Google 在 Tensorflow 的 Github 代码库中,发布了多个用在移动电话上的高效预训练计算机视觉模型。
这几个模型间的差别在于模型的参数、单图像处理的计算能力以及预测的准确性,开发人员可从中做出选取。从计算量上看,最小的模型具有 14 个百万次 MAC(乘加运算,Multiply-Accumulates ),最大的模型则具有 569 个百万次 MAC。要预测一个图像的类别,一个模型所需的计算量越大,所需使用移动设备的电量也越多。开发人员可以根据特定的应用,在准确性和所耗费电池电量间进行权衡。模型的性能及资源占用情况发布在Google 博客上,如下图所示。
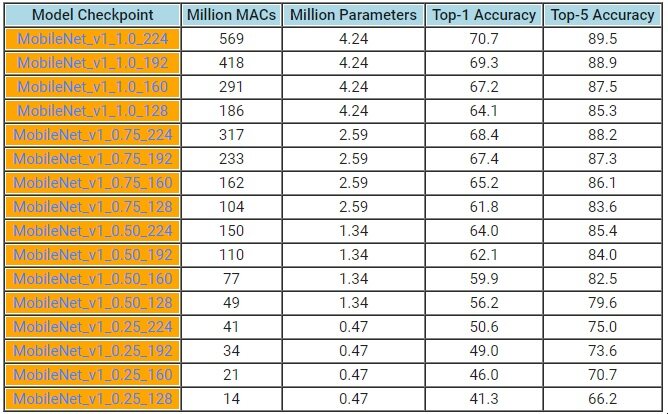
在智能电话上处理图像的性能,要优于将图像上传到在线处理服务(例如, Cloud API )。这也意味着数据完全不必离开智能手机,确保了了用户的隐私。这些模型是开源的,开发人员可直接下载,或是微调模型以适合自身的特定需求。
尽管这些发布的模型使用了更少的计算量,但是大多数模型所做出预测的准确性还是可与其它神经网络的表现相媲美的。在今年早先预发表的一篇研究论文中,阐述了MobileNets 更为高效的原因。
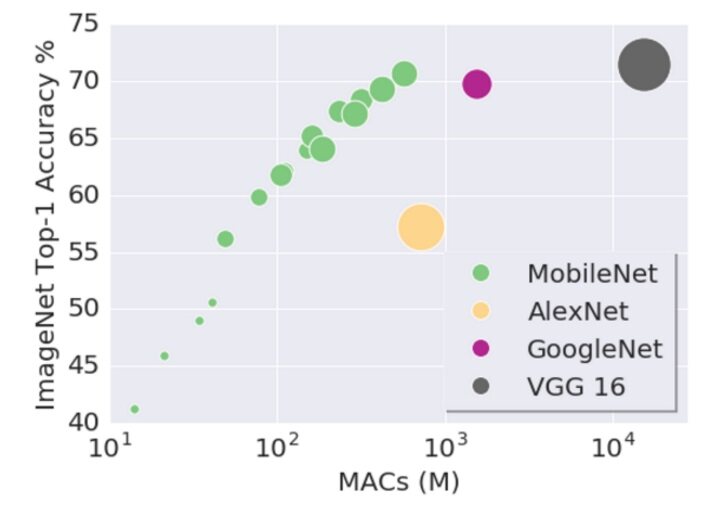
论文在 LSVRC 数据集上验证了模型的准确性。LSVRC 数据集是一个大规模的图像识别数据集。MobileNet 对每个图像给出五个标签预测结果,并使用“Top-1 Accuracy”和“Top-5 Accuracy”指标衡量了预测结果的准确性。“Top-1 Accuracy”表示预测结果中可能性最大的一个标签的确是图像真实标签的比例,“Top-5 Accuracy”表示预测结果中可能性最大的五个标签中包含了图像真实标签的比例。
有意着手去运用这些模型的开发人员,可以访问 Tensorflow Mobile 的主页。Tensorflow-Slim 图像分类库的更多信息,提供于Github 上。
查看英文原文: Google Released MobileNets: Efficient Pre-Trained Tensorflow Computer Vision Models




