写在前面
做过分布式系统的人都知道,想要在大规模集群下处理高并发事务时同时满足 CAP(一致性、可用性、分区容错),从理论上来说不可能,当然听说最近谷歌已经实现了这样的分布式系统,但是总的来说确实非常难。对于社交媒体的海量日志文件,如果我们也提出了需要确保高可用、持续写入数据、按照记录顺序返回数据等三条要求,你觉得是否可以实现?FaceBook 的 LogDevice 实现了。
什么是日志
日志是记录一系列序列化的系统行为的信息,我们需要确保它们能够被保存在可靠的地方。对于应用程序来说,日志的作用一般有两个,即 Troubleshooting 和显示程序运行状态。好的日志记录方式可以提供我们足够多定位问题的依据。对于一些复杂系统,例如数据库,日志可以承担数据备份、同步作用,很多分布式数据库都采用“write-ahead”方案,在节点数据同步时通过日志文件恢复数据。
日志一般具有三个特性:
- 面向记录:写入日志的一定是孤立的行,而不是一个字节。日志实质上是问题的最小单元,用户也一定是读取整行日志。日志的存储原则上按照顺序,即按照 LSN(日志顺序数字)存放,但是也不完全这么要求,所以日志系统可以优先高写入需求,对写入失败容错。
- 日志天生就是递增的:也就是说,日志是不会修改的,那么也就意味着,日志系统的设计应该是以高写入、高读取为目标,不需要担心更新操作的数据一致性问题。
- 日志存储周期长:可能是一天,也可能是一个月,甚至于一年。这也就意味着,日志的删除规则一般都是按照时间或者空间进行设定的,具有固定的规则。
来个假如
假如我们要设计一个分布式日志存储系统,你会怎么设计?
日志信息需要传输、存储,为了实现稳定的数据交换,我们可以采用 Kafka 作为消息中间件。
Kafka 实际上是一个消息发布订阅系统。Producer 向某个 Topic 发布消息,而 Consumer 订阅某个 Topic 的消息,进而一旦有新的关于某个 Topic 的消息,Broker 会传递给订阅它的所有 Consumer。在 Kafka 中,消息是按 Topic 组织的,而每个 Topic 又会分为多个 Partition,这样便于管理数据和进行负载均衡。同时,它也使用了 Zookeeper 进行负载均衡。
Kafka 在磁盘上的存取代价为 O(1),即便是普通服务器,每秒也能处理几十万条消息,并且它本身就是分布式架构,也支持将数据并行加载到 Hadoop。
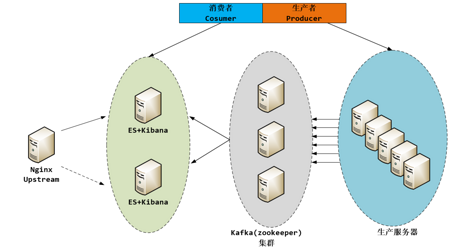
上面这张图是一个典型的采用消息中间件进行日志数据交换的系统设计架构,但是没有实现数据存储,也没有描述数据是如何被抽取并发送到 Kafka 的。
如果想要实现数据存储,并描述清楚内部处理流程,我们可以采用怎么样的日志处理系统架构呢?这里推荐你 FaceBook 的 Scribe,它是一款开源的日志收集系统,在 Facebook 内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统 (可以是 NFS,分布式文件系统等)上,以便于进行集中统计分析处理。
Scribe 最重要的特点是容错性好。当后端的存储系统奔溃时,Scribe 会将数据写到本地磁盘上,当存储系统恢复正常后,Scribe 将日志重新加载到存储系统中。
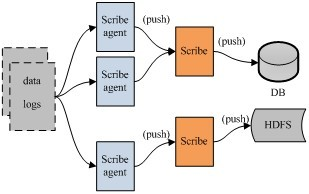
Scribe 的架构比较简单,主要包括三部分,分别为 Scribe Agent, Scribe 和存储系统。Scribe Agent 实际上是一个 Thrift Client。Scribe 接收到 Thrift Client 发送过来的数据,根据配置文件,将不同 topic 的数据发送给不同的对象。存储系统实际上就是 Scribe 中的 Store,当前 Scribe 支持非常多的 Store。
貌似市面上已经有很多分布式日志收集系统了,为什么 FaceBook 还需要推出 LogDevice 呢?而且 FaceBook 自己已经有了 Scribe,为什么还要继续设计 LogDevice? 因为 Scribe 更多实现了日志数据的收集,它不是一个完整的日志处理、存储、读取服务,系统设计也较为死板,存储更多依赖 HDFS,使用过程中一定出现了不能满足自身需求的情况。而对于开源的哪些分布式日志收集系统,更多的是集成各个开源组件,共同完成日志存储系统设计需求。对于 FaceBook 的工程师来说,他们一贯秉承着用于创新的精神,想想 Apache Cassandra,其实当时已经有 HBase 等成熟的 NoSQL 数据库,但是由于存在中心节点等诸多设计上的限制,FaceBook 自己搞了一个全新的无中心化设计的架构,即便在初期饱受质疑,后续也在不断地改进,到目前为止,Cassandra 真正进入到了它的黄金时代。
LogDevice
- 设计背景
FaceBook 拥有大量的分布式服务用于保存和处理数据,如果想要构建高可用的数据密集型分布式服务,FaceBook 认为,一定需要保存日志。为了处理 FaceBook 内部日志的高强度负载、性能需求,FaceBook 把 LogDevice 设计成了可以调节的系统,而不是一套方案应对所有需求。
- 需求整理
对于日志服务的需求,也就是对于 LogDevice 的需求,第一条就是服务必须永远在线,不允许出现离线状态,因为 FaceBook 内部各个系统都需要保存日志,也就是说高可用。第二条是持久性,也就是说不允许丢数据,特别是返回客户端写入成功之后,绝对不能丢失数据。第三条是存在一定程度的数据读取,并且通常是读取最近写入的日志数据,这一条实质上是要求写入响应快。
- 设计思路
对于整个日志系统来说,整个设计应该更加关注数据的写入速度,怎么样设计才能具有更快的写入速度,并能支撑一定的读取速度,所以需要看看数据是如何被写入到 LogDevice 的。
如果需要提升日志文件的写入速率,或者更高一点要求,希望没有写入速率限制,你该怎么实现?我们可以模仿分布式文件系统或者分布式数据库的设计方式,采用多处副本方式,即一个文件有多个副本,那么每次日志写入请求就有了几处写入地址选择,而不是单一一个节点,或者几个特定的节点。这样做的好处是,当集群中的一部分节点宕机或者失去联系时,日志写入请求不会受到大规模的干扰,并且写入负载能够做到相对均衡。
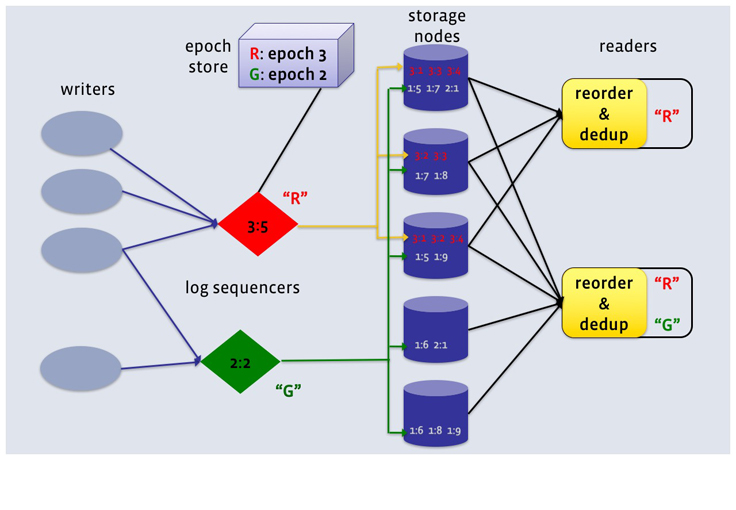
数据副本设计,有没有其他系统实现?
有,非常多,例如 HDFS、Cassandra。我们这里还是以 FaceBook 自己出品的 Cassandra 为例。
Cassandra 在多个节点上存储副本以确保可用性和数据容错。副本策略决定了副本的放置方法。集群中的副本数量被称为复制因子,复制因子为 1 表示每行只有一个副本,复制因子为 2 表示每行有两个副本,每个副本不在同一个节点。所有副本同等重要,没有主次之分。作为一般规则,副本因子不应超过在集群中的节点的树木。当副本因子超过节点数时,写入不会成功,但读取只要提供所期望的一致性级别即可满足。目前 Cassandra 中实现了不同的副本策略,包括:
- SimpleStrategy:复制数据副本到协调者节点的 N-1 个后继节点上;
- NetworkTopologyStrategy:用于多数据中心部署。这种策略可以指定每个数据中心的副本数。在同数据中心中,它按顺时针方向直到另一个机架放置副本。它尝试着将副本放置在不同的机架上,因为同一机架经常因为电源、制冷和网络问题导致不可用。
多数据中心集群最常见的两种配置方式是:
- 每个数据中心 2 个副本:此配置容忍每个副本组单节点的失败,并且仍满足一致性级别为 ONE 的读操作。
- 每个数据中心 3 个副本:此配置可以容忍在强一致性级别 LOCAL_QUORUM 基础上的每个副本组 1 个节点的失败,或者容忍一致性级别 ONE 的每个数据中心多个节点的失败。
LogDevice 将日志里的记录顺序和实际存储的顺序区分开来,通过序列器产生一个学号,对每一行存储的日志进行重新序列标定。一旦一行记录被标定了这个序列号,接下来该条记录(数据)就会被保存在集群中任一位置。注意,这里提到的序列号不是一个数字,而是一对数字,第一个数字叫做“ epoch number”,第二个是相对于第一个的偏移量。序列号生成器本身也是需要做好容灾的,也就是说,一旦一个序列号生成器服务不在线,另一个一定要被立即启用,而它生成的序列号要比当前已经存在的序列号大。FaceBook 使用 ZooKeeper 保存序列号(Epoch Number)。
这里为什么要选择 ZooKeeper 存储序列号?
ZooKeeper 作为 Hadoop
项目中的一个子项目,是 Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理 Hadoop 集群中的 NameNode,还有 HBase 中 Master 节点的选举机制、服务器之间的状态同步等。除此之外,ZooKeeper 还可以被用在构建高可用性集群、统一命名服务管理、分布式缓存机制设计、配置文件管理、集群管理、分布式锁机制设计、队列管理等等。存储序列号的思路配置文件管理类似。
配置文件的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。诸如这样的配置信息完全可以交给 ZooKeeper 来管理,将配置信息保存在 ZooKeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 ZooKeeper 的通知,然后从 ZooKeeper 获取新的配置信息应用到系统中。
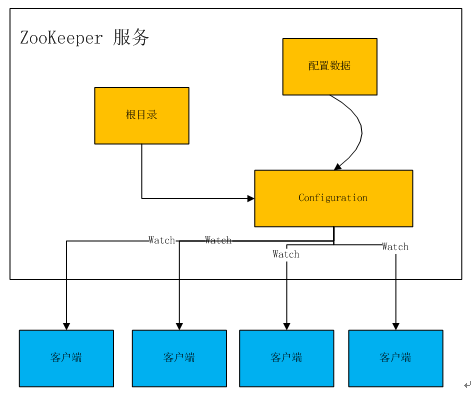
如上图所示,实际应用时我们可以通过自动监测 Master 节点内是否形成了新的配置文件,并在检测到形成了新的配置文件后主动上传到 ZooKeeper,并下发到各 Slave 节点加载到内存中用于搜索任务的处理,无需管理人员在发现 Master 节点形成了新的配置文件之后,重启 Master 节点才将新的配置文件上传,显然降低了 Master 节点与 Slave 节点间配置文件同步的繁琐性,提高了设备的智能性,降低了同步成本。
根据 FaceBook 的设计思路,由于日志文件本身是可以随机读的,并且很多节点上都存在数据,这有点像小文件存储方式,每个节点上的数据都可以被读取,因此不会造成 IO 和网络资源的浪费。
数据是怎么做到负载均衡的?
FaceBook 没有在文章中描述实现原理。我们可以看看 HDFS 是怎么实现的。
数据平衡过程由于平衡算法的原因造成它是一个迭代的、周而复始的过程。每一次迭代的最终目的是让高负载的机器能够降低数据负载,所以数据平衡会最大程度上地使用网络带宽。下图 1 数据平衡流程交互图显示了数据平衡服务内部的交互情况,
包括 NameNode 和 DataNode。步骤分析如下:
- 数据平衡服务首先要求 NameNode 生成 DataNode 数据分布分析报告。
- 选择所有的 DataNode 机器后,要求 NameNode 汇总数据分布的具体情况。
- 确定具体数据块迁移路线图,保证网络内最短路径,并且确保原始数据块被删除。
- 实际开始数据块迁移任务。
- 数据迁移任务完成后,通过 NameNode 可以删除原始数据块。
- NameNode 在确保满足数据块最低副本条件下选择一块数据块删除。
- NameNode 通知数据平衡服务任务全部完成。
HDFS 数据在各个数据节点间可能保存的格式不一致。当存放新的数据块 (一个文件包含多个数据块) 时,NameNode 在选择数据节点作为其存储地点前需要考虑以下几点因素:
- 当数据节点正在写入一个数据块时,会自动在本节点内保存一个副本。
- 跨节点备份数据块。
- 相同节点内的备份数据块可以节约网络消耗。
- HDFS 数据均匀分布在整个集群的数据节点上。
FaceBook 采用内存 + 磁盘的方式存储日志,HDD 硬盘可以达到 100-200MBps 每秒的顺序读写速度,随机读写速度顶峰可以达到 100-140MBps 每秒。用来存储日志的服务被称为 LogsDB,它是针对写入性能进行特殊优化过的。LogsDB 本身又是构建于 RocksDB 之上的,RocksDB 是基于 LSM 树的有序 Key-Value 存储层。RocksDB 的每一个实例对应 LogsDB 的分区,当写入日志文件时,会写入到最新的分区,也就是最近访问过的 RocksDB 实例(以 log id、LSN 排序),然后以顺序方式保存到磁盘(称为 SST 文件)。这种方式确保了写入的方式是顺序方式,但是需要合并文件(当达到 LogsDB 分区的最大文件数量时)。
总结
就在我写文章的时候,微博因为“鹿晗介绍女朋友”事件奔溃了,系统启动之后的数据同步、验证过程,日志的作用非常重要。目前 LogDevice 还没有开源,但是从它的介绍来看,它应该是结合了 FaceBook 内部的多个开源项目的精髓,例如 Cassandra,它的无中心化存储、碎片化存储(SSTable)、SSTable 文件合并等等优秀的特性,为确保日志文件的高速写入、快速读取提供技术支撑。FaceBook 已经明确今年年底会开源 LogDevice,喜欢分布式实时处理、存储系统的同学们,就等着它了。
作者介绍
周明耀,2004 年毕业于浙江大学,工学硕士。13 年软件研发经验,近 10 年技术团队管理经验,4 年分布式计算、大数据技术经验。出版书籍包括《大话 Java 性能优化》、《深入理解 JVM&G1 GC》、《技术领导力 - 码农如何才能带团队》。个人微信号 michael_tec,个人公众号“麦克叔叔每晚 10 点说”,每天发布一篇技术短文。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




