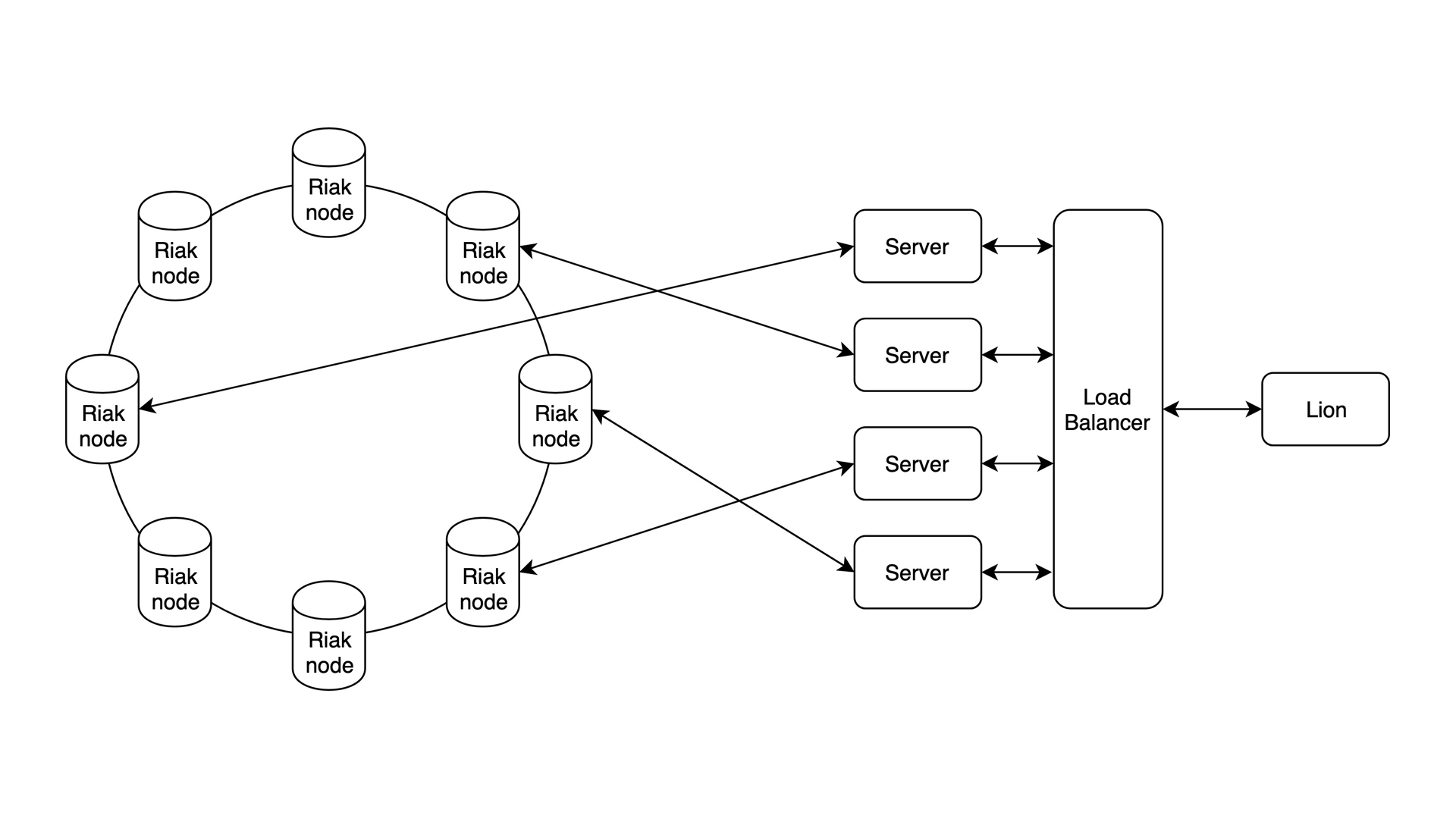
这是终极形式。有了 Riak 这样的图形数据库,容量将不再受限。当存储资源不足时,你只需购买一个新的存储服务器并将其添加进去。
非常适合创建像谷歌或 Facebook 那样的应用。
数据:无限
用户:全球用户
瓶颈:价格。其成本就像太空项目
工具:Go、Riak
总结
我们回顾了几乎每类项目的一些最常见的设置。不一定非要使用上述设置——根据自己的需要进行设计。只要记住,每个工具都有它的用途,务必选择适合你的工作的合适工具。
保证可扩展,保证无状态!
原文链接:




