Auth0 是一家认证、授权和 SSO 服务提供商。近期,Auth0 完成将自身架构从三家云提供商(即 AWS、Azure 和 Google Cloud)转向 AWS 一家,这是因为它的服务越来越依赖于 AWS 服务。现在,Auth0 的系统分布在 4 个 AWS 域(Region)中,其中服务是跨区(Zone)复制的。
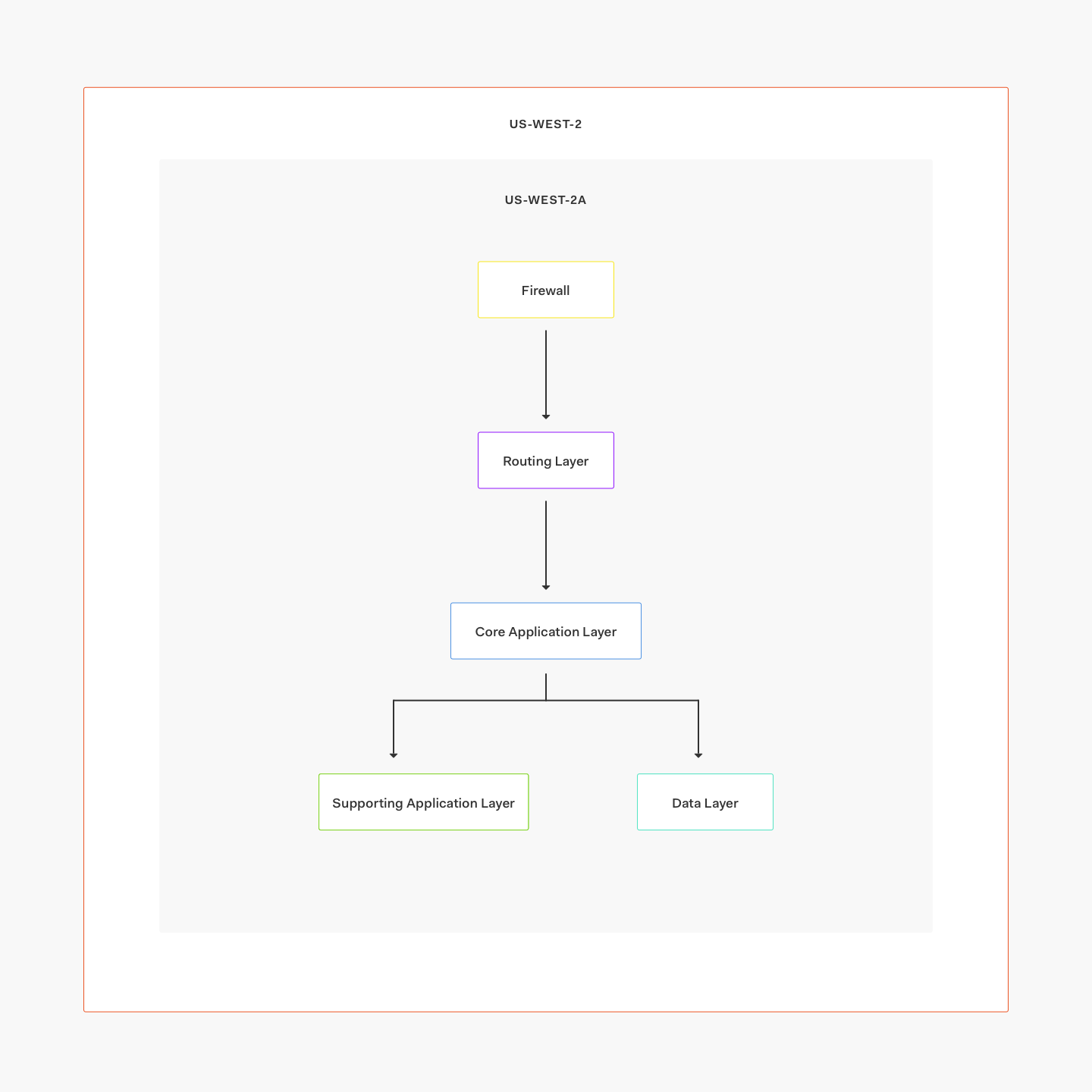
Auth0 在设计上支持运行在本地部署和云上。在过去的四年中,其系统扩展到每月服务超过15 亿次登录操作,所提供的服务也从10 种增加到30 种。同时,服务器数量从单个AWS 域中的数十台,增长到跨四个AWS 域中的一万多台。其架构中包括了一个以提供各种服务自动扩展组为后端的路由层,以及一个使用MongoDB、Elasticsearch、Redis 和PostgreSQL 的存储层,该存储层支持 Kinesis 流处理系统和 RabbitMQ、 SNS、SQS 等消息队列。
最初,Auth0 架构是跨 Azure 和 AWS 的,还有一小部分部署在 Google Cloud 上。 Azure 在一开始是作为主域,而 AWS 则用于故障转移。之后,二者的角色发生了互换。由于云间的故障转移是基于DNS 的,这意味着TTL 必须非常低,以使得客户在故障转移发生时可以快速切换。据Auth0 产品经理 Dirceu Tiegs 在企业技术博客上撰文介绍,“当我们开始使用更多的AWS 资源时,例如Kinesis 和SQS 等,为保持两个云服务提供商提供对等的特性,我们遇到了一些麻烦”。Azure 确实曾提供类似于SQS 的服务,称为Azure Service Bus。虽然博客中并未提及哪些AWS 服务在Azure 中缺失对等服务,但是存在一些情况使得特定AWS 域中缺少服务。为此, Auth0 技术团队曾撰文介绍他们是如何使用替代服务的。
Auth0 在 2016 年曾发生了一次掉线故障,它们部署在 AWS 上的 VPN 终端开始丢弃来自于 Azure 和 GCE 的网络包。当时,Auth0 的数据库集群使用了所有三家云服务提供商。由于存在上述问题,导致 AWS 的主数据库节点不能接收到来自于 Azure 的心跳网络包。随后团队恢复尝试服务,所有集群节点将自身标记为后备节点,服务因而受到了影响。DNS 配置错误是导致问题的一个原因。由此,团队最终决定将 AWS 作为首要的云服务提供商,最小化部署在 Azure 的认证服务支持,只是在 AWS 宕机时使用。
图片来源: https://auth0.com/blog/auth0-architecture-running-in-multiple-cloud-providers-and-regions/
在 Auth0 的 AWS 架构中,包括数据库在内的所有服务运行在同一个域(Region)的三个可用区(AZ,Availability Zone)中。如果一个AZ 发生故障,那么其它两个AZ 将会继续提供服务。如果整个域发生故障,那么AWS 的DNS 服务 Route53 就会更新网络域名去指向另一个可用的域。一些服务相比于其它服务需要有更高的可用性保证。例如,尽管基于 Elasticsearch 的用户搜索服务可能会使用到一些过期的数据,但是所有核心功能并不会受此影响。数据库层在组成上包括了跨域的 MongoDB 集群、用于 PostgreSQL 的 RDS 复制以及部署在每个域中的 Elasticsearch 集群。
Auth0 在 2017 年之前运行着自己的 CDN ,之后转移到使用 CloudFront。企业自开发的 CDN 以 Amazon S3 为支持,使用 Varnish 和 nginx 构建。转移到 CloudFront 使得企业降低了维护工作,并且更易于配置。
Auth0 的监控最初使用 Pingdom 实现,此后企业开发了自己的健康检查系统,该系统运行node.js 脚本,并通过Slack 发布通知。企业当前的技术栈包括了Datadog、CloudWatch、Pingdom 和Sentinel。时序度量由Datadog 采集并发送给Slack,其中一小部分发送给PagerDuty。Slack 还用于实现符合 ChatOps 协作模型的任务自动化。日志处理流水线使用 Amazon Kinesis、Elasticsearch 和 Kibana 收集应用日志。Sumologic 用于记录审计跟踪数据和 AWS 生成的日志。




