更多左耳朵耗子的独家干货,请订阅极客时间出品的陈皓全年专栏《左耳听风》,一次订阅、永久阅读。即日起,戳此订阅立享以下两大福利:
福利一:原价 ¥199/ 年,极客时间新用户注册立减 ¥30
福利二:每邀请一位好友购买,你可获得 36 元现金返现,多邀多得,上不封顶,立即提现(提现流程:极客时间服务号 - 我的 - 现金奖励提现)
看新闻很累?看技术新闻更累?试试下载 InfoQ 手机客户端,每天上下班路上听新闻,有趣还有料!
本文摘自陈皓(左耳朵耗子)在极客时间 App 上开始的全年付费专栏《左耳听风》,已获授权。欲阅读更多独家文章,请点击此处订阅专栏阅读(支持微信支付)。
我前面写的《分布式系统架构的本质》系列文章,从分布式系统的业务层、中间件层、数据库层等各个层面介绍了高并发架构、异地多活架构、容器化架构、微服务架构、高可用架构、弹性化架构等,也就是所谓的“纲”。通过这个“纲”,你能够按图索骥,掌握分布式系统中每个部件的用途与总体架构思路。
为了让你更深入地了解分布式系统,在接下来的几期中,我想谈谈分布式系统中一些比较关键的设计模式,其中包括容错、性能、管理等几个方面。
- 容错设计又叫弹力设计,其中着眼于分布式系统的各种“容忍”能力,包括容错能力(服务隔离、异步调用、请求幂等性)、可伸缩性(有 / 无状态的服务)、一致性(补偿事务、重试)、应对大流量的能力(熔断、降级)。可以看到,在确保系统正确性的前提下,系统的可用性是弹力设计保障的重点。
- 管理篇会讲述一些管理分布式系统架构的一些设计模式,比如网关方面的,边车模式,还有一些刚刚开始流行的,如 Service Mesh 相关的设计模式。
- 性能设计篇会讲述一些缓存、CQRS、索引表、优先级队列、业务分片等相关的架构模式。
我相信,你在掌握了这些设计模式之后,无论是对于部署一个分布式系统,开发一个分布式的业务模块,还是研发一个新的分布式系统中间件,都会有所裨益。
今天分享的就是《分布式系统设计模式》系列文章中的第一篇《弹力设计篇之“认识故障和弹力设计”》。
系统可用性测量
对于分布式系统的容错设计,在英文中又叫 Resiliency(弹力)。意思是,系统在不健康、不顺,甚至出错的情况下有能力 hold 得住,挺得住,还有能在这种逆境下力挽狂澜的能力。
要做好一个设计,我们需要一个设计目标,或是一个基准线,通过这个基准线或目标来指导我们的设计,否则在没有明确的基准线的指导下,设计会变得非常不明确和不可预测或不可测量。可测试和可测量性是软件设计中非常重要的事情。
我们知道,容错主要是为了可用性,那么,我们是怎样计算一个系统的可用性的呢?下面是一个工业界里使用的一个公式:
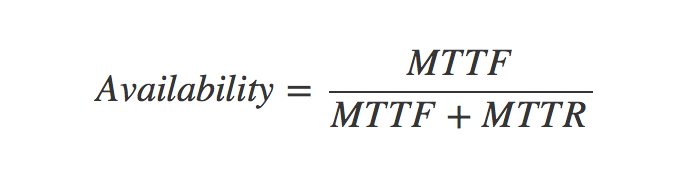
其中,
- MTTF 是 Mean Time To Failure,平均故障前的时间,即系统平均能够正常运行多长时间才发生一次故障。系统的可靠性越高,MTTF 越长。(注意:从字面上来说,看上去有 Failure 的字样,但其实是正常运行的时间。)
- MTTR 是 Mean Time To Recovery,平均修复时间,即从故障出现到故障修复的这段时间,这段时间越短越好。
这个公式就是计算系统可用性的,也就是我们常说的,多少个 9,如下表所示。
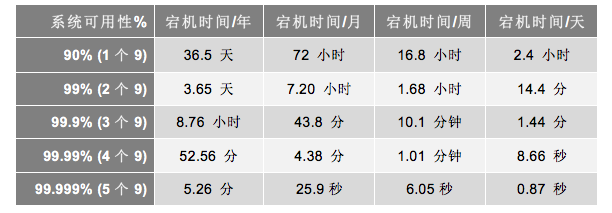
根据上面的这个公式,为了提高可用性,我们要么提高系统的无故障时间,要么减少系统的故障恢复时间。
然而,我们要明白,我们运行的是一个分布式系统,对于一个分布式系统来说,要不出故障简直是太难了。
注:以上仅为文章的一部分,欲阅读全文,请点击此处订阅专栏(支持微信支付)。一次订阅,永久阅读。




