Github.com 使用 MySQL 作为其许多关键服务的主干,如对外 API,身份验证和 Github.com 网站本身。 Github 的工程师团队用基于 Orchestrator,Consul 和 Github 负载均衡器的设置替换了之前基于 DNS 和 VIP 的设置以脑裂和 DNS 缓存问题。
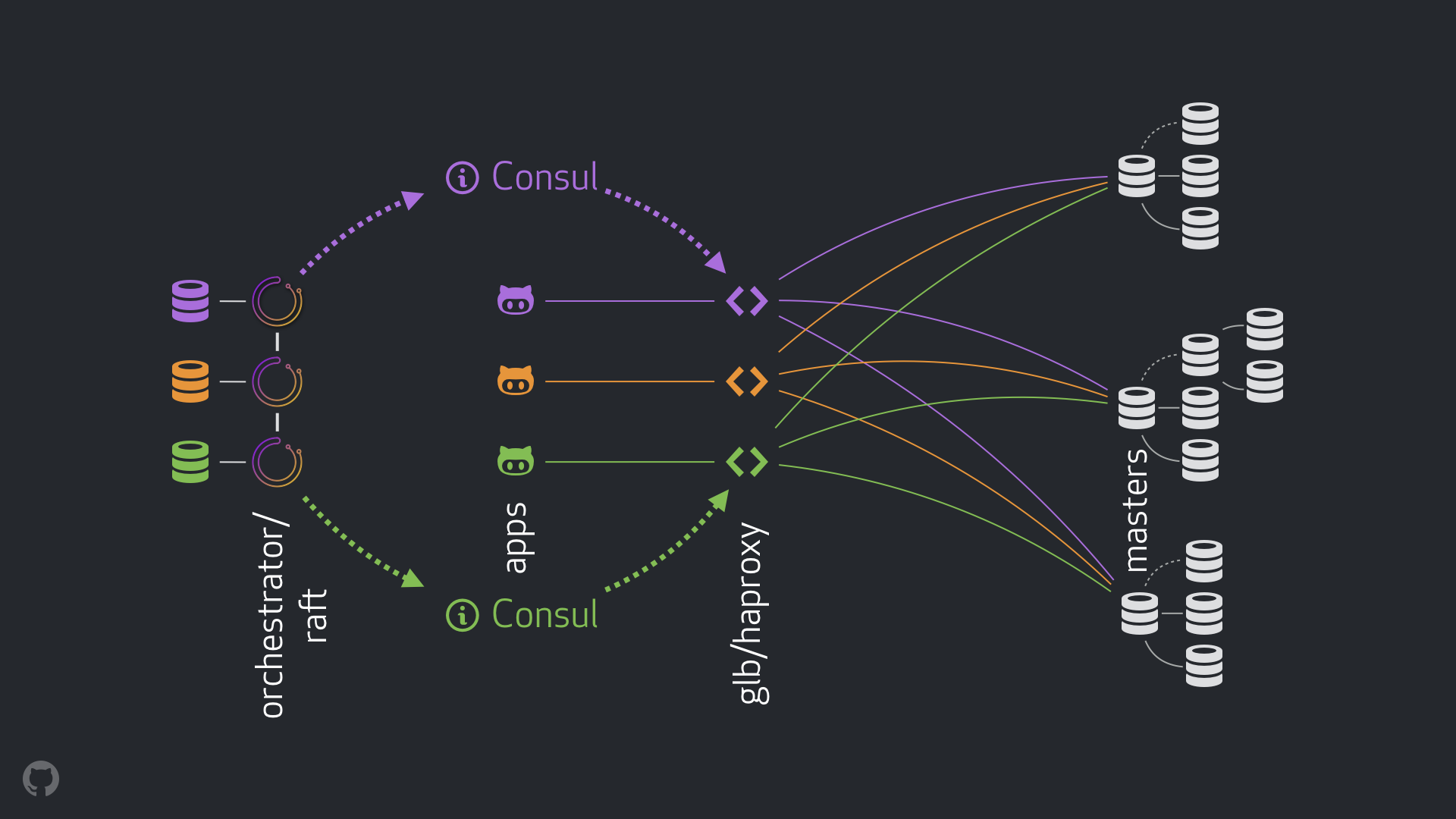
Github 为不同的服务和任务运行多个 MySQL 集群,因此必须使它们具有高可用性。 Github 的基础架构分布在多个数据中心,包括大约 15 个集群,近 150 个生产服务器和 15 TB 的 MySQL 表。每个 MySQL 集群都有一个主节点,它响应写入请求,以及多个从节点,它们是主节点的副本并提供读取请求。主节点形成单点故障,没有它,写入将完全失败。此设置的高可用要求包括自动检测故障,将从节点自动升级到主节点以及将新主节点自动通告给客户端应用程序。
多年来,Github 的工程师团队为 HA 尝试了多种策略,逐渐整个组织在策略上得到了统一。由于这不仅限于 MySQL,因此对 HA 解决方案要求包括跨数据中心可用性和脑裂预防。 MySQL 主发现有不同的可能方法。以前,Github 利用 DNS 和虚拟 IP 地址(VIP)来发现 MySQL 主节点。客户端应用程序将连接到固定主机名,DNS 将解析该主机名以指向虚拟 IP(VIP)。 VIP 允许将流量路由到不同的主机以提供移动性,而无需将其绑定到单个主机。 VIP 将始终由当前主节点拥有。但是,在故障转移事件(包括脑裂情况)期间,VIP 获取和释放过程存在潜在问题。发生这种情况时,两个不同的主机可以拥有相同的 VIP,并且流量可以路由到错误的主机。此外,必须进行 DNS 更改才能处理位于不同数据中心的主节点,并且由于客户端的 DNS 缓存而需要时间来传播。
Github 的最新设置包括 Orchestrator 工具包,Consul 用于服务发现和 Github 负载均衡。在此体系结构中,当客户端应用程序通过其名称在 DNS 上查找主服务器的 IP 时,它将通过 Anycast 解析。使用 Anycast 的优势在于,虽然名称在每个数据中心被解析为相同的 IP 地址,但是到该 IP 的客户端流量将路由到最近的主服务器。最近的主服务器是共同位于同一数据中心的主服务器。这个路由由 GLB 处理,GLB 知道当前活动的 MySQL 主后端。
图片来源: https://githubengineering.com/mysql-high-availability-at-github/
Orchestrator 也是一个 Github 开源项目,负责主故障检测和故障转移过程。它利用从包括副本在内的所有 MySQL 节点中获取的信息来得出关于主控状态的决策。当写主机发生故障时,Orchestrator 领导节点会检测到故障并启动故障转移过程以选择新的 MySQL 主机。其余的 Orchestrator 集群节点会注意到此更改,并使用新的详细信息更新其本地 Consul 守护进程。 Consul 是 Hashicorp 的服务发现工具,它通过将主节点存储为键值对来跟踪主节点。 Consul 可以跨数据中心以分布式模式运行,但在 Github 的情况下,每个 Consul 集群在数据中心级别是独立的。使用 Consul Template 向 GLB 通知故障转移事件的主状态更改,Consul Template 查询 Consul 集群并更新 GLB 状态,GLB 状态又将流量路由到新主服务器。
在文章中,Github 的高级基础设施工程师 Shlomi Noach 提到,虽然新设置在大多数情况下提供了“10 到 13 秒”的最大停机时间,但有些情况需要更多时间,例如数据中心隔离导致 故障转移时的脑裂或停电。 Github 的新设置是从基于网络的传统技术转向基于代理和服务发现的技术。 它完全取代了基于 VIP 的方案,但是围绕使用边界网关协议(BGP)采用不同方法是否更容易存在争议。
查看英文原文: https://www.infoq.com/news/2018/07/github-mysql-high-availability




