信息技术发展突飞猛进,网络数据呈现爆炸之势,搜索引擎的实时性面临巨大挑战。百度搜索引擎每天处理着数万亿次的链接分析和数百亿次的互联网资源采集。作为百度搜索引擎的核心数据库 Tera,是如何支撑万亿量级的实时数据处理呢?
在 5 月 20 日百度开发者中心主办、极客邦科技承办的 71 期百度技术沙龙上,百度网页搜索基础架构技术经理齐志宏和资深工程师郑然,为大家免费放送了大型分布式表格系统 Tera 在百度搜索引擎中的应用、以及 Tera 架构设计与实践的全攻略。
Tera 在百度搜索引擎中的应用(讲义 PPT )
在讲解 Tera 的应用之前,百度网页搜索基础架构技术经理齐志宏首先介绍了百度搜索架构,百度搜索引擎的作用是连接人与信息、连接人与服务,信息抓取、索引构建、检索系统构成了搜索引擎最经典的三大板块。
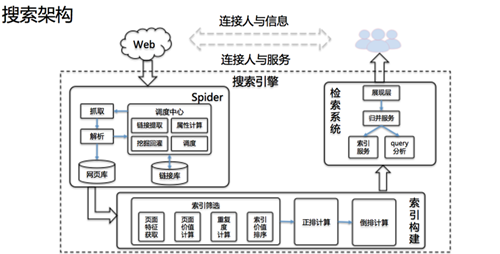
互联网上的信息是如何通过搜索引擎最终展示给用户的?首先,网页被搜索引擎发现,通过抓取进入搜索引擎;然后,有价值的网页经过筛选,进行正排计算和倒排计算,完成索引构建;最后,通过检索系统将最终的结果呈现给用户。
伴随互联网信息爆发式的增长,百度搜索架构也在逐渐向实时化方向演进,在介绍完搜索架构之后,齐志宏从链接存储、索引筛选、用户行为分析三个场景切入,详细讲解了 Tera 在实时搜索架构中的应用。
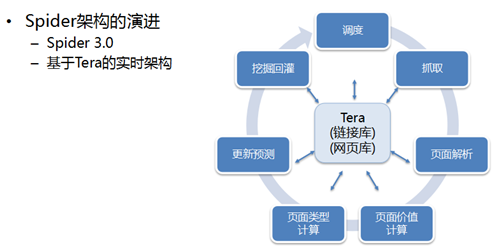
齐志宏先为大家解释什么是 Tera:一种大型分布式表格存储系统,具有高性能、可伸缩等存储特点,最初的设计是为了管理万亿量级的超链和网页信息。Tera 在架构演进中到底扮演了怎样的核心角色呢?
首先来看存储链接。百度推出的 Spider 3.0 系统是基于 Tera 的实时架构,以 Tera 为核心,承载了链接库、网页库的存储,将原有基于 MapReduce 的批量计算转变为基于 Tera 的实时计算,实现每秒亿级的数据随机读写、每天处理万亿量级的链接操作,信息抓取模块(即 Spider)进入了实时处理时代。
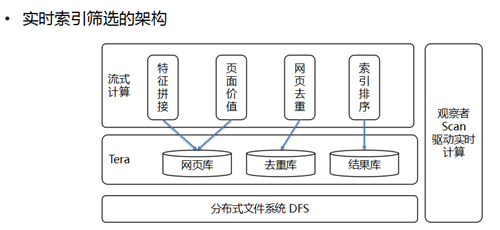
第二个是索引筛选。索引筛选的核心作用是让有价值的信息进入索引。Tera 架构作为数据存储中心,存储了包含网页库、去重库、结果库在内的所有中间数据和最终结果,通过流式计算的方式完成页面特征拼接、页面价值计算、网页去重以及索引排序等核心操作的实时化改造。网页从抓取到筛选完成的整个过程,实现了从天级变到分钟级甚至秒级的飞跃。
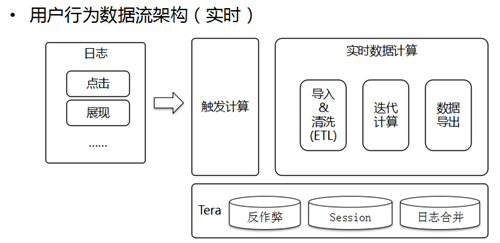
最后一个是用户行为分析。用户行为分析在搜索效果改进和搜索引擎的评价等方面,都具有重要价值。基于 Tera 的实时用户行为数据流,将用户数据的时效性推向新高度。实时数据产出的延迟可降至秒级,突发时效性识别、用户意图分析、产品迭代评估等多个维度均可实时获取用户数据,进行实时分析,对时效性和用户体验有很大的提升。
总体上,Tera 支撑了着搜索引擎大规模的实时数据读写,将批量、全量计算转变为增量、实时的数据计算,极大的提升了搜索引擎的实时数据处理能力,Tera 是百度搜索引擎从批量处理迈向实时计算的架构基础。
Tera 大型分布式表格系统的设计与实践(讲义PPT )
Tera 完成了百度搜索向万亿级数据实时搜索的跃进,成为炙手可热的数据库系统,那么,如何做好 Tera 架构的设计与实践成为开发者最为关心的问题。百度网页搜索基础架构资深工程师郑然在演讲过程中,围绕背景、数据模型、架构与设计、高可用实践以及性能优化等方面,详细讲解了 Tera 设计和实践过程。
郑然表示,百度搜索引擎面临三大业务特点,(1)数据量大,PB 到百 PB 这样的量级;(2)离线处理过程中,以站点等前缀方式访问数据是普遍的需求;(3)数据类型不固定。这样的业务特点决定着 Tera 设计和实践的过程。
Tera 设计的数据模型
Tera 的数据模型有以下几个特点,首先它是 Key-Value 模型,再深入一层,它是典型的 BigTable 模型,同时,一个非常重要的特点就是全局有序。这几个特点结合在一起,就是 Tera 数据模型的设计目标。

Tera 设计的系统架构
Tera 系统主要由 Tabletserver、Master 和 ClientSDK 三部分构成, 数据持久化到底层的分布式文件系统中。其中 Tabletserver 是核心服务器,承载着所有的数据管理与访问;Master 是系统的仲裁者,负责表格的创建、Schema 更新与负载均衡;ClientSDK 包含供管理员使用的命令行工具 Teracli 和给用户使用的 SDK。
表格被按 RowKey 全局排序,并横向切分成多个 Tablet,每个 Tablet 负责服务 RowKey 的一个区间,表格又被纵向且分为多个 LocalityGroup,一个 Tablet 的多个 LocalityGroup 在物理上单独存储,可以选择不同的存储介质,用以优化访问效率。
Tera 的高可用实践
Tera 的高可用性比较关键,直接影响整个系统的服务质量,其实现方式包括两个方面:Tablet Server 可用性以及负载均衡。
- Tablet Server 的可用性:1)Tablet Server 向 ZooKeeper 注册,利用 ZooKeeper 检测 Tablet Server 的存活;2)Tablet Server 挂掉之后,Master 收到 ZooKeeper 通知,进行 Tablet 迁移。具体迁移过程,会把挂掉的 Tablet Server 节点迁移到 Kick 节点上,当 Tablet Server 发现自己出现在 Kick 节点下面,自行退出。
- 负载均衡:负载均衡会直接影响整个集群的可用性,所以负载均衡更本质上来说是实现高可用的技术手段。影响 Tera 负载均衡的因素相对较少,主要在 SSD 容量、随机读和随机写这三个方面。针对上述影响因素, Tera 从两个层面来进行负载均衡策略的设计。首先平衡各个 Tablet Server 读请求 Pending 的数据量, 同时利用历史值来平滑负载短时间内抖动的影响 ; 其次根据 SSD 容量平衡各个 Tablet 的数据大小。
Tera 设计的性能优化
郑然表示,Tera 设计的性能优化,是百度在做设计过程中总结出来的,实用性较强。
第一个经验是需要考虑对分布式文件系统友好。Tera 的数据持久化在分布式文件系统上,必须考虑对其友好的使用。根据 LevelDb 的特点,数据首先要持久化在 WAL 上,确保异常情况下不丢数据,所以写 WAL 的延迟和吞吐直接决定了用户写请求的延迟和吞吐。然而分布式文件系统需要写多个数据副本,在某些副本异常情况下,如果依赖分布式文件系统层面去自动恢复的话,可能大幅增加延迟。Tera 针对写 WAL 异常情况,采用关闭旧文件创建新文件的方法,规避分布式文件系统的短板。同时 WAL 持久化成功才能保证用户数据不丢,所以 WAL 写完之后必须 sync 强制数据落盘,而 sst 文件不强制要求每次写请求落盘,从而减少对分布式文件系统的压力。
第二个经验是关于 SSD 的运用。SATA 的随机读能力很差,虽然 LevelDb 做了很多优化,但是仍然无法突破硬件瓶颈,SSD 的价格现在是越来越便宜,但成本依然比 SATA 高。Tera 的数据全部持久化在 SATA 上,仅把 SSD 作为 Cache 使用,这是平衡性能和成本的一种途径。
第三个经验是异步逻辑设计。Tera 里面所有可能阻塞的逻辑都是异步的,异步逻辑可以很好提高性能,另外客户端缓存 Tablet 位置信息,因为 tablet 位置信息通常情况下变化的也不频繁,同时扩展了 LevelDb 的 BloomFilter 机制,可以提升 20% 左右的读性能。




