Gremlin 公司发布了 Gremlin ,一种基于 SaaS 的“恢复能力即服务”(Resilience as a Service)平台。Gremlin 支持企业通过“按需破坏系统”开展混沌(Choas)实验,这样有助于在应用发生停机故障前预防问题的发生。Gremlin 使得企业可以在所管理的基础设施中注入一些受控的资源、网络和状态故障,以便工程师查看在此类故障条件下系统的运作行为。Gremlin 还提供了一个“撤销”按钮,一旦出现问题即可自动清除注入故障。
自去年以来,混沌工程和恢复能力测试的理念日益流行,而 Netflix 等先驱对此已摇旗呐喊了相当长的时间。 Netflix 的 Chaos Monkey ,以及相关的 Simian Army 系列工具,已经成为相当主流的工具。此外,最近也有不少会议演讲是以混沌为主题。但是要使用混沌技术,通常需要高层级的基础设施和操作技能、实验的设计和执行能力,以及一些可用的资源,并且由于混沌工程不能破坏生产环境,因此还需要以受控方式手动编排故障场景。
Gremlin 平台提供了一种基于 Web 的 GUI,用于在已安装 Gremlin 守护进程(代理)的计算设备上执行和管理混沌实验。在 Linux 上,守护进程可以使用 Debian 和 RPM 软件包安装。对于那些在容器中运行应用的企业,Gremlin 还提供了用于 Docker 的安装选项(附带对 Kubernetes 的支持)。
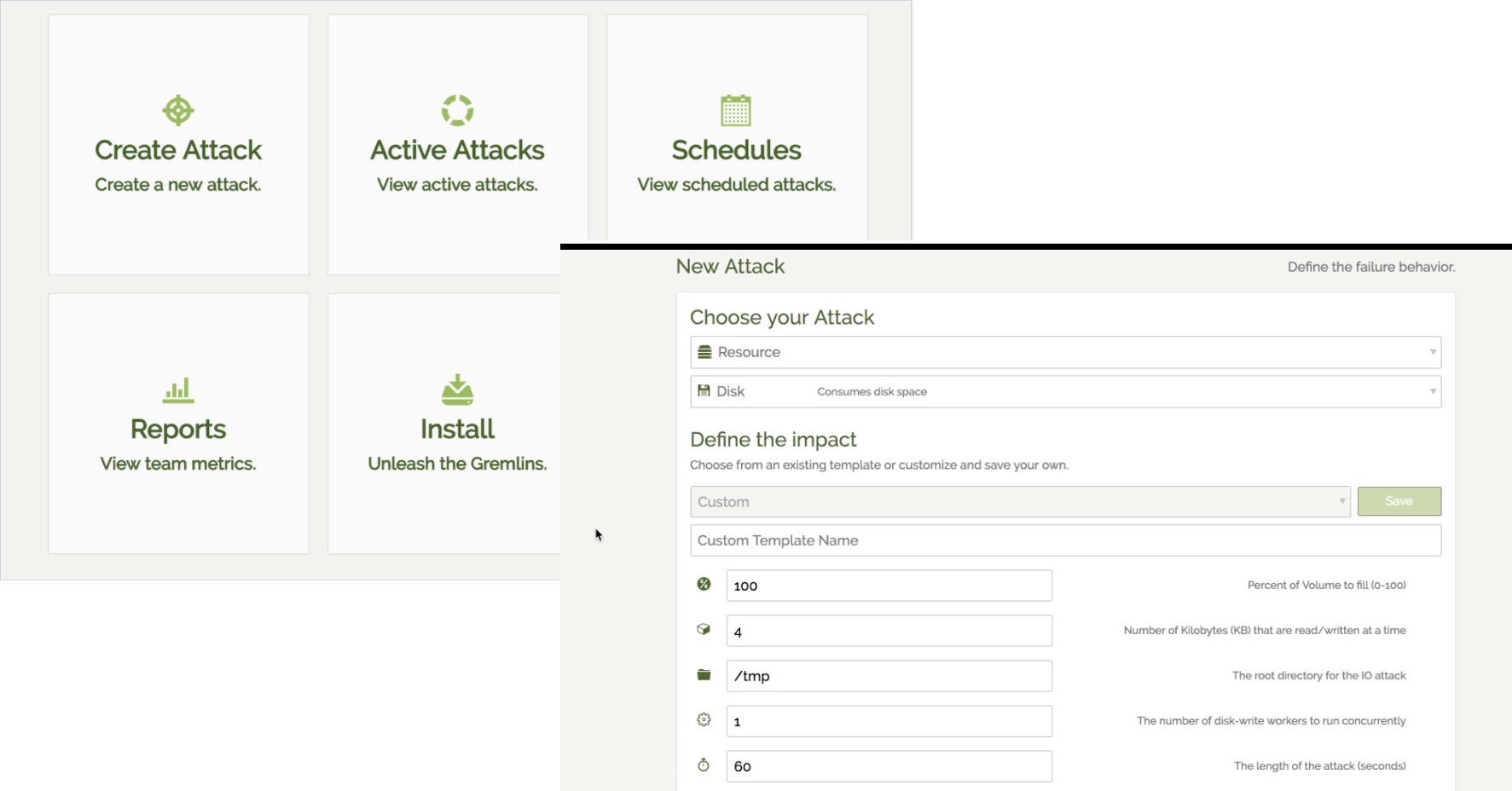
Gremlin 的 Web UI 支持以受控的方式运行,发布一系列针对基础设施的故障“攻击”,其中包括:
-
Resource Gremlins
- CPU:对一到多个 CPU 内核生成高负载;
- 内存:分配指定数量的 RAM;
- IO:对磁盘等 I/O 设备进行读写压力测试;
- 磁盘:通过写文件,占满一定比例的磁盘空间;
-
Network Gremlins
- 黑洞:丢弃所有匹配网络流量;
- 延迟:对所有匹配的出口网络流量注入延迟;
- 包丢失:对所有匹配的出口网络流量加入网络包丢失;
- DNA:阻止对 DNS 服务器的访问;
-
State Gremlins
- 关机:支持用户开展主机操作系统的重启或关闭测试。例如,当一到多个集群内机器失联时,系统的行为如何?
- 时间旅行:更改主机的系统时间,可用于模拟调整夏令时,以及其它与时间有关的事件。
- 杀掉进程:一种杀掉特定进程的攻击,可用于模拟应用或依赖崩溃的情况。
攻击可以是即席的(ad-hoc)、程序化的或按计划执行的。攻击也可以被安排在特定日期和特定的时间窗口内执行,并可设置计划生成的最大攻击次数。Gremlin 提供了一个“撤消”按钮,一旦出现问题,会自动清除攻击测试。安全是“完全重新建立的”,其中使用了最低的权限、多重身份验证、审计和基于角色的访问控制(RBAC)。
Gremlin 的核心价值主张在于,允许工程师启动、控制和观察系统在攻击可引发的各种故障情况下的行为。Gremlin 并不提供自动化金丝雀测试(Canarying),例如类似于 Barometer 提供的功能,也不提供自动故障检测,例如类似于 LightStep 提供的功能。它所提供的是一组全面的故障原语,可用于设计实验,并观察故障在一个复杂分布式系统中的影响情况。Gremlin 不需要修改部署流水线,也不需要修改网络基础架构,因此更便于在一系列的基础架构和部署范例中使用,例如裸机、云 /IaaS 或容器等。
近期,InfoQ 与 Gremlin 公司的首席执行官兼创始人 Kolton Andrus 进行了一次座谈,讨论了混沌工程在软件系统中的作用、可恢复性测试的价值所在,以及 Gremlin 平台的未来。
InfoQ:您能做一个简单的自我介绍吗?最好能简要阐述一下您在混沌工程中的背景。
Andrus:好的。我是 Gremlin 的 CEO 和联合创始人 Kolton Andrus。我们正致力于借助混沌工程,构建更具恢复能力的系统。我们提供“故障即服务”(failure-as-a-service)。
我曾在 Amazon 和 Netflix 任故障呼叫主管(Call Leader),负责管理和解决需及时处理的关键故障,以保证服务时刻在线。我们都非常熟悉半夜被电话叫走去排除关键问题的痛苦。
尽管追根溯源,混沌工程已经提出了十多年,并且有不少很好的开源软件工具对探索道路提供了帮助,但是企业依然需要更多。我们前期已在 Gremlim 解决了这些问题,因此我们熟悉工程师应该如何使用简单易用的工具,安全可靠地执行故障恢复实验,进而自动化这些实验。
InfoQ:当前混沌工程看上去是一个“热点话题”。该话题具有大量的博客帖子,也出现在 Nora Jones 的 AWS re:invent 大会主题演讲中。但是它并非一个全新的话题,Netflix 和 AWS 讨论它已有一段时间了。您为什么认为混沌现在广为使用了?
Andrus:虽然 AWS 和 Netflix 是更早经历这一需求的企业,但是分布式系统的复杂度已经开始对所有的企业产生影响,无论企业的大小。我们当前正处于一个拐点上。构建分布式系统的新方法更加复杂,使得企业无从洞悉何时何处会发生故障。在过去方式中,软件是运行在一个受控的、裸金属环境中,不确定的事情很少。在当前情况下,软件是依赖于我们掌控之外的基础设施和服务。
对云计算的采纳,以及使用微服务的趋势,这样创建的基础设施正在持续走向成熟,并给出了开发、部署和操作应用的新方式,这是前所未有的。但是,这也为企业创建了一条复杂性鸿沟,这样的系统对于任何工程师甚至是工程师团队都过于复杂了,以至于他们不可能完全的理解,这样发生故障是不可避免的。
InfoQ:那么混沌工程或恢复能力测试的最大优点是什么?它们是否仅适用于那些具有专有基础设施团队的大型企业?
Andrus:很多企业是以响应式方式应对服务故障的。但他们并未认识到,这些软件缺陷是可以甄别的,并防止它们继续肆虐,进而节省工程师的时间,降低他们的痛苦,节省上百万元并达到费用的最小化。任何提供随叫随到系统服务支持的团队,都可以通过降低运维负担和宕机时间,从这个方法中受益。
混沌工程支持开展一些经深思熟虑计划的实验。它将故障引入到系统中,识别和修复未知故障,最终构建健壮并具有恢复能力的系统。就像是为你的应用程序注射了流感疫苗。
人们常常会认为混沌工程就是随机地破坏系统。但在我们看来,如果将混沌作为常规测试的一部分,实现高度的规划和自动化,这时混沌将工作得最好。混沌可使团队创建基准去衡量系统情况,确保系统可随变化情况不断地做出改进。
InfoQ:您认为企业在寻求实现混沌工程中所面对的最大挑战什么?
Andrus:当前最大的挑战在于教育。作为一门学科,混沌工程刚刚开始成为工程领域内讨论的一个话题,许多人尚不知道从何处着手。另一方面,高管团队并没有意识到,不少服务中断问题是可以预防的,这些先入为主的观念也必须得到纠正。
Gremlin 公司刚刚启动。对于我们来说,明年我们会把注意力完全集中在教育上。这就是为什么我们与一些公司合作,帮助他们理解这一理念,理解其中对他们有所裨益之处。
解决挑战的一种方式通过游戏日。我们直接与工程团队合作,让他们测试 Gremlin 攻击,甚至是在他们签约成为成为 Gremlin 客户之前。这样,他们可以亲眼看到系统如何应对失败,进而了解我们的工具可为企业所带来的价值。
InfoQ:Gremlin 产品的使用情况如何?您能向我们分享一些成功的案例吗,或对如何有效地使用该工具稍作解释?
Andrus:正如我前面所提到的,我们是一家刚刚启动的公司,但公司的早期发展势头良好。我们正与 12 家重要客户开展合作,其中包括 Expedia 、TwilioConfluent、Remind 等。
我们和 Confluent 的一个团队一起运作了一次游戏日。该团队之前曾经手动开展过游戏日,但是占用了团队整整一天的时间。我们在两个小时内运行了所有的场景,并加入了更多的场景。Twilio 在博客中,介绍了如何使用 Gremlin 去自动化一些故障实验。
InfoQ:您能向我们阐述一下 Gremlin 的路线图吗?混沌工程的未来如何?
Andrus:接下来,混沌工程的主要问题是如何让更多的人认识并采纳。在我看来,混沌工程最终将成为每个公司在做预算时会考虑的事情,并将纳入到大学的计算机科学课程中。我们开始看到,有一些学校已经这样做了。我们认为这只是一个开始。
InfoQ:感谢您今天接受我们的采访!您还有什么希望能与 InfoQ 读者分享的吗?
Andrus: 我们很高兴能为提高互联网的可靠性提供一些帮助。我们都十分依赖于互联网。如果服务产生故障,很可能会对我们的生活造成重大影响。通过帮助指导该行业的发展,帮助我们的客户取得成功,我们希望能对整个社会产生一些影响。
Gremlin 公司最近获得了 750 万美元的 A 轮融资,它的早期客户包括 Expedia、Twilio 和 Confluent。关于 Gremlin 的更多信息,可以在公司的网站上看到。关于混沌工程原理的更多信息,可以在混沌社区的网站上看到。
查看英文原文: Gremlin Release “Resilience as a Service” SaaS Platform to Enable More Effective Chaos Engineering




