
2021 年初,Clubhouse 经历了一次爆炸性增长。在两个月的时间里,他们从每分钟不到 1 万次的后台请求增加到超过 100 万次,他们的服务器经历了惊群效应,性能受到极大威胁。这是一个关于 Clubhouse 的工程师如何抑制惊群效应,扩大服务规模和以 3 倍效率运行 Python 工作负载的故事。
请求从每分钟 1 万个上升到 100 万个
2021 年初,Clubhouse 经历了一次爆炸性增长。在两个月的时间里,我们从每分钟不到 1 万次的后台请求增加到超过 100 万次,这要求我们必须迅速适应,以在现有的技术栈中提供每天数十亿次的请求。而且我们只有两名全职的后台工程师(虽然我们仍然很小——我们现在有六个人——欢迎加入我们!)。这是一段关于我们热情时刻的故事,关于我们如何扩大服务规模和以 3 倍效率运行 Python 负载的故事。
我们的 Clubhouse 核心 Web 栈相当简陋——这也是我们故意为之。我们用的是基于 Gunicorn 和 NGINX 的 Python/Django 运维。当开始注意到这种增长时,我们没有太多的时间调整效率,只能不断增加 Web 节点。我们一直都容忍的一个事实是,Django 单体只能在每个实例 30-35%CPU 利用率的条件下才能真正自动扩展(就像许多其他人所记录的那样),注定很浪费(这要怪我们的联合创始人的选择!)。这是一个令人苦恼的假设和限制,但与其他必须扩展和必须救火的事情相比,它并不值得花时间去调查。
所以我们增加了更多的 Web 节点——而且是越来越多的 Web 节点。在超过 1,000 个 Web 实例之前,不断投入机器来解决这个问题的方法还是可行的。但是,当我们突然在我们的 Web 主机上运行一个较大的部署时,因为有了那么多的实例,我们的负载平衡器开始间歇性地超时,并且蓝/绿部署期间的翻转流量让部署 "卡住"了。我们试图与我们的云计算供应商一起追寻超时的原因,但他们也无法找到发生这种情况的根本原因。
一个简单的解决方案是运行更大的实例
这就是我们立即要做的事情。但是,当我们切换到非常大的,有 96 个 vCPU 的实例类型——每个节点上运行 144 个 Gunicorn worker 之后,我们惊奇地发现,在 CPU 利用率仅仅只有 25%时,延迟就开始膨胀。在这个令人尴尬的低阈值下,我们的 p50 延迟急剧上升,节点变得不稳定。
我们被难住了。我们花了几个小时去寻找系统级的限制(无疑,是一些随机的内核限制或资源被我们悄悄地撞上了......)。结果我们的发现更令人震惊:在这些巨大(和昂贵)的机器上,我们的 144 个 Gunicorn 进程中只有 29 个在接收请求!而其他 115 个进程都处于闲置状态。
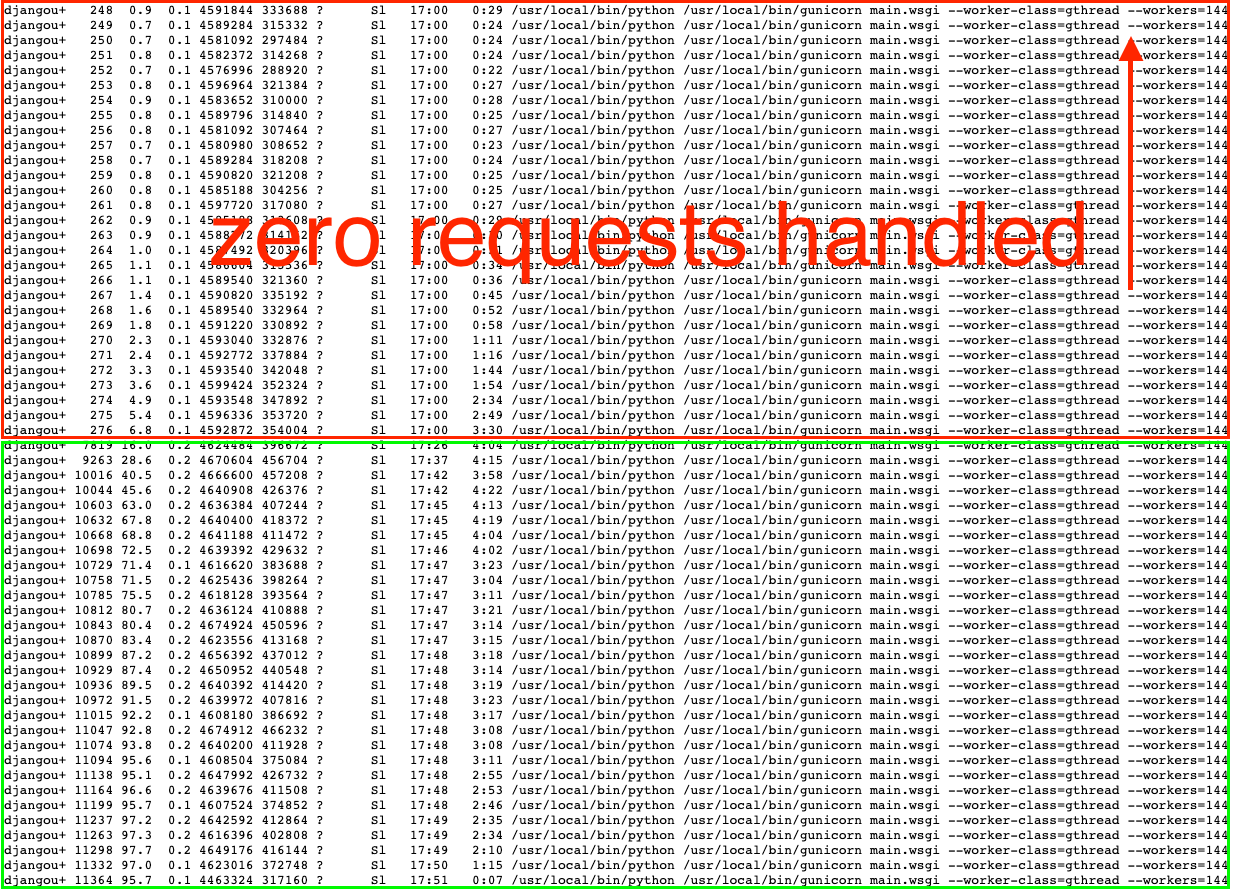
这真是......令人恼火。
事实证明,这是惊群效应(thundering herd)问题的一个例子——当大量的进程试图等待同一个套接字以处理下一个请求时,它就会发生。除非你直面这个问题,否则你最终会做一些幼稚的事情——所有进程都在争夺处理下一个请求,在这个过程中浪费了大量的资源。事实证明,这是 Gunicorn 的一个有据可查的限制。
那么,一个成长中的 Web 服务该怎么做呢?我们需要一个快速的解决方案,这个方案应该只需要很少的工程时间。
尝试 #1:uWSGI
我们的第一个尝试是将我们的 Python 应用服务器从 Gunicorn 切换到 uWSGI,它针对我们的这个问题有个精心设计的内置解决方案(关于它的文档值得一读!)。这个解决方案是一个叫做"--thunder-lock "的标志,它在内核中做了一个非常巧妙的事情,将负载均匀地分散到我们所有的 144 个进程中。
我们迅速部署了 uWSGI 来取代 Gunicorn,令我们高兴的是,平均延迟下降到了一半!现在负载被均匀地分散到所有 144 个进程中。一切都看起来都很好。Slack 上称赞声不绝于耳。这张图看起来很美好!
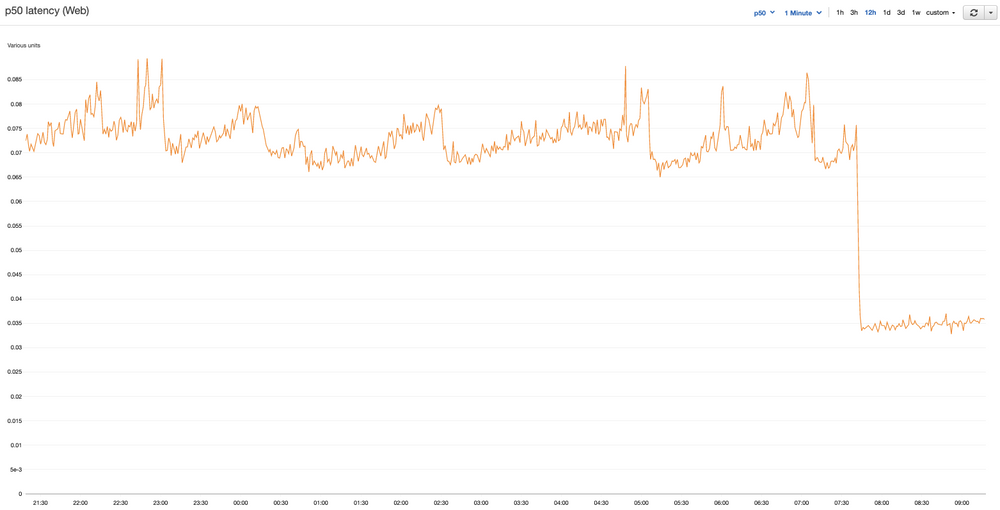
但还有一个大问题没有解决。(当然会有一个问题)。
当我们开始增加流量,超过 Gunicorn 时代神秘的 25%的 CPU 阈值时,我们开始遇到一个更大的问题。uWSGI 套接字会在一些机器上以不可预测的时间间隔锁定。当 uWSGI 被锁住的时候,Web 服务器会在几秒钟内拒绝所有的请求——在这期间我们会看到大量的延迟峰值和 500 报告。这有点坏事,对吧?
这个问题有些神秘。我们在 uWSGI 文档和 StackOverflow 的帖子中匹配神秘问题的日志行,甚至翻译了德语和俄语的帖子,但是没有找到一个合适的证据。
这加剧了另一个问题:uWSGI 太让人困惑了。毫无疑问,它是一个了不起的软件,但它有几十个可以调整的选项。这么多的选项意味着有大量的杠杆可以扭动,但由于缺乏清晰的文档,我们经常需要猜测某个标志的真正意图。
最后,我们无法可靠地重现或缓解这个问题。我们发现 GitHub 上有很多类似这个的问题,这些问题都是随机出现的。
所以 uWSGI 不适合我们。我们又回到了原点:我们怎样才能 100%的利用我们应用服务器的 CPU 呢?
尝试 #2:NGINX
我们深度测试了我们的 uWSGI 问题,就是在每个应用服务器上运行 10 个不同版本的 uWSGI 来减少影响,并通过 NGINX(我们现有的 Web 代理)来平衡它们的负载。我们的想法是,如果其中一个套接字被锁定或崩溃,我们至少只会遭受 10%的损失。
这被证明是错误的,因为 NGINX 的负载平衡功能受到严重的限制。没有任何选项可以限制每个套接字的并发数,也没有任何选项可以防止被挂起的套接字接收新的请求。
这使我们产生了一个问题:我们到底为什么要使用 NGINX?许多真正有用的负载平衡功能是由 "NGINX Plus "控制的,但我们不确定这些功能是否能帮助我们。
就在那时,我们有了一个疯狂的想法。
我们知道 Gunicorn 本身表现地足够好,但它在跨 worker 的负载平衡请求方面却非常差。(这就是为什么我们一开始就看到了 115 个闲置的 worker 进程)。
如果我们不在每台服务器上运行 10 个 Gunicorn 服务器,而是全力以赴地运行整整 144 个独立的 Gunicorn 主进程,每个进程只有一个 Web worker,会怎么样呢?如果我们能找到一种方法,在这些 worker 之间真正实现负载平衡,肯定会产生完美均衡运行的超大型 Web 节点。
尝试之三:HAProxy 来拯救我们!
幸运的是,HAProxy 可以做 NGINX 所能做的一切,而且对我们的用例来说还更合适。它将使我们能够:
在 144 个后端(Gunicorn 套接字)上均匀地分配请求。
以每个后端为单位限制并发量——这样,我们只向每个 Gunicorn 套接字发送一个请求,以避免给它带来压力。
在一个地方排队请求——HAProxy 前端——而不是在每个 Gunicorn 进程中单独的 backlog 上。
在应用服务器和 Gunicorn 套接字的基础上监控并发性、错误率和延迟。
我们使用 supervisord 来启动每个 Gunicorn 套接字,并简单地列出我们 HAProxy 后端中的 144 个 Gunicorn 套接字。
[supervisord] nodaemon=true [program:app] user=djangouser directory=/app command=ddtrace-run gunicorn main.wsgi --workers=1 --timeout 15 -b unix:/var/shared/gunicorn%(process_num)03d.sock --log-file - numprocs=%(ENV_WORKERS)s process_name=%(program_name)s_%(process_num)03d # give processes 180s before killing stopwaitsecs=180 # process needs to run at least 5s before we mark it as "successful" startsecs=5 # log redirect all log output to stdout stdout_logfile=/dev/fd/1 stdout_logfile_maxbytes=0 redirect_stderr=true backend api balance roundrobin option httpchk GET /health timeout check 1000ms # maxconn 1 - only one concurrent connection per gunicorn # maxqueue 1 - only queue one request per socket before attempting other sockets # iter 10s - one health check every 10 seconds # downinter 1s - faster health checks if the socket is marked down # fall 5 - 5 failed health checks (50s) to remove socket # rise 1 - one successful health check adds socket default-server check maxconn 1 maxqueue 1 inter 10s downinter 1s fall 5 rise 1 server gunicorn000 /var/shared/gunicorn000.sock server gunicorn001 /var/shared/gunicorn001.sock server gunicorn002 /var/shared/gunicorn002.sock server gunicorn003 /var/shared/gunicorn003.sock server gunicorn004 /var/shared/gunicorn004.sock server gunicorn005 /var/shared/gunicorn005.sock server gunicorn006 /var/shared/gunicorn006.sock server gunicorn007 /var/shared/gunicorn007.sock server gunicorn008 /var/shared/gunicorn008.sock server gunicorn009 /var/shared/gunicorn009.sock server gunicorn010 /var/shared/gunicorn010.sock server gunicorn011 /var/shared/gunicorn011.sock # and so on...我们验证了这个假设,并挤压测试了单个 96 核的实例,直到 CPU 饱和。在实践中,我们的负载意味着我们在 80%左右的 CPU 利用率时开始经历更高的延迟,由于不均匀的负载导致的临时高峰使机器饱和。(今天,我们选择了比这更低的规模,以确保我们在自动缩放启动之前能够承受 2 倍的爆发 ——但我们很喜欢留一些冗余空间!)
这个解决方案乍一看有点荒唐,但在 Gunicorn 内部做负载均衡,是不是就不那么荒唐了?选择许多较小的 Web 节点也会造成连接池出现各种各样的问题——事实证明,除了更好的 CPU 利用率,拥有真正的大实例对于许多外围原因来说也很好。
我们从中得到的主要启示是什么?
如果 uwsgi thunder-lock 从一开始就很好用——也许可以试一试!它是一个了不起的软件。
如果在你的应用程序前使用 NGINX 作为 sidecar 代理,考虑调整你的配置以使用 HAProxy。作为回报,你会因此得到令人欣喜的监控和队列功能。
Python 为你的应用程序运行 N 个独立的进程的模式并不像人们认为的那样不合理!只要稍加钻研,你可以通过这种方式获得合理的结果。
谢谢你的阅读!
你喜欢同一个小而敏捷的团队来调试这样的问题吗?或者你甚至想帮助我们重新构建整个该死的东西的话——请查看我们的招聘网站或给我发电子邮件:luke@clubhouse.com。
—— Luke Demi,软件工程师
原文链接:https://blog.clubhouse.com/reining-in-the-thundering-herd-with-django-and-gunicorn/




