Confluent 发布 KSQL :针对 Apache Kafka 的交互式、分布式流 SQL 引擎。KSQL 能够更容易地对 Apache Kafka 的主题进行多种流处理操作,比如聚合(aggregation)、连接(join)、时间窗口(windowing)以及会话(sessionization)。Confluent 是在最近于旧金山举行的 Kafka 峰会上宣布开源这个流数据SQL 引擎的。
KSQL 允许开发人员以类似 SQL 的语法读取、写入和处理实时的流数据。关于流处理方面的样例,包括对比两个或更多的流数据来探测反常现象并实时对其作出反应。与其他的分布式流和 SQL 框架不同的是,KSQL 为 Apache Kafka 提供了一个流数据 SQL 引擎。在 KSQL 之前,开发人员需要使用 Java 或 Python 编程来处理 Kafka 中的流数据。
Neha Narkhede 是 Confluent 的联合创始人兼 CTO,在博客上阐述了 KSQL 框架的特性和使用场景,它可以用到诸如异常检测(anomaly detection)、监控和流式 ETL 中。
在底层,KSQL 使用 Kafka 的 Streams API 来操作 Kafka 主题。在 KSQL 中有两个核心的抽象,它们同时也是 Streams API 的核心抽象:Stream 和 Table。
Stream: Stream 是流处理应用中最重要的结构和一等公民。流是没有边界的结构化数据(“facts”)序列,流中已有的数据是不可变的(新的 fact 可以插入到流中,但是已有的 fact 无法进行更新或删除)。流可以通过 Kafka 主题来创建,也可以通过已有的流或表衍生出来。
Table:在 Kafka 中, Table 是 STREAM 或另外一个 TABLE 的视图,代表了可变 fact 的集合。它与传统数据库中的表是对等的,只不过每当有新事件到达时,它就会持续更新,并且还支持额外的流处理语义,比如时间窗口。表中的 fact 是可变的,这意味着新的 fact 可以插入到表中,已有的 fact 也可以更新或删除。流可以通过 Kafka 主题来创建,也可以通过已有的流或表衍生出来。
Apache Kafka 中的一个主题可以表述为 KSQL 中的一个 Stream 或一个 Table,这取决于在该主题上想要表达的语义。
下图展现了 KSQL 是如何与系统中的两个数据流协作的。
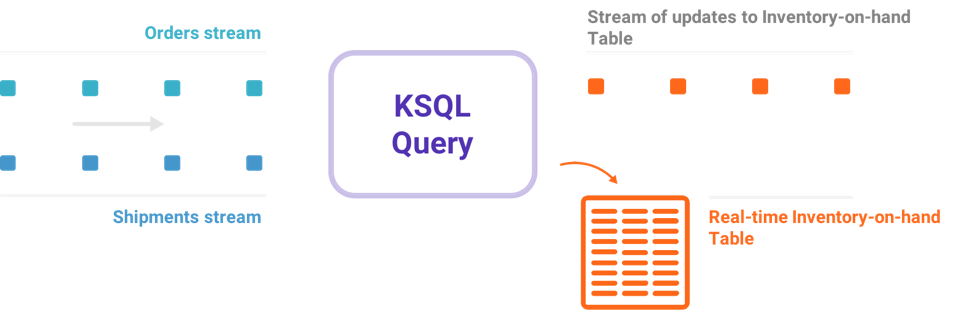
InfoQ 与 Narkhede 就 KSQL 的发布进行了交流。她介绍了为流数据创建 SQL 接口以便于运行查询的驱动力。
在他们使用 Kafka 所构建的流优先的数据架构愿景中,KSQL 是非常重要的一个组成部分。在流优先的世界中,Kafka 和 KSQL 所提供的功能都是之前在实时系统中所无法实现或实现起来非常复杂的。Kafka 日志是流数据的核心存储抽象,这意味着进入离线数据仓库的相同数据可以进行流处理了。其他所有的内容都是使用 KSQL 基于日志创建出来的流视图,比如各种数据库、搜索索引或服务于公司系统的其他数据。创建这些衍生视图所需要的数据完善功能和 ETL 都可以借助 KSQL 以流的方式来完成。
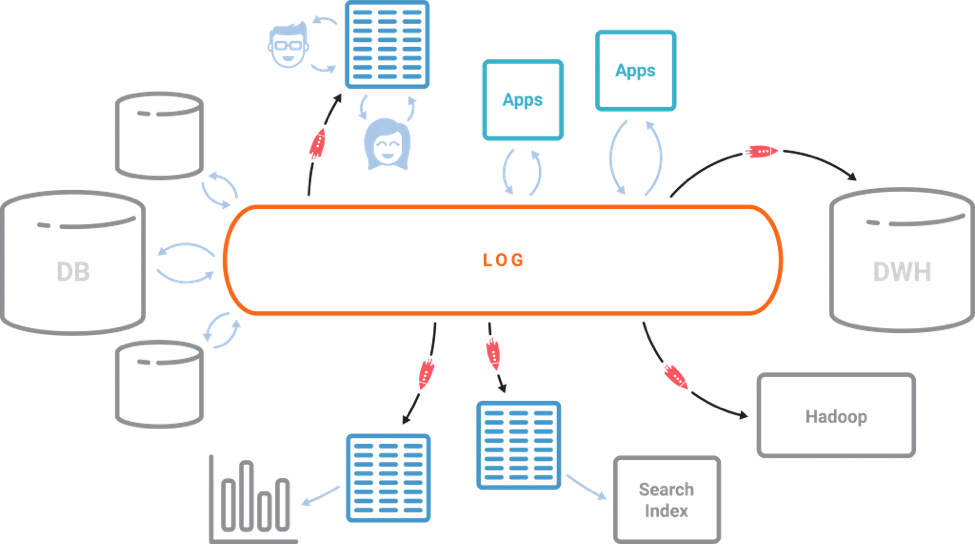
InfoQ:你能介绍一下 KSQL 在集群和故障恢复方面的技术细节吗?
Neha Narkhede:有一个执行查询的 KSQL 服务器进程。一组 KSQL 进程会以集群的方式来运行。我们可以通过启动更多的 KSQL 服务器实例动态添加处理能力。这些实例是容错的:如果其中有一个发生故障,其他的实例会接管它的工作。查询是通过交互式 KSQL 命令行客户端发起的,客户端会通过 REST API 将命令发送至集群中。命令行允许我们探查可用的流和表、提交新的查询、检查运行查询的终端的状态。在内部,KSQL 是使用 Kafka 的 Streams API 来构建的,这样就继承了它的弹性扩展、高级状态管理以及容错性,并且还支持 Kafka 最近宣布的 仅处理一次的语义(exactly-once processing semantics)。KSQL 服务器将其嵌入了进来并基于此添加了分布式 SQL 引擎(包括一些有趣的内容,比如为了提升查询性能引入的自动字节码生成功能),除此之外,还提供了用于查询和控制的 REST API。
InfoQ:相对于使用 Kafka API 来访问流数据,在使用 KSQL 查询时,有什么性能方面的考虑吗?
Narkhede:KSQL 使用 Kafka 的 Streams API 进行构建,与 Kafka 集成地非常紧密。这种与 Apache Kafka 核心基础的紧密集成能够移除额外的数据转移和序列化层,如果在 Kafka 中使用非原生方案来处理流数据的话,往往必须要通过这些分层。所以,采用 KSQL 来处理 Kafka 主题中的数据时,额外的损耗是很低的。另外值得一提的是,KSQL 依然处于开发者预览阶段,目前还没有性能基准。开发者预览阶段的目标就是与 Kafka 社区协作,确保 KSQL 能有杰出的用户体验。在接下来的几个月中,我们将精力投入到性能提升、测试以及操作稳定性上。
InfoQ:在提供标准的方式查询流数据方面,你认为 KSQL 会扮演什么样的角色?
Narkhede:在我们创建 Kafka 之时,JMS 是消息处理领域的标准,Kafka 基于日志范式的简单 API 对整个业界都很新颖。如今,Kafka 不仅是消息领域的标准,还成为了管理实时数据的标准。它之所以能够成功要归因于简洁的用户体验,并且能够广泛应用于大规模流数据处理方面新的问题域之中。与之类似,KSQL 提供了类似于 SQL 的接口,它修改了 SQL 标准使其更加适用于流处理。KSQL 通过这样做,支持将流和表作为第一等的抽象,这对于充分发挥流处理的潜力并将其用到真正的用户场景中至关重要,这些场景包括流 ETL、监控、异常检测和分析。KSQL 为流处理领域带来了简洁性和操作的便利性,这会影响到查询流数据方面新标准的制订。
InfoQ:你能介绍一下 Kafka 的路线图吗,接下来读者会有哪些有趣的特性值得学习呢?
Narkhede:我们目前以开发者预览的方式发布了 KSQL,开始围绕它构建社区并收集反馈。在与开源社区协作的过程中,我们计划添加更多的功能,使其在质量、稳定性以及操作性方面成为生产环境就绪的系统,我们准备支持更丰富的 SQL 语法,包括功能更强的聚集函数以及在连续表上任意时间点上使用的
SELECT语句,也就是能够基于已计算出来的结果进行查找,也支持对流连续计算的结果进行查询。
KSQL 目前基于 Apache 2.0 许可证模式处于开发者预览(Developer Preview) 阶段,团队计划在接下来的几个月中使其达到生产环境就绪(production-ready)阶段。
读者可以参考快速入门指南和 KSQL Docker 镜像学习这个工具的更多情况。如果你希望参与社区的话,还有一个 KSQL Community Slack Channel 。关于 KSQL 的其他资源还有一个视频,它展现了如何使用KSQL 实现实时监控、异常探测和报警功能。
查看英文原文: Confluent Releases KSQL, a Distributed Streaming SQL Engine for Apache Kafka




