在近期举行的 PHPDublin 见面会上,来自 DynamicRes 的架构师 Barry Sullivan 被问到“什么是事件溯源”,作为对这个问题的回答,他在博客上写下了这篇文章,详细解释了什么是事件溯源以及事件溯源有哪些好处。以下内容翻译自 Barry 的博客,已获得作者授权。
Web 开发的现状
在详细解释事件溯源之前,先让我们来看看 Web 开发的现状。
当前的 Web 开发是以数据库作为驱动的,在设计 Web 应用的时候,我们会自然而然地将系统设计与数据库存储机制联系在一起。如果使用的是 MySQL,我们就会把数据结构设计成表,如果使用的是 MongoDB,就会把数据结构设计成文档。这样会强制我们只关注事物的当前状态,我们会想“怎样保存这些数据,以便将来可以再把它们拿出来(或者修改它们)”?
这种方式存在三个问题。
1. 有悖于我们的思维
人类的思考和交流并不是以状态为中心。如果我们在咖啡店相遇,我会问你“最近可好”?如果你只是告诉我一堆状态却指望我从中猜出发生了什么事情,这是非常不合情理的。
“我有一幢房子、一辆汽车、一个冰箱、三个社交媒体账号、一只猫咪,我的右脚有点痛,我不擅长聊天,我还有另一只猫咪……”
看到没有?这样我会疯掉的。你应该告诉我,从上次见面之后都发生了哪些事情,这样我才能知道你现在的状况是什么样子的。简单地说,你应该告诉我一个故事,这个故事是由一连串事件组成的。
2. 单一的数据模型
在上图中,读写操作使用了相同的模型。我们从写数据的角度来设计表,然后基于这样的结构查询数据。这对于小型的应用来说是没有问题的,但用在大型的应用里就会有问题。随着系统的增长,查询会变得越来越复杂,总有一天,一个查询可能会包含 10 个连接操作,代码有 100 行那么多。系统很快就会变得脆弱无比,难以维护和变更。
3. 关键业务信息的丢失
这是一个大问题。在以表作为驱动的系统里,你只保存了系统的当前状态,你根本就无法知道系统是如何达到当前状态的。如果我问你“这个用户修改了几次邮件地址”,你有办法回答吗?或者我再问“有多少人把一件商品添加到购物车里,然后又移除掉,直到一个月之后才买了那件商品”,你就更没法回答了。你存储数据的方式丢掉了很多有用的业务信息!
事件溯源
事件溯源与上述的情况恰好相反,它并不关心当前状态,而是关注持续不断的变化事件。
举个例子,假设我们有一个“购物车”,我们可以创建购物车,往里面添加商品或移除商品,然后结账。
购物车的生命周期可以包含如下一系列事件:
- 创建购物车
- 往购物车里添加商品
- 再次往购物车里添加商品
- 从购物车里移除商品
- 结账
这些就是一个购物车的生命周期,包含了一系列事件。这就是事件溯源,非常简单吧?

几乎所有的流程都可以被看成一系列事件。在与领域专家交谈时,他们不会提及“表”和“连接”,他们会将流程描述成一系列事件以及可以应用在这些事件上的规则。
如何实施业务规则?
大部分的业务操作都有硬性约束。对于购物车来说,它的约束就是“一件商品必须先被放进购物车后才能被移除”。如果一件商品没有被添加到购物车里,又怎么能够移除它?这种事件顺序是不可能发生的。在没有状态的情况下,你怎样才能知道“购物车里是否有这件商品”?
很简单,你只要检查之前是否发生过“商品被添加到购物车里”这个事件,这样你就可以知道购物车里是否存在这件商品,然后移除它。
这样不会浪费时间吗?
一点也不。一般来说,要执行约束,只需要获得事件的一个很小子集。通过简单的数据库查询就可以获得有用的历史事件,在加载完这些事件后重放它们,把它们“投射”出来,以此构建你的数据集。这样的操作其实是很快的,因为你使用的是本地的处理器,而不是执行一系列 SQL 查询(跨域网络的调用要比本地操作慢得多,至少会相差两个数量等级)。
如何展示数据?
如果说每一个状态都是通过重放事件来获得的,那么该如何抓取数据并把它们展示给用户看?每次都需要抓取所有的数据然后再构建这些数据集吗?
答案是你没必要这样做,这样做其实是很荒唐的。
你可以在后台构建数据集,然后把中间结果保存在数据库里。这样,用户就可以在很短的时间内查询到这些数据。
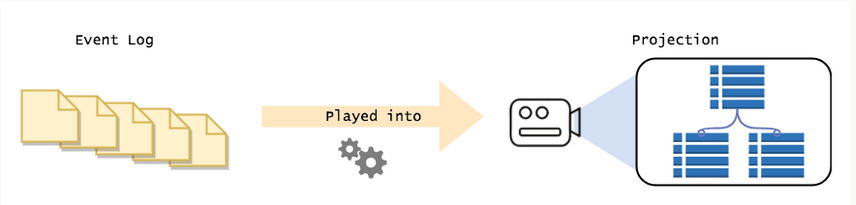
有了事件溯源,你就不再局限于当前的表结构。需要做其他的查询?只要设计一个新的结构就可以了。你可以自由地实现各种读取模型,在不需要它们的时候再把它们抛弃掉。
事件溯源的好处
1. 临时的数据结构
因为所有的状态都可以通过重放事件获得,所以就没有必要把当前“状态”与应用程序绑在一起。如果需要以新的方式查看数据,直接创建新的数据视图即可。不再需要繁杂的数据迁移脚本,要做的只是创建新视图,抛弃旧视图。我现在几乎离不开事件溯源了。
2. 与领域专家的沟通变得更简单
正如之前所述,领域专家通常将业务流程描述成一系列事件,而不是状态。基于事件溯源的系统与领域专家的描述不谋而合,所以就没有必要把他们的描述转换成技术概念,这样也避免了信息丢失。与领域专家的沟通因此变得更加顺畅,因为我们正在使用他们能够理解的语言与他们沟通,这也让软件开发变得很不一样。
3. 极具表现力的模型
在事件溯源模型里,事件是一等对象,事件模型更加接近于实际的业务流程。这让很多东西都变得清晰明了,你就不会陷入存储技术的泥潭。
4. 生成报告更轻松
在事件溯源系统里,生成复杂的报告是一件轻而易举的事情。你拥有完整的历史事件,它们按照时间排序,你可以尽情地使用这些历史数据。
以之前的例子为例,假设你想知道有多少个用户从他们的购物车里移除了商品,却在一周后购买了这些商品。按照一般的开发方式,通常需要几周的时间才能开发出这个功能,而在发布之后,需要等上一段时间,等计算完所有数据之后才能生成报告。而在事件溯源系统里,你可以马上得到报告。你还可以得到之前任何一个时间点的报告,仿佛拥有了一台时光机。
5. 服务集成唾手可得
在标准的 Web 开发流程里,集成两个系统通常会导致他们之间的耦合,而事件溯源系统通过事件来解耦被集成的系统。当一个系统发生某系事件需要触发另一个系统的某个流程时,只需要写一个事件监听器即可。这种机制可以让你在不修改已有领域代码的情况下增加新的集成逻辑或特性。
例如,你想要在用户注册的时候发送一封欢迎邮件给他们,你只需要创建一个事件监听器,监听“用户注册”事件,而不需要去修改注册逻辑代码。
6. 在一般的数据库上也能健步如飞
你不需要使用多么奇特的数据库来存储事件,一般的 MySQL 数据库就足以。数据库都针对追加操作进行过优化,所以存储数据的速度是很快的。这也就是为什么事件溯源在当前的技术条件下能够良好运作,保存事件都是追加操作。
7. 可以随意更换数据库
基于事件溯源的数据结构都是临时性的,所以你可以使用你喜欢的数据库来存储状态,也就是说你完全可以选择最好的工具来完成你的工作。如果你发现了更好的工具,可以在任何时候把旧工具替换掉。我们目前正在从 MySQL 迁移到 OrientDB,可以说是轻而易举。
事件溯源的不足
天下没有完美的东西,事件溯源给我们带来了诸多好处,但也存在一些不足。
1. 最终一致性
事件溯源只能保证最终一致性。也就是说,在一个事件发生了之后,其他系统不会立即感知到它,在它们收到事件之前会有一定的延迟(比如 100 毫秒),所以你所投射的数据可能不是最新的。这看起来似乎是一个大问题,但其实不是的。例如,基于 ReactJS 构建的 Web 应用会基于用户的操作事件构建状态,查询端出现几毫秒的延迟并不会有什么问题。
老实讲,这可以说是塞翁失马,焉知非福。最终一致性的系统具有容错能力,可以解决服务中断问题。如果使用微服务架构或无服务器架构来构建分布式系统,就需要通过最终一致性来保证稳定性。
2. 事件结构发生变化
事件结构会发生变化,如果事先没有考虑到这个问题,后续处理起来会有些麻烦。如果事件结构发生变化,需要写一个更新器来转换新旧事件。转换过程可以在将数据从数据存储中读取出来之后进行。这个没有它看起来那么难,只需要准备好应对策略就可以了。
3. 开发人员需要改变思维
目前的 Web 开发主要还是以状态作为驱动,所以开发者习惯了从表的角度看待问题,而不是事件。我发现要让开发者改变思维需要一些时间,因为他们需要时间来改变习惯。最好的解决办法是让有经验的事件溯源开发者与传统的开发者结对。
总结
我很喜欢事件溯源,在构建大规模分布式系统时,它帮助我们解决了很多问题。我们可以使用领域专家能够了解的语言与他们进行沟通,我们可以自由地改变和适配系统。尽管事件溯源有一定的学习曲线,但一旦你进入到这个领域,就不会想要回头。
查看英文原文: Event Sourcing: What it is and why it’s awesome
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




