看新闻很累?看技术新闻更累?试试下载 InfoQ 手机客户端,每天上下班路上听新闻,有趣还有料!
本篇文章选自极客时间“赵成运维体系管理课” 付费专栏中的其中一篇,专栏内容主要聚焦在分布式软件架构下的应用运维这个领域,更多的是作者对运维的一些架构思考,主要分成四部分: 应用运维体系建设、效率和稳定性等方面的最佳实践、云计算方面的思考和实践以及个人成长与趋势热点分析。专栏详情请点击查看。
今天我来讲一下微服务架构模式下的一个核心概念:应用。
我会从这几个方面来讲:应用的起源、应用模型和应用关系模型建模以及为什么要这样做。最终希望,在微服务的架构模式下,我们的运维视角一定转到应用这个核心概念上来,一切要从应用的角度来分析和看待问题。
应用的起源
我们知道,微服务架构一般都是从单体架构或分层架构演进过来的。软件架构服务化的过程,就是我们根据业务模型进行细化的过程,在这个过程中切分出一个个具备不同职责的业务逻辑模块,然后每个微服务模块都会提供相对应业务逻辑的服务化接口。
如果解释得简单点,就一个字,拆!如下图,从一个单体工程,拆分出 N 个独立模块。
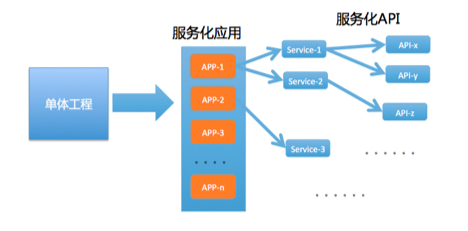
这些模块可以独立部署和运行,并提供对应的业务能力。拆分后的模块数量与业务体量和复杂度相关,少则几个、十几个,多则几十、几百个,所以为了统一概念,我们通常称这些模块为应用。
为了确保每个应用的唯一性,我们给每个应用定义一个唯一的标识符,如上图的 APP-1、APP-2 等,这个唯一标识符我们称之为应用名。
接下来,这个定义为应用的概念,将成为我们后续一系列微服务架构管理的核心概念。
应用模型及关系模型的建立
上面我们定义出来的一个个应用,都是从业务角度入手进行拆分细化出来的业务逻辑单元。它虽然可以独立部署和运行,但是每一个应用都只具备相对单一的业务职能。如果要完成整体的业务流程和目标,就需要和周边其它的服务化应用交互。同时,这个过程中还需要依赖各种与业务无直接关系、相对独立的基础设施和组件,比如机器资源、域名、DB、缓存、消息队列等等。
所以,除了应用这个实体之外,还会存在其他各类基础组件实体。同时,在应用运行过程中,还需要不断地与它们产生和建立各种各样复杂的关联关系,这也为我们后续的运维带来很多困难。
那接下来,我们要做的就是应用模型以及各种关系模型的梳理和建立,因为只有模型和关系梳理清楚了,才能为我们后面一系列的运维自动化、持续交付以及稳定性保障打下一个良好的基础。
1. 应用业务模型
应用业务模型,也就是每个应用对外提供的业务服务能力,并以 API 的方式暴露给外部,如下图商品的应用业务模型示例:
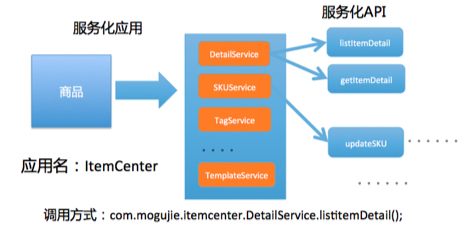
这个业务模型通常都是业务架构师在进行业务需求分析和拆解时进行设计,更多的是聚焦在业务逻辑上,所以从运维的角度,我们一般不会关注太多。
而接下来的几部分,将是运维要重点关注的内容。
2. 应用管理模型
应用管理模型,也就是应用自身的各种属性,如应用名、应用功能信息、责任人、Git 地址、部署结构(代码路径、日志路径以及各类配置文件路径等)、启停方式、健康检测方式等等。这其中,应用名是应用的唯一标识,我们用 AppName 来表示。
这里我们可以把应用想象成一个人,通常一个人会具备身份证号码、姓名、性别、家庭住址、联系方式等等属性,这里身份证号码,就是一个人的唯一标识。
3. 应用运行时所依赖的基础设施和组件
- 资源层面:应用运行所必需的资源载体有物理机、虚拟机或容器等,如果对外提供 HTTP 服务,就需要虚 IP 和 DNS 域名服务;
- 基础组件:这一部分其实就是我们所说的中间件体系,比如应用运行过程中必然要存储和访问数据,这就需要有数据库和数据库中间件;想要更快地访问数据,同时减轻 DB 的访问压力,就需要缓存;应用之间如果需要数据交互或同步,就需要消息队列;如果进行文件存储和访问,就需要存储系统等等。
从这里我们可以挖掘出一条规律,那就是这些基础设施和组件都是为上层的一个个业务应用所服务的。也正是因为业务和应用上的需求,才开启了它们各自的生命周期。如果脱离了这些业务应用,它们自己并没有单纯存在的意义。所以,从始至终基础设施和组件都跟应用这个概念保持着紧密的联系。
理清了这个思路,我们再去梳理它们之间的关系就会顺畅很多,分为两步。
第一步,建立各个基础设施和组件的数据模型,同时识别出它们的唯一标识。这个套路跟应用管理模型的梳理类似,以典型的缓存为例,每当我们申请一个缓存空间时,通常会以 NameSpace 来标识唯一命名,同时这个缓存空间会有空间容量和 Partition 分区等信息。
第二步,也是最关键的一步,就是识别出基础设施及组件可以与应用名 AppName 建立关联关系的属性,或者在基础组件的数据模型中增加所属应用这样的字段。
还是以上面的缓存为例,既然是应用申请的缓存空间,并且是一对一的关联关系,既可以直接将 NameSpace 字段取值设置为 AppName,也可以再增加一个所属应用这样的字段,通过外键关联模式建立起应用与缓存空间的关联关系。
相应地,对于消息队列、DB、存储空间等,都可以参考上面这个思路去做。
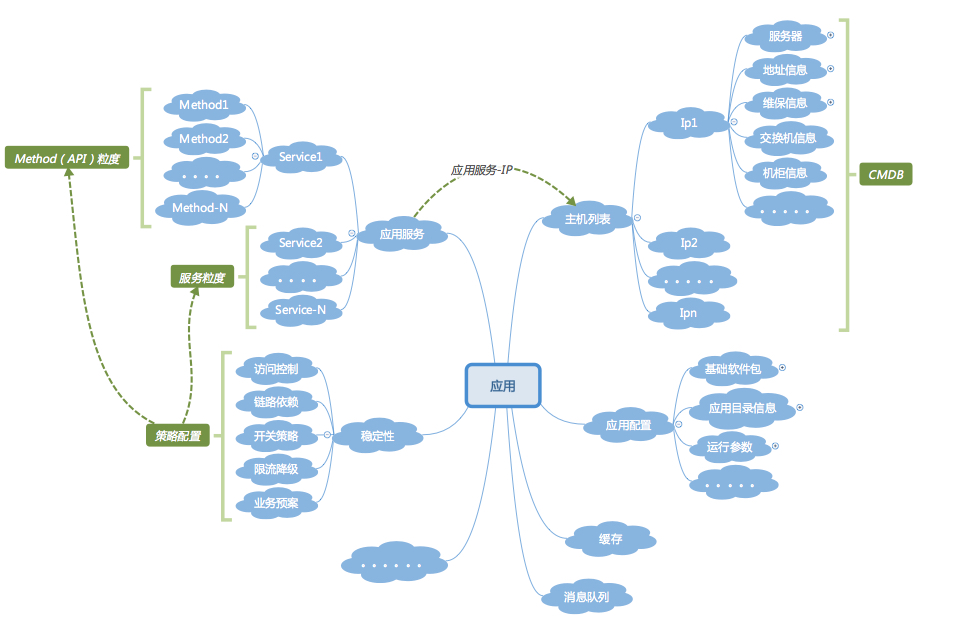
通过上面的梳理,我们就可以建立出类似下图这样的以应用为核心的应用模型和关联关系模型了,基于这个统一的应用概念,系统中原本分散杂乱的信息,最终都被串联了起来,应用也将成为整个运维信息管理及流转的纽带。
真实的情况是怎么样的?
上面讲了这么多理论和道理,但是我们业界真实的现状是怎样的呢?
从我个人实际观察和经历的场景来看,大部分公司在这块的统筹规划是不够的,或者说是不成熟的。也就是软件架构上引入了微服务,但是后续的一系列运维措施和管理手段没跟上,主要还是思路没有转变过来。虽然说要做 DevOps,但实际的执行还是把开发和运维分裂了去对待,不信你看下面两个常见的场景。
- 场景一
这个场景是关于线上的缓存和消息队列的。
开发使用的时候就去申请一下,一开始还能记住自己使用了哪些,但是时间一长,或者申请得多了,就记不住了。久而久之,线上就存在一堆无用的 NameSpace 和 Topic,但是集群的维护者又不敢随意清理,因为早就搞不清楚是谁用的,甚至申请人已经离职,以后会不会再用也已经没人讲得清楚了,越往后就越难维护。
根本原因,就是前面我们讲到的,太片面地对待基础组件,没有与应用的访问建立起关联关系,没有任何的生命周期管理措施。
- 场景二
这个典型场景就体现了应用名不统一的问题。
按照我们前面讲的,按说应用名应该在架构拆分出一个个独立应用的时候就明确下来,并贯穿整个应用生命周期才对。
但是大多数情况下,我们的业务架构师或开发在早期只考虑应用开发,并不会过多地考虑整个应用的生命周期问题,会下意识地默认后面的事情是运维负责的,所以开发期间,只要将应用开发完和将服务注册到服务配置中心上就 OK 了。
而到了运维这里,也只从软件维护的角度,为了便于资源和应用配置的管理,会独立定义一套应用名体系出来,方便自己的管理。
这时不统一的问题就出现了,如果持续交付和监控系统这些运维平台也是独立去开发的,脱节问题就会更严重。
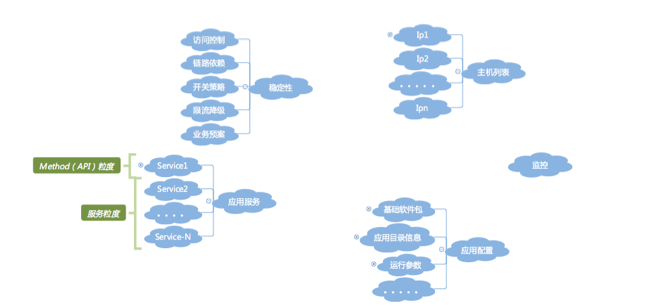
如下图所示,一个个的孤岛,无法成为体系,当这些系统需要对接时,就会发现需要做大量的应用名转化适配工作,带来非常多无谓的工作量,所谓的效率提升就是一句空话。
所以,今天一开头我就提到,微服务架构模式下的运维思路一定要转变,一定要将视角转换到应用这个维度,从一开始就要统一规划,从一开始就要将架构、开发和运维的工作拉通了去看,这一点是与传统运维的思路完全不同的。
当然,这里面也有一个经验的问题。虽然微服务在国内被大量应用,但是我们绝大多数技术团队的经验还集中在开发设计层面。微服务架构下的运维经验,确实还需要一个总结积累的过程。我自己也是痛苦地经历了上面这些反模式,才总结积累下这些经验教训。
这也是为什么我今天分享了这样一个思路,我们要转换视角,规划以应用为核心的运维管理体系。
不知道你目前是否也遇到了类似的问题,如果今天的内容对你有帮助,也请你分享给身边的朋友。
欢迎你留言与我一起讨论。
作者简介
赵成,美丽联合集团技术服务经理,公众号“Forrest 随想录”的作者,多届 ArchSummit 运维专题明星讲师和优秀出品人,EGO 杭州分会会员。目前专注于云计算和人工智能时代的运维转型和提升。2018 年 1 月在极客时间上开设“赵成运维体系管理课”。专栏详情请点击查看。





