看新闻很累?看技术新闻更累?试试下载 InfoQ 手机客户端,每天上下班路上听新闻,有趣还有料!
Criteo 公司 SRE 团队的一位成员在上个月召开的 FOSDEM 大会上做了一个演讲,介绍了他们如何使用Cassandra 作为存储后端实现Graphite 产品的规模化安装。为实现容错和弹性扩展,Criteo 工程团队编写了一个称为“ BigGraphite ”的 Graphite 用户化插件,替代了 Cassandra 默认使用的 WhisperDB。
Criteo 需要解决容错和弹性扩展问题,这是已被分布式数据库解决的问题。Criteo 团队决定使用 Graphite 的插件架构,编写支持使用 Cassandra 为存储后端的定制插件。该插件作为“ BigGraphite ”项目开源。项目在设计中考虑了支持多种后端,但是目前只提供对 Cassandra 的支持。
Whisper 是 Graphite 推出的默认数据库,它采用固定大小的文件存储数据。文件的大小固定,因为 Graphite 在存储数据时指定了一个预先配置的保留期限,通常更旧的数据以更低的采集频率存储。Criteo 的度量采集横跨具有超过两万台服务器的六个数据中心,每秒写入80 万个数据点。团队维护了两千多个仪表盘,以及一千多种报警,每隔五分钟做一次度量评估。Graphite 的默认配置(包括存储后端)并不能满足这样配置的需求。据报告介绍,除了“每种度量对应一个文件”模型存在大量浪费的问题之外,Graphite 的集群并非十分稳健,也不是“真正可弹性扩展的”。此外,Whisper 中操作数据模型所用的命令行工具运行速度慢,性能脆弱。
图片来源:演讲中使用的幻灯片
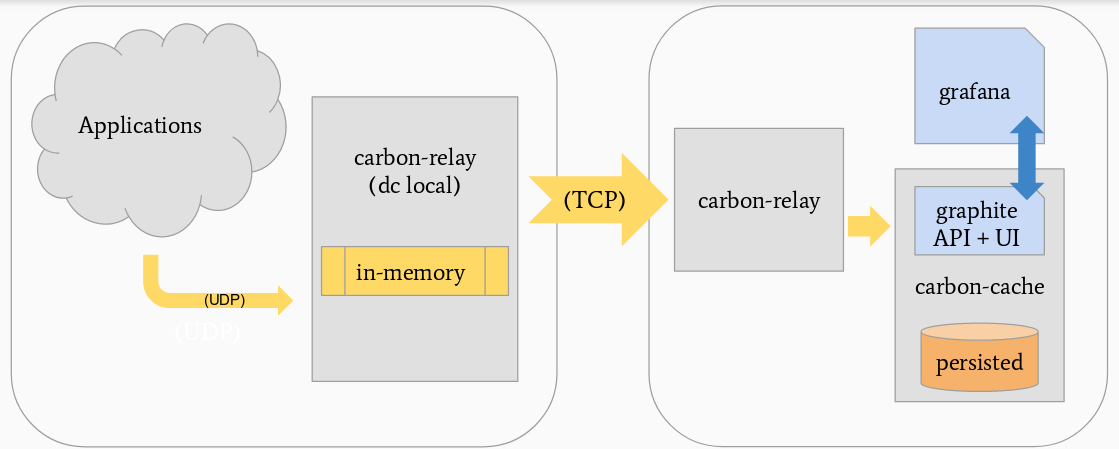
在BigGraphite 架构中,有一个Carbon 中继,它将来自于数据中心的事件发送给写入Cassandra 的Carbon 缓存过程。Carbon 中继也实现复制功能,并通过将数据推送给多个Carbon 缓存过程实现分片功能,度量数据由Carbon 缓存过程写入到磁盘。转移到BigGraphite 架构还包括改为使用Graphite Web UI。
演讲中还介绍了Cassandra 的时序模式,但是并未详细介绍如何存储或查询给定度量的标签。 Cassandra 表中的每行数据都包括度量名称和开始时间戳,并以此作为主键,列键使用与开始时间戳的偏移量。Graphite 根据数据所处的保留阶段存储度量数据,例如,为期七天并且每分钟采集一次的数据、为期六个月并且每天采集一次的数据,诸如此类。更早期的度量数据使用聚合函数计算,这反映在 Criteo 团队对 Cassandra 表的设计中。对于一个给定的度量,实现有多个表,其中每个表用于一个给定的保留阶段,即对于一个给定的时期,应存储何种采集频率的数据点。
除了 Cassandra 之外,团队还测评了多种时序数据存储,包括 OpenTSDB 、 Cyanite 、 KairosDB 和 InfluxDB 。Criteo 团队并未采用 OpenTSDB,因为 OpenTSDB 采用 HBase 为后端,但是团队已经为其它用途使用了 HBase 集群,难以在该集群之外再建立一个 HBase 集群。其它选项在完成测评时尚未具备部分所需的特性,因此同样未得到采用。
当前 Criteo 的 Cassandra 集群运行有 20 个节点。团队正致力于引入 Prometheus ,并构建各个系统间的联系纽带。
查看英文原文: Scaling Graphite at Criteo Using a Cassandra Backend




