一、前言
AI 技术包含训练和推理两个阶段。推理阶段的性能好坏既关系到用户体验,又关系到企业的服务成本,甚至在一些极端应用上(比如无人驾驶)直接关系到个人生命财产安全。目前 AI 落地面临的挑战主要来源于两方面,一方面是 AI 算法的日新月异,带来了计算量的猛增,从 AlexNet 到 AlphaGo,5 年多的时间里计算量提升了 30w 倍。另一方面是底层硬件异构化的趋势愈发明显,近年来涌现出非常多优秀的架构来解决 AI 计算力问题。推理引擎的首要任务就是将性能优异且计算量庞大的深度学习框架快速部署到不同的硬件架构之上,并且能够保持性能相对高效。然而纵观开源社区和闭源解决方案,没有任何一款推理引擎可以同时满足开源、跨平台、高性能三个特性。因此,我们结合百度实际业务的需求、百度优秀工程师的研发能力以及行业合作伙伴的大力支持共同完成了百度自己的推理引擎 Anakin v0.1.0。Anakin 目前支持 Intel-CPU、NVIDIA-GPU、AMD-GPU 和 ARM 平台,后续将支持更多平台如寒武纪、比特大陆等。今天 Anakin 正式开源,期望能够借助社区的力量把 Anakin 打造的更加精美!
二、 Anakin 架构
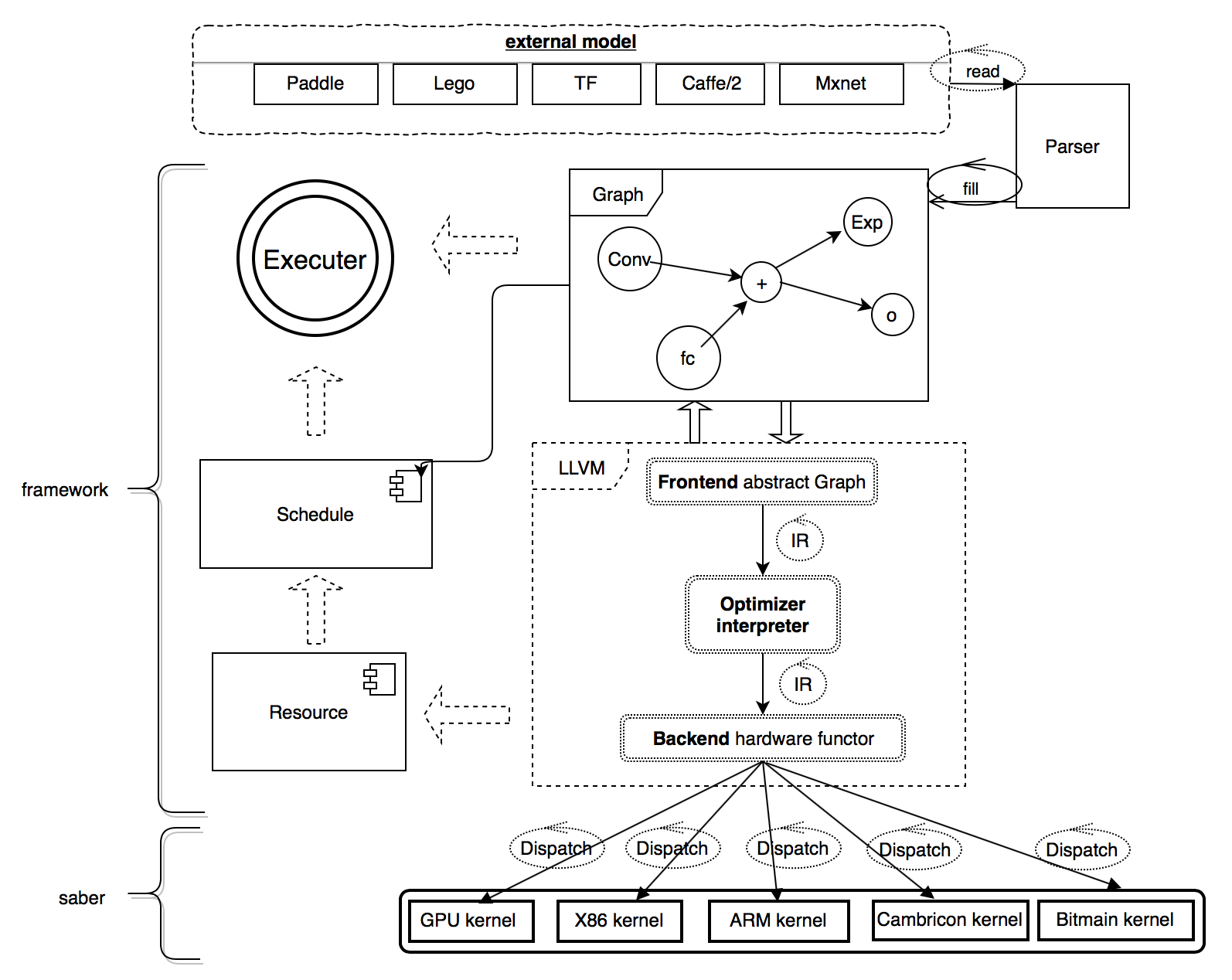
图 1 Anakin 框架
Anakin 框架的核心逻辑如图 1 所示,主要由 Parser, Framework 和 Saber 组成。Parser 是独立解析器,用于将不同训练框架生成的模型转化为统一的 Anakin 图描述。Framework 是框架主体,使用 C++ 实现,用于完成硬件无关的所有操作,比如构建网络、图融合、资源复用、计算调度等。Saber 是一个高效的跨平台计算库,包括大量的汇编级优化代码,并支持众多国际行业合作伙伴的架构,如 Intel-cpu,NV-gpu,AMD-gpu 和 ARM 等,同时以后还将支持寒武纪 MLU100 和比特大陆 BM1682 这两款优秀的国产芯片。
三、 Anakin 功能特性
Anakin v0.1.0 具有开源、跨平台、高性能三个特性,它可以在不同硬件平台实现深度学习的高速推理功能。Anakin 在 NV、Intel、ARM 和 AMD-GPU 架构上,体现了低功耗、高速预测的特点。
1. 支持众多异构平台 - 跨平台
Anakin 广泛的和各个硬件厂商合作,采用联合开发或者部分计算底层自行设计和开发的方式,为 Anakin 打造不同硬件平台的计算引擎。目前 Anakin 已经支持了多种硬件架构,如 Intel-CPU、NVIDIA-GPU、AMD-GPU、ARM 等,未来将会陆续支持比特大陆、寒武纪深度学习芯片等等不同硬件架构。我们希望 Anakin 可以为用户提供更灵活的底层选择,更方便简单的部署方式,并在不同底层硬件上达到最优性能。
2. 高性能
Anakin 在众多硬件平台都有很好的性能收益, 本文列举了一些实验对比测试数据,更详尽的数据请参见: https://github.com/PaddlePaddle/Anakin/tree/developing/benchmark
- 在 NV 架构上,我们选择 Anakin v0.1.0、TensorRT v3.0.0、Tensorflow v1.7.0 和 Caffe v1.0.0 进行了对比,具体的对比结果如图 2 所示。
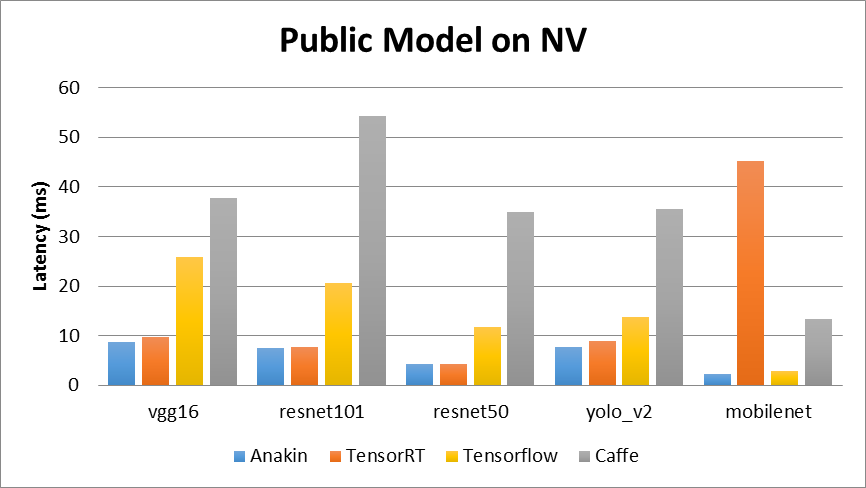
图 2 Public model on NV
测试平台 Nvidia-P4 信息:
- GPU Architecture NVIDIA Pascal™
- Single-Precision Performance 5.5 TFLOPS
- GPU Memory 8 GB
- 在 Intel 架构上,我们选取 Tensorflow-v1.8.0 进行对比,具体的对比结果如图 3 所示。
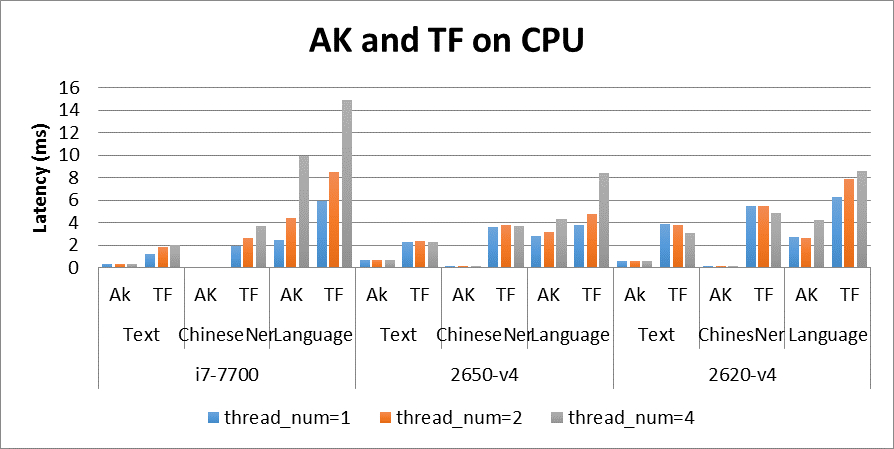
图 3 Anakin and Tensorflow on CPU
测试平台信息:
- i7-7700:Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz
- 2650-v4:Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz
- 2620-v4:Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
- 在移动端 ARM 上,我们选取 Tensorflow-lite 进行对比,具体的对比结果如图 4 所示:
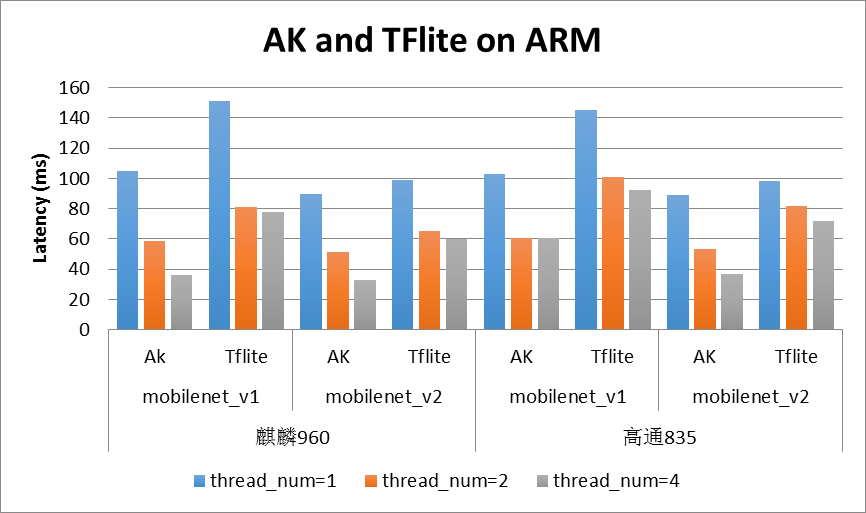
图 4 Anakin and TFlite on ARM
测试平台信息:
- 荣耀 v9(root): 处理器: 麒麟 960, 4 big cores in 2.36GHz, 4 little cores in 1.8GHz
- 高通 835, 4 big cores in 2.36GHz, 4 little cores in 1.9GHz
- 在 AMD-GPU 架构上,我们选取 Anakin-v0.1.0 进行横向对比,具体的对比结果如图 5 所示:
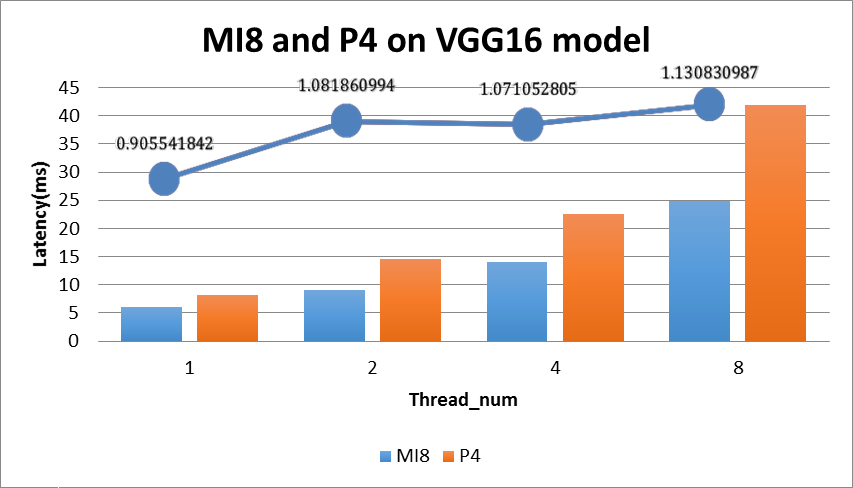
图 5 MI8 and P4 on VGG16 model
测试平台信息:
MI8: AMD Radeon Instinct MI8
- single-Precision Performance 8.192 TFLOPS
- GPU Memory 4 GB
P4: GPU Architecture NVIDIA Pascal™
- Single-Precision Performance 5.5 TFLOPS
- GPU Memory 8 GB
图 5 中的折线图表示 MI8 和 P4 的执行效率的相对比例,具体的计算公式:
P4_Latency * P4_TFLOPS / (MI8_Latency * MI8_TFLOPS);
从图上的折线可知 Anakin 在 MI8 和 P4 上执行效率非常接近,在 Thread_num 大于 2 时 Anakin_MI8 效率更高。
3. 汇编级的 kernel 优化
Anakin 追求的目标是极致,因此它提供了一套基于 NVIDIA GPU SASS 汇编级优化的库。SASS 库支持多种(如 sm61,sm50)NVIDA GPU 架构的汇编实现的 conv 和 gemm 的核心计算。由于和 NVIDIA 商业保密协议规定,目前只能开源编译好的 SASS 库
四、Anakin 值得一提的技术亮点
- 轻量的 dashboard
Anakin v0.1.0 框架中的 Parser 提供了一个额外的小功能,可以让开发者查看 Anakin 优化前后的网络结构及参数,如图 6 和图 7 所示。这样有助于开发者方便的分析模型。同时,在优化后的 Anakin 执行图中会添加相应的优化标记,主要包括 memory 复用、op 融合、并行度分析、执行顺序分析、存储器使用以及同步标记等。例如,在图 7 中,对于标记了 New 标签的地方,在代码运行过程中,将只会对这些内容分配内存。这种处理方式将使得 Anakin 运行时所需的 memory 更少。
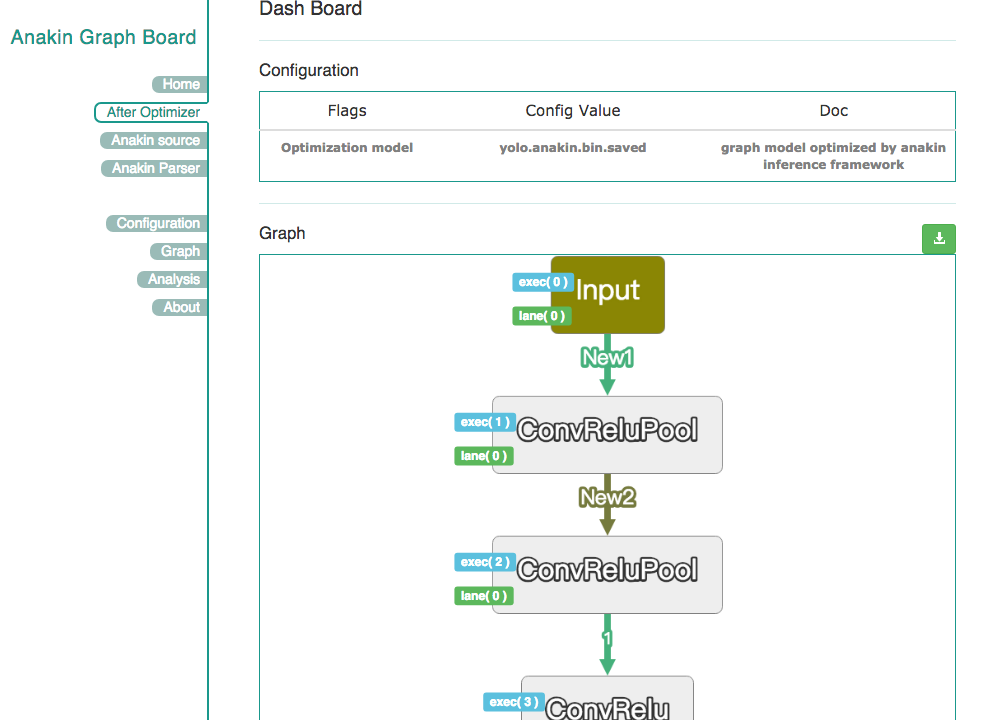
图 6 优化前的网络结构图
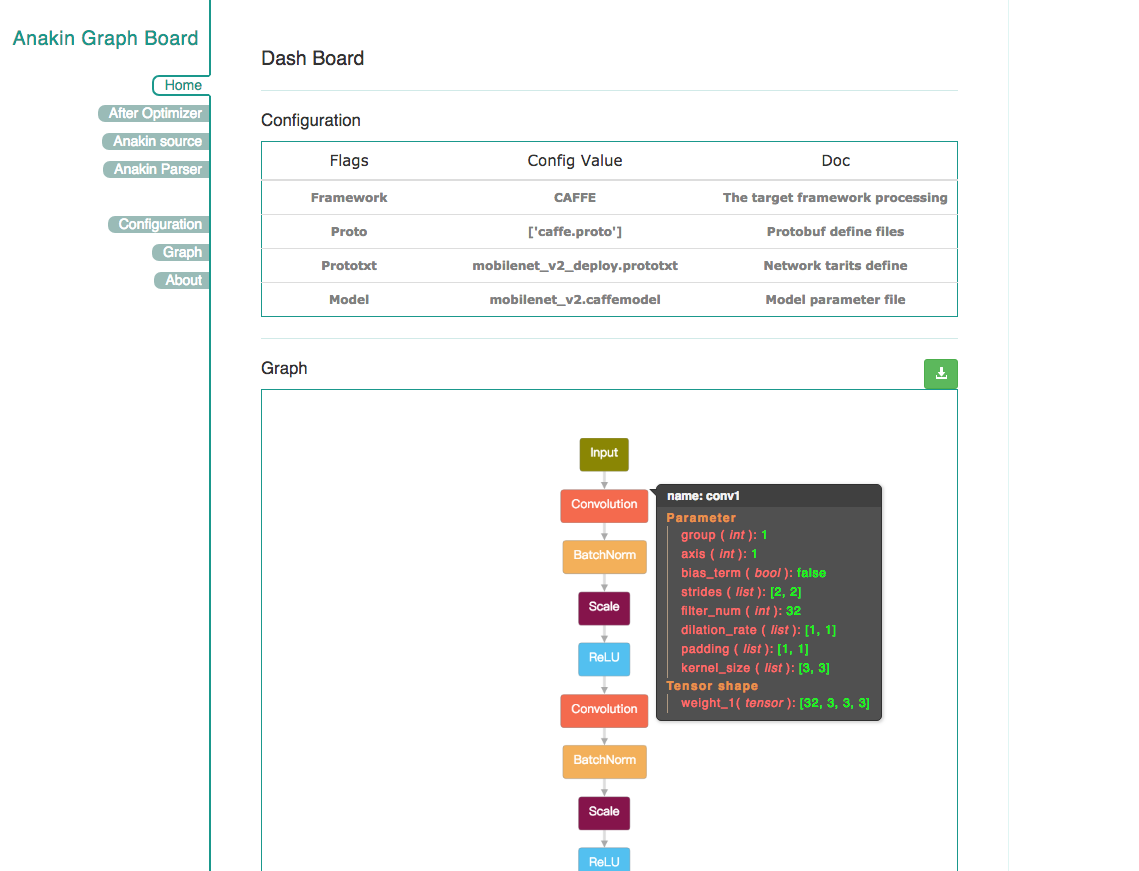
图 7 优化后的网络结构图
- Anakin-lite 轻量的移动端版本
Anakin 还提供了在移动端运行的轻量版本 anakin-lite, 我们借助上层图优化机制,帮助深度学习模型 code 自动生成,针对具体模型自动生成的可执行文件,并且结合针对 ARM 专门设计的一套轻量接口,合并编译生成模型的 lite 版本。
Anakin-lite 保持精简化,全底层库大小经过剪裁只有 150K 左右,加上自动生成的深度学习模型模块,总大小在 200K。模型参数不再采用 protobuf 而是精简的 weights 堆叠的方式,尽可能减小 model 尺寸。同时,anakin-lite 依然保有上层 anakin 框架的优化分析信息(比如存储复用等),最终可以做到内存消耗相对较小,模型尺寸相对精简。
- Anakin 多层次的应用
第一个层次:Anakin 可以是一个计算库;
第二个层次:Anakin 可以是一个独立的推理引擎;
第三个层次:Anakin 可以通过 Anakin-rpc 构建一个完整的推理服务。
五、Anakin 的发展前景
Anakin v0.1.0 具有开源、跨平台、高性能三个特性,它可以在不同硬件平台实现深度学习的高速推理功能。对于每个开发厂商,仅仅使用一套 Anakin 框架,就能在不同的硬件服务器上实现快速推理。
Anakin 的终极目标是帮助实际业务模型快速迭代和上线,为深度学习模型产业化落地扫清障碍,从而让广大的工程师更专注算法设计,从繁重的优化和工程中解脱出来,进而推动深度学习的哪怕一点点的进步,这就是我们最大的愿望。




