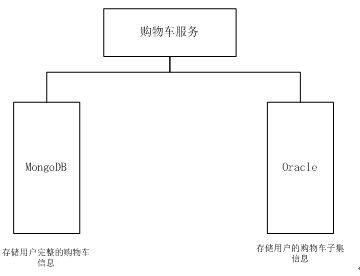
eBay 的购物车信息存储依赖于两个不同的数据存储介质,MongoDB 存储用户完整的购物车信息,Oracle 仅存储购物车的大致信息,但是可以通过关键信息查找所有的购物车信息。在 eBay 的这套系统里,MongoDB 更多被用来充当“缓存”,Oracle 数据库作为存储副本。如果数据在 MongoDB 里面找不到了,服务会从 Oracle 里面重新抽取(恢复)数据,然后重新计算用户的购物车。
所有的购物车数据都是 JSON 格式的,JSON 数据在 Oracle 里被存储在 BLOB 格式的字段里。这些 Oracle 里面的数据只能被用于 OLTP 交易。
这篇文章并不是讨论数据库技术的选择(Oracle vs MongoDB,或者其他数据),而是希望能够让大家在巨量访问系统(每天上百万次调用)中找到技术债,理解如何解决问题。
问题描述
2016 年秋天开始,购物车服务出现了缓存层丢失数据的情况,同时,运维团队报告 MongoDB 的备份机制多次出现失败(MongoDB 运行在主从模式)。eBay 的这个服务已经运行了 5 年时间,一直没有出现问题,没有做过任何架构调整和大规模代码改变,需要尽快找到原因和防治办法。针对实际问题进行反复检查,发现 MongoDB 的 oplog(实时性要求极高的写日志记录)正在达到网络 I/O 限制。每一次的数据丢失,都会触发保护措施(再次从 Oracle 读取数据后重复计算),并进一步加长用户的等待时间。
解决方案
在我们具体讨论特定的解决方案前,我们希望去尽可能多地讨论解决方案。例如,一旦备份机制没有启用,是否可以通过隐藏一些副本方式让系统能够正常运行,而不要在系统特别繁忙的时候去尝试重新备份。我们可以尝试超时机制和阶段性副本方式,但是这些方式并不会引起我们本文说的问题发生。
方案一:切片(MongoDB)
团队成员提出对 JSON 数据进行切分,即对原先存储在 MongoDB 里的原子化的购物车信息(一个 JSON 字符串),切分为多个字符串,这样做的好处是可以减少单一 MongoDB 中心节点的写入次数和网络开销。
对于数据切分后的关联方式,远比数据切分、负载均衡复杂,因此,第 1 种方案的选择会引入其他技术难点,需要我们自己能够寻找被切分后的数据的关联性,这就是为什么 eBay 放弃了这个方案。
方案二:有选择的写入
使用 MongoDB 的 set 命令,只针对当特定值发生更改后,才启动写入操作。这种方式理论上也是可行的。
但是如果你真正考虑一下,这种做法没有从根本上确保减少 oplogs 写入次数,但是它很有可能会造成整个文档的更新。
了解一下 MongoDB 的 Set 操作模式。Set 操作可以用于使用特定值替换字段值:
{$Set{:,…}}
假如你考虑一下描述产品的文档如下所示:
{
_id:100, sku:”abc123”, quantity:250, instck:true, reorder:false, details:{model:”14Q2”,make:”xyz”}, tags:[“appeal”,”clothing”],
ratings:[{by:”ijk”,rating:4}] }
对于满足 _id 等于 100 的文档,执行 set 操作更新 quantity 字段、details 字段和 tags 字段的值。
db.products.update( {_id:100}, {$set:
{
quantity:500,
details:{model:”14Q3”,make:”xyz”},
tags:[“coats”,”outerwear”,”clothing”]
} } )
以上这个操作替换 quantity 的值为 500,details 字段的值为一个新的嵌入式文档,tags 值为一个数组。
方案三:客户端压缩
考虑到需要尽快解决问题,所以需要尽量避免重写业务逻辑,压缩方式看起来是比较好的一中了。减少进入 MongoDB 的 Master 节点的数据量,这样可以减少写入 oplog 的数据规模。但是,这种方式会将 JSON 字符串转变为二进制文章,操作时也需要解压缩。
常用的压缩算法主要有:deflate、gzip、bzip2、lzo、snappy 等。差别如下所示:
- deflate、gzip 都是基于 LZ77 算法与哈夫曼编码的无损数据压缩算法,gzip 只是在 deflate 格式上增加了文件头和文件尾;
- bzip2 是 Julian
Seward 开发并按照自由软件 / 开源软件协议发布的数据压缩算法,Apache 的 Commons-compress 库中进行了实现; - LZO 致力于解压速度,并且该算法也是无损算法;
- LZ4 是一种无损数据压缩算法,着重于压缩和解压缩速度;
- Snappy 是 Google 基于 LZ77 的思路用 C++ 语言编写的快速数据压缩与解压程序库,2011 年开源。它的目标并非最大程度地压缩,而是针对最快速度和合理的压缩率。
目标和考虑
在我们开始做这一功能性测试之前,我们需要明确几个目标。
- 允许购物车被压缩并持久化到 MongoDB(数据不会有改变)。
- 允许压缩编码方式的选择,支持采用一种编码方式读取,另一种编码方式写入。
- 允许读到老的、新的、中间状态的购物车信息,新老前后可以互相兼容。
- 压缩和解压缩的操作可以同时进行。
- 确保没有针对 MongoDB 数据库的实时 JSON 数据检索查询请求。
JSON 字符串例子
这是老的 JSON 字符串:
{ “_id” : ObjectId(“560ae017a054fc715524e27a”), “user” : “9999999999”,
“site” : 0, “computeMethod” : “CCS_V4.0.0”, “cart” : “…JSON cart
object…”, “lastUpdatedDate” : ISODate(“2016-09-03T00:47:44.406Z”) }
这是压缩之后的 JSON 字符串:
{ “_id” : ObjectId(“560ae017a054fc715524e27a”), “user” : “9999999999”,
“site” : 0, “computeMethod” : “CCS_V4.0.0”, “cart” : “…JSON cart
object…”, “compressedData” : { “compressedCart” : “…Compressed
cart object…” “compressionMetadata” : { “codec” : “LZ4_HIGH”,
“compressedSize” : 3095, “uncompressedSize” : 6485 }, },
“lastUpdatedDate” : ISODate(“2016-09-03T00:47:44.406Z”) }
测试结果
通过使用相同的购物车数据进行测试,观察 CPU 或者 I/O 情况,数据如图所示:
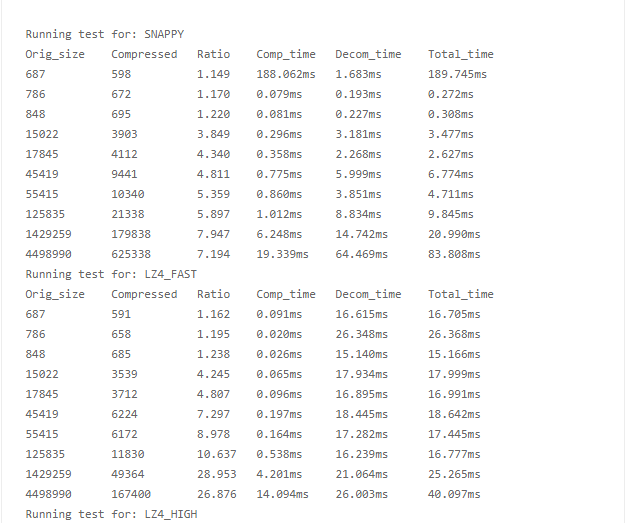
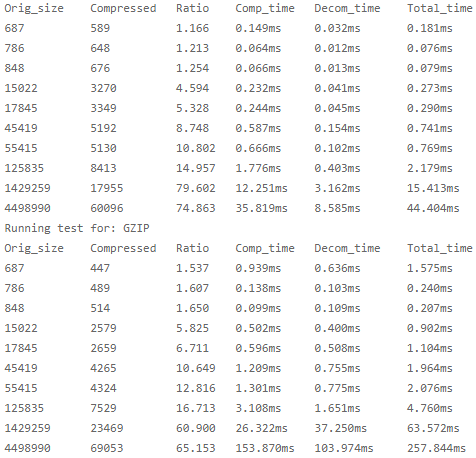
结论
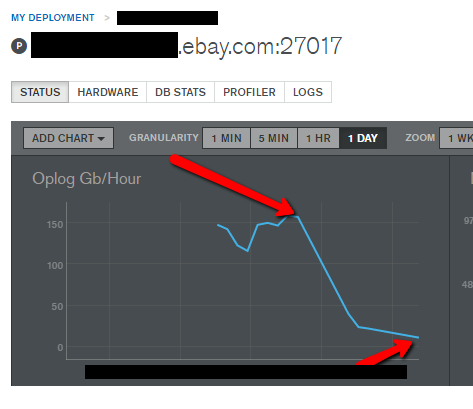
oplog 的写入速率,从 150GB/ 小时下降为大约 11GB/ 小时,下降了 1300%!文档的平均对象大小从 32KB 下降为 5KB,600% 的下降。此外,服务的响应时间也有所改善。数据如图所示:
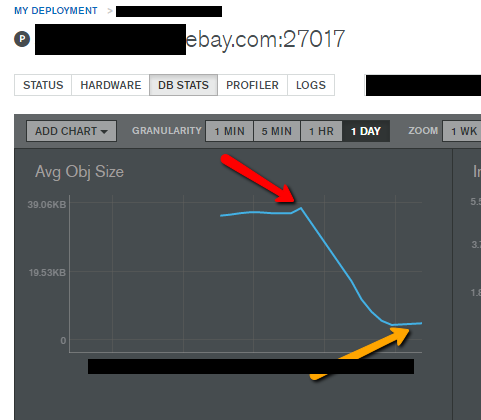
下面这张图显示的是 MongoDB 的 Ops Manager UI 工具信息,特别标注了压缩和解压缩数据的耗时,以及文档的平均对象大小的下降数据。
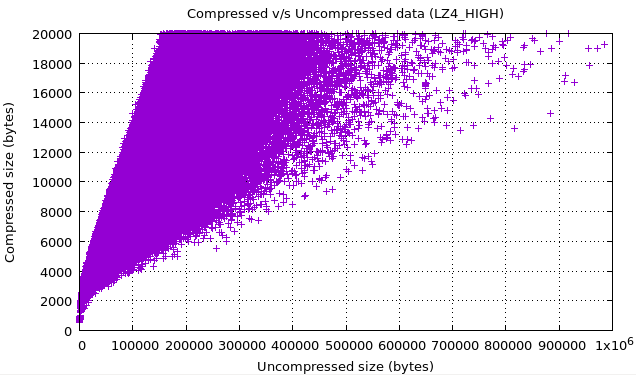
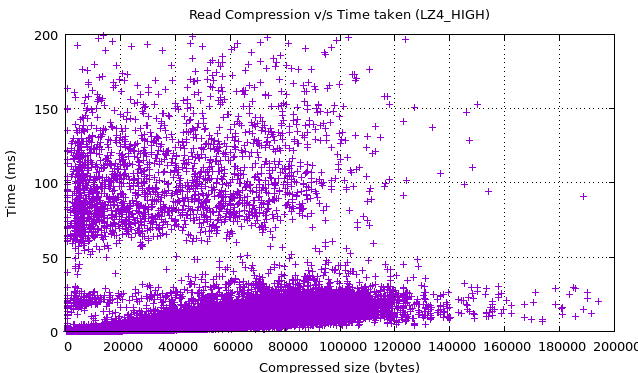
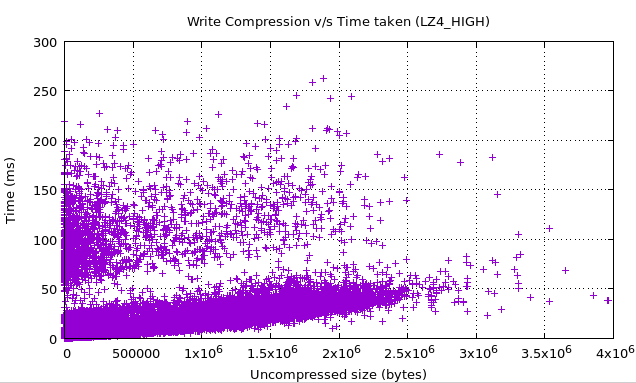
最终,对于生产环境下的随机一小时数据压缩,eBay 团队也收集了一些指标图,用于更多的深入观察。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




