绝大多数人应该都用过滴滴、Uber 等叫车 App,所以在线叫车已经成为日常出行的一种方式。而运满满是货车和货源的模式,和滴滴有相似之处,也存在很多差异。货车司机以往是去线下的配货站找货,现在在运满满 App 上就可以寻找周边货源。
目前运满满有 520W 司机和 125W 货主用户。货运行业有其特殊性,我们也很荣幸能采访到运满满 CTO 王东老师,从运满满最初的架构迭代,到技术中台的搭建,到当前的 AI 技术的应用,整体上了解货运平台的技术积累。同时,王东老师也会在 7 月 6 日的深圳 ArchSummit 全球架构师技术峰会上演讲《如何打造活力、持续创新的研发团队》话题。
王东说,之前一个司机从南京拉货到上海,需要在上海卸货之后再去配货站找货,而且能看到的货源也仅限于与该配货站关系好的工厂货物,很多因素会导致司机要多等待半天到一天,以至于经常会空驶回南京。
基于运满满平台,司机能看到整个上海到南京的货源情况,甚至从上海周边到南京周边的货源,这就提升了司机的选择余地,极大的降低了空驶,也提高了车货匹配的效率,在热门线路货主发出送货需求几分钟之内就能找到对应的司机。
现在平台上的大部分运单运费并没有从运满满平台内走,运满满通过提供额外的保障,一体化服务的优势来吸引用户在线上完成运费的支付过程。
与此同时,王东还说,运满满正研究无人驾驶在干线物流领域的应用,已经组建了无人驾驶事业部,集团也为用户提供了全方位如 ETC,油,保险,贷款等服务。
现在这一切看上去都很美好,但是回望来时的路,不甚感慨,灭掉了很多问题,但还有更多的问题需要消灭。
一直在打“遭遇战”
2017 年运满满和货车帮合并后成立满帮集团,整个集团不论是业务体系还是技术体系都在飞速发展。为了更好的为司机和货主服务,集团各个业务、团队开始融合。融合的过程中,业务上既要满足不停歇的新业务需求,还要不断地升级系统以确保稳定性。合并之后和货车帮的技术团队很好的配合一起来完成这件事是一个挑战。结果只用了 3 个月就实现了系统融合并上线,双方团队的匠心精神充分展现。
最开始运满满的系统架构设计比较简单:单体应用,一个 war 包包含了所有服务端接口,没有做服务化拆分,各模块严重耦合。随着业务量快速增长,在高峰时段系统访问量快速攀升,系统不断出现问题甚至宕机,很难诊断出问题在哪里。后来启动了服务化拆分、中心化建设。同时技术架构上开始大量使用缓存,以及数据库读写分离。App 重构项目、安全攻坚项目、运维自动化项目、Docker 化项目、稳定性体系项目也紧随其后。
系统架构迭代
第一次迭代是“服务化拆分”。运满满初期是一个单体应用,随着业务的发展开始隐隐暴露出研发效率与稳定性难以权衡的痛点,为避免业务进入高速发展时期对技术团队带来的冲击,研发团队启动了服务化拆分项目。对于系统的更新,我们从研发效率与稳定性两个基本要求出发,分析关键路径,隔离业务变化与资源体量,整体规划面向分布式系统的全链路监控。从系统复杂度、服务分级,以及业务领域对团队配合度的要求这几个方面,对团队进行盘点、重组和扩充。这个过程虽然花了很多时间与精力去分析系统,洞察团队,但事实证明这为后续的工作奠定了坚实的基础。
第二次迭代是“稳定性保障体系与业务服务中台”。在运满满系统全量服务化后,研发效率、性能、稳定性得到了巨大的提升,业务也在这个阶段进入了高速爆发期。然而,随着服务化大幅增加了系统复杂度,线上故障的定位难度与恢复时长也随之提高。研发团队围绕着故障预演、发现、止损、定位与恢复规划并落地了统一流控熔断降级、流量调度、动态分组、自动化破坏性测试、全链路 Trace、线上变更事件流等能力,大幅降低了故障数量与恢复时长。
同样,系统复杂度的提升给研发效率也造成了不小的冲击,大量业务服务中存在相似或相同的逻辑,随着对业务领域的逐渐深入,我们规划并逐步沉淀业务服务中台,以数据模型抽象化配置化,业务逻辑引擎化的思路, 使大量前端业务系统的共性与差异化转变为中台调用的选项参数,以及配置能力的使用。比如用户平台、货源平台、推荐排序平台。
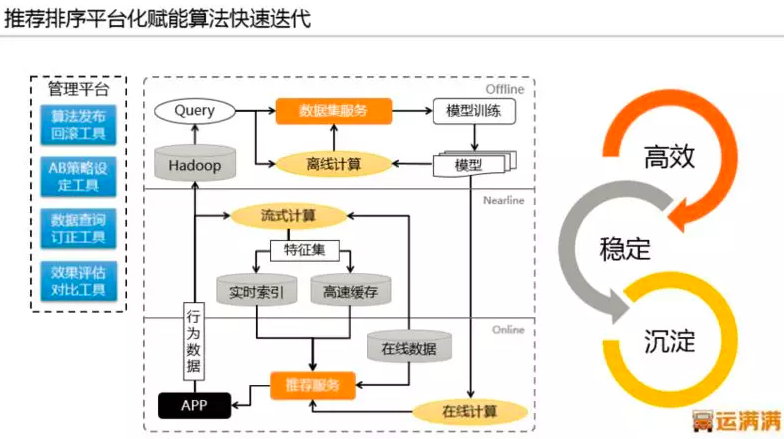
大道至简的分布时代应对策略
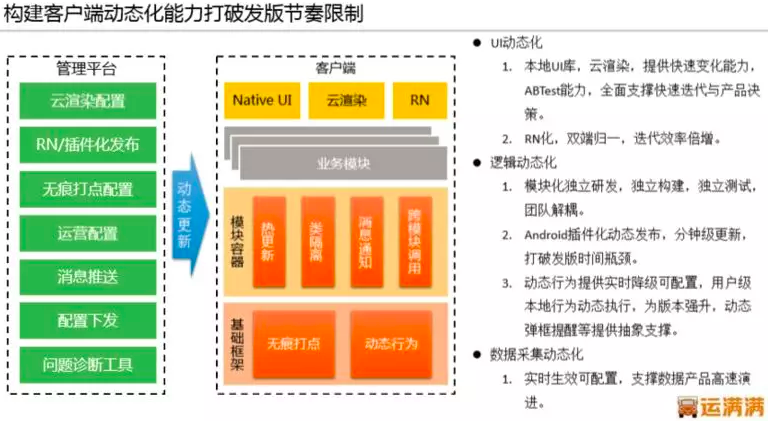
因为行业特殊性,缺少前车之鉴的参考,王东说,他们确实遇到了很多挑战,一些看似合理的产品逻辑与平台规则,在用户看来却没法解决他们的问题,反应很强烈。在一切摸着石头过河的阶段,对技术架构的快速应变能力是相当大的考验,客户端在这个问题上凸显尤为严重。客户端发版到用户最终更新需要一个长周期,如果完全依赖静态发版,版本更新周期内所有问题基本束手无策。为了快速响应业务变化,运满满对客户端动态能力建设下了很大的功夫,例如 React,动态降级 H5,安卓插件化,无痕打点。这需要大量的客户端标准化工作以及完备的基础能力建设,并且还需要建立对应的管理平台增加各能力管理的易用性。
另外,用户群体内大多数人对智能手机了解不够,例如 Push 收不到,没声音等手机设置问题都需要客服去协助解决。为此,我们在客户端内置了强大的问题自诊断工具,针对安卓系统的碎片化问题,这类工具的研发需要对症下药定制进行适配,达到的效果也很喜人,上线后每周此类问题的咨询量降低了两个数量级。为了降低管理成本与人员成本,这种快速应变能力在服务端同样重要,这正是业务服务中台能力的体现,非常重要。
大放异彩的算法技术
算法技术在车货之间进行匹配,最大程度降低空驶率,节省时间,提升效率上发挥了重大作用。那它和普通的车人匹配性质有何不同呢?
王东说,这就要谈到匹配的场景和特色。车货匹配在广义上,也是撮合交易的一种。如同电商、打车。在平台产品上的展现形态,也以推荐、排序、订单匹配为主。但车货匹配有极其独特的特点,比如货源是无库存的唯一品和非标准品。“唯一品”指的是每宗货源几乎各不相同,运输方案、时间各有变化,而且一次性成交后就立刻下线,完全不同于商城的热点商品推荐原则。非标准品是指,货源对车辆是有要求的,而且在不同时间、线路、种类上计价方式也不同。这一点也和打车出行场景的车人匹配有着重大差异。日常出行的车人匹配的场景是局部区域在较短时间窗口内满足供需,而车货匹配则是长时间大区域内的匹配 – 毕竟货运计划可以长达一个月,车辆的行驶里程远大于日常打车场景。
算法技术,确实是以在这种强约束条件下取系统最优为目标的。迭代过程中,伴随算法的框架也做了大规模的升级,从数据采集存储、计算,到 T+1、T+0 的服务。实际上,算法解决了匹配方面的这几个子问题:车货基础相关性(CTR 模型),货源路线和司机画像,司机的预估行驶距离和时间(ETA 模型),区域内供需关系预测和价格模型,路线 / 货源相似性等。算法上,我们在离线部分使用 XgBoost 来处理基础相关性,用 RNN 做行驶时间预估,用 LSTM 来做时间序列预测,在线学习我们用基于 FTRL 独立发展的自研算法来处理。
从结果来说,发货信息上线的瞬间,就能准确预测潜在的车主,并进行正确的推送,40% 的货源在 30 分钟内就能建立司机到货主的联系,60% 的货源在 2 小时之内成交。大大节省了司机找货的时间成本。而且运满满还提供了大量回程甚至多路径中转回程的推荐。这些都对匹配效率,降低空驶起到了重要作用。
机器学习和深度学习的广泛采用
运满满利用大规模的数据采集,实时运算,借助机器学习和深度学习技术,建立了全网最优为目标的匹配和调度方案,大幅提升运输效率(匹配,速度,节油)。
其平台的使用流程为:货主通过 App 发布货源信息,司机通过 App 筛选出符合运输条件的货源。由于在线货源的数量巨大,司机需要浏览大量货源,或频繁切换筛选条件才能找到真正合适的货源。因此开发了实时货源推荐系统和基于车辆货源供需的调度系统,来提高司机的搜货效率以及提升平台整体的成交率。除了个性化匹配外,实时性也是推荐的重点考虑要素。
具体技术细节,运满满使用 Xgboost 来预测车 - 货的基础相关性,实际是一个 CTR 和 CVR 混布模型,其中部署了在线实时系统,自研了一套基于 FTRL 算法的在线学习算法,将用户实时的行为数据结果和 Xgboost 的离线结果共同训练而得,点击预测的准确率超过 90%。但是“全网最优”的概念并不代表匹配速度最快。
货源尤其如此,有明显的好货与坏货的区分,因此要兼顾“效率 + 公平 + 业务目标”。比如在一个阶段内以 30 分钟反馈为业务目标。此外,还要考虑运输计划和车辆调度。又涉及到路线调度、ETA、供需预测等范畴。比如 ETA 是基于如下的 ETA cost 场景:为货主寻找合适的车辆,是不能通过周边车辆的直线距离来计算成本的,也要考虑限行、道路情况、天气季节、车辆状态来综合计算。那么在这里使用 RNN 来处理分裂后数千特征的输入,对到达时间的成本进行预测就是非常有效的一种方法。
因为以“全网最优”为目标,所以我们需要整合各个子系统以及相关的算法模型,如下:
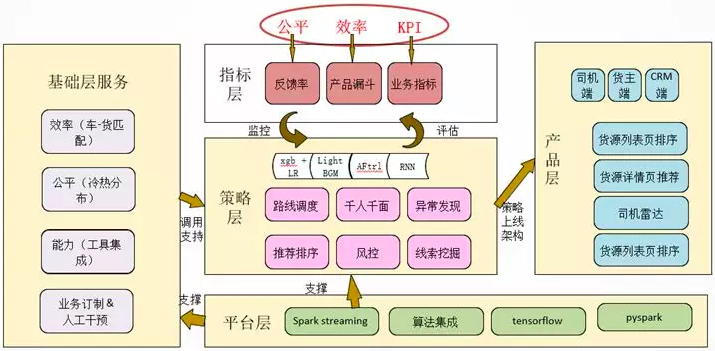
数据和算法产生了很大的经济价值也是很直观的:

ArchSummit 全球架构师技术峰会即将召开,了解更多有意思的技术话题: https://sz2018.archsummit.com/schedule
嘉宾介绍:
 王东:运满满 CTO。资深技术专家与管理者,曾先后负责过 10 多条亿级用户的产品研发管理工作,历任天猫高级技术专家、360 高级总监、百度主任架构师,有过两次创业经验。
王东:运满满 CTO。资深技术专家与管理者,曾先后负责过 10 多条亿级用户的产品研发管理工作,历任天猫高级技术专家、360 高级总监、百度主任架构师,有过两次创业经验。
热爱并信仰技术,技术功底深厚擅长分布式系统架构、海量数据拆分和分析、缓存和静态化技术使用、性能调优、无线端性能和动态化技术。并一直保持着对技术的热情和最前沿技术的探索。




