Twitter 起步时正是服务器供应商统治数据中心的时代。自从那之后,Twitter 团队没有停止前进的步伐,他们一直致力于使用开源社区的网络、软件技术和硬件,高效地提升集群性能,发布尽可能强的产品。Twitter 目前的硬件使用情况分布如下:
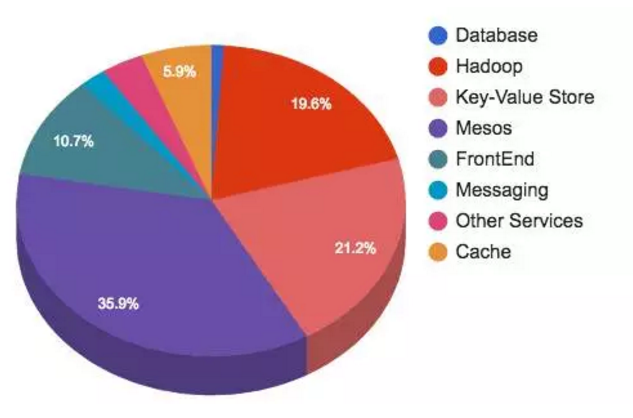
网络流量
2010 年初,Twitter 团队开始考虑将集群从第三方主机上迁出,这个决定和动作意味着 Twitter 团队需要学习如何构建和运行内部的基础设施,由于需要在有限的可视化情况下了解核心基础设施需求,团队开始调研各种网络设计、硬件,以及供应商。
到 2010 年下半年,Twitter 团队完成了第一个网络体系结构设计,解决了科罗拉多主机集群遇到的扩展性和服务问题。该方案有深度缓冲设计,支持对于突发的流量请求以及确保电信核心交换机在网络层没有超载。这个方案支撑了 Twitter 的早期版本,创造了一些比较出名的业绩,例如打破了 TPS 数据记录的“天空之城”事件(每秒处理 34000 条记录)以及应对 2014 年世界杯。
此后的几年时间里,Twitter 的数据中心运行在五大洲的成千上万的服务器,网络覆盖很广。从 2015 年上半年开始,Twitter 开始遭受到了成长过程中的痛苦,由于不断变化服务系统架构和增加容量需求,最终达到了数据中心物理可扩展性的上线,网状拓扑结构不再支持通过增加新的机架提升性能,即不再支持增加额外的硬件。另外,Twitter 现有的数据中心开始由于不断增加路由规模和复杂的网络拓扑结构导致出现不稳定异常情况。
为了解决这个问题,Twitter 开始将现有的数据中心转换为 Clos 拓扑 +BGP,这是一种必须在现场做的网络转换工作。尽管很复杂,但是 Twitter 在一个相对较短的时间内完成了这个转换,并且对服务影响最小。网络拓扑图看起来是这样的:
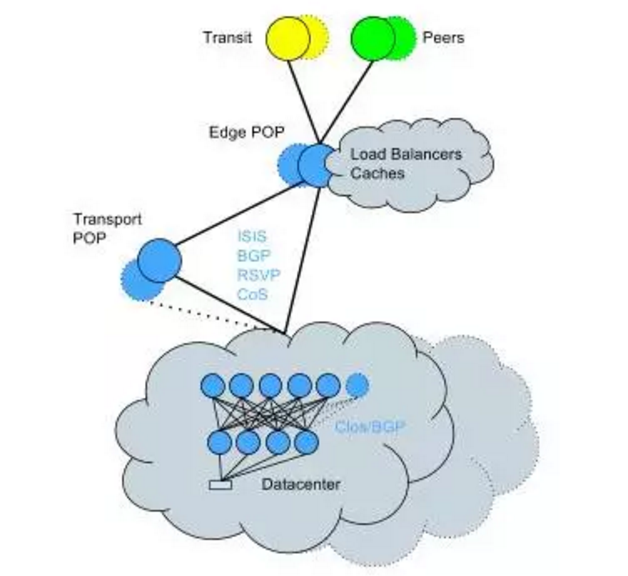
总结技术亮点如下:
- 单个设备故障具有较小的影响范围。
- 水平带宽缩放能力。
- 路由引擎较低的 CPU 开销;路由更新更高效的处理能力。
- 由于较低的 CPU 开销,更高的路由容量。
- 每个设备和链路上的更细粒度的路由策略控制。
- 不再重复发生之前的几个已知问题:包括增加协议收敛时间、路线流失问题和伴随固有的 OSPF 复杂性的不可预期问题。
- 启用无影响机架迁移方案。
数据中心
Twitter 的第一个数据中心是基于建模分析出的能力和已知系统的运行状态经验构建的。但是仅仅几年之后,数据中心比最初的设计扩大了 400%。现在,随着 Twitter 应用程序堆栈的演变,Twitter 正在变得更加分布式化,运行状态也在跟着变化。引导 Twitter 进行网络设计的最初假设场景已经不复存在了。
业务需求增长过快,导致针对整个数据中心进行重构已经不切实际。所以构建一个高可扩展的体系架构会让 Twitter 更容易增加能力,而不是采用叉车式的迁移方案。
高可扩展性的微服务需要高可靠性网络,可以支持处理各种业务。Twitter 的业务范围从 TCP 长连接到离线的 MapReduce 任务,再到超短连接。针对这类多样性业务需求的应对方案是,部署具有深包缓冲区的网络设备,但是这样会带来一系列问题:更高的成本和更好的硬件复杂度。之后的设计 Twitter 使用了更加标准化的缓冲区大小,以及在提供切断开关功能的同时,提供了更好的 TCP 栈服务器,这样可以更好的处理网络风暴问题。
骨干网络
Twitter 的骨干网流量每年都有大幅度正常,并且仍然可以看到数据中心之间的突发数据增长较正常状态的 3-4 倍情况存在。这种情况对于老的协议是一个特有的挑战,这些老的协议,例如 MPLSRSVP 协议,从来不是为应对突然爆发的网络风暴而设计的,它的目标是应对渐进式的缓慢的网络请求增长。为了获得尽可能快的响应时间,Twitter 不得不花费大量的时间调整这些协议。此外,Twitter 实现的优先次序可以处理网络高峰(特别是存储复制)情况。
Twitter 需要确保在任何时候优先客户的传输流量,可以通过延迟低优先级的存储复制工作满足这个需求,存储复制这类工作有一天时间的 SLA。这样就可以使用最大量的网络资源,让数据尽可能快速地移动。客户业务需求比低优先级的后台业务需求优先级高。而且,为了解决伴随着 RSVP 自动带宽而来的 bin-packing 问题,Twitter 实现了 TE++,这个工具当流量增加时创建额外的 LSP,当流量下降时则会删除 LSP。这使得 Twitter 可以有效地管理连接之间的网络业务,同时减少维护大量的 LSP 所造成的 CPU 负担。
然而主干网从最初开始就缺少任何业务工程设计,后来增加了帮助 Twitter 可以根据业务增长进行扩展的特性。为了实现这一点,Twitter 完成了角色分离,使用单独的路由器分别处理核心和边缘路由请求。这也使得 Twitter 能够低成本效益地扩展,而不需要购买复杂的带边缘功能的路由器。
在边缘路由层,Twitter 有一个核心连接所有网络,并且可以支持水平扩展,例如每个站点有很多路由器,不止两个,因为 Twitter 有一个核心层互联所有的设备。
为什么扩展路由器的 RIB(路由信息库,即 Routing InformationBase),Twitter 引入了路由反射机制,这样就可以适配扩展需求,但是在做这个的过程中,需要移植到变更设计,Twitter 也做了路由反射的客户端!
存储设计
每天有数以百万计的的推文(微博)被发送出来。这些推文需要被处理、存储、缓存、服务以及分析。对于如此庞大的信息内容,Twitter 需要一个稳定的基础设施。存储和消息占据了 45% 的 Twitter 的基础设施空间。
存储和消息团队提供了如下服务:
- 用于运行计算和 HDFS 的 Hadoop 集群
- 用于所有的低延迟键值存储的 Manhattan 集群
- Graph 用于存储 MySQL 集群存储分片
- Blobstore 集群用于所有的大型对象(视频、图片、二进制文件等等)
- 缓存集群
- 消息集群
- 关系型存储(MySQL、PostgreSQL 以及 Vertica)
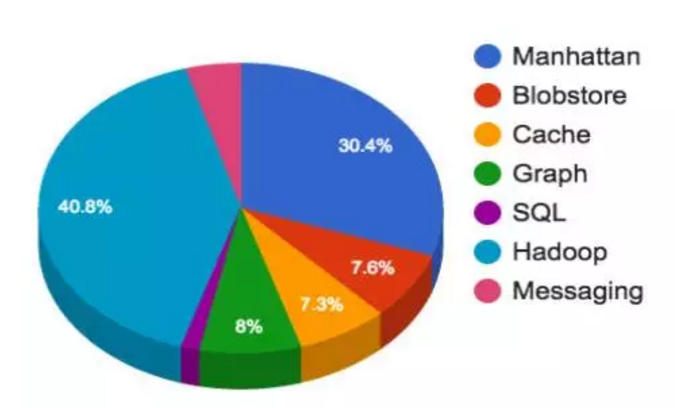
在这个规模的多租户领域,Twitter 遇到了一些困难,其中有一个是必须解决的问题。很多时候客户有一些很奇怪的用例,这些用例实施后会影响其他租户,这种案例带来了专有集群设计。许多专有集群增加了运行的工作量用于保持程序运行。
Twitter 的集群设计没有什么特别的,不过倒是有一些有意思的地方可以分享:
- Hadoop:Twitter 有多个集群存储了超过 500PB 的数据,这些数据被分为四组(实时数据、处理数据、数据仓库,以及冷数据仓库)。Twitter 最大的集群有超过 1 万个节点组成。该集群每天运行 15 万个应用程序,启动 13 亿个容器。
- Manhattan(Tweets、直接消息、Twitter 账号以及其他一些东西的后端):Twitter 运行了一些集群针对不同的用例,例如大型多租户、小型的非常用功能、只读的,以及针对重写 / 重读业务模式下的读写。只读集群可以处理几千万 QPS,而读 / 写集群可以处理百万级的 QPS。Twitter 观察到的性能最好的集群每天处理几十万的写请求。
- Graph:Gizzard/MySQL 这样的基于分片的集群用于存储 Twitter 的图片。这个集群可以管理顶峰时间段千万级别的 QPS,平均到每台 MySQL 服务器大约 3 万 -4.5 万 QPS。
- Blobstore:Twitter 的图片、视频,以及大型文件的存储量已经达到了数以百亿计。
- Cache:Redis 和 Memcache 集群,缓存 Twiiter 用户、时间表、推文,以及其他一些内容。
- SQL:包括 MySQL、PostgreSQL 和 Vertica。MySQL/PosgreSQL 被用于强一致性场景,就像内部工具一样管理广告活动、广告切换。
Hadoop/HDFS 也是日志管道的后端存储,但是在过渡到 Apache Flume 的最后的测试阶段,作为一种替换方案解决了选择客户端聚合时缺乏速率限制、缺乏传递类型保证等局限性,并且解决了内存奔溃问题。Twitter 每天处理一兆条信息,并且所有的信息被处理后超过 500 个类别,然后有选择地在所有集群内拷贝。
缓存设计
虽然缓存只占用基础设施的 3%,但是它确实对于 Twitter 很关键。缓存保护后端存储层远离业务风暴,允许存储流动成本很高的对象。Twitter 在巨型规模内使用了几款缓存技术,例如 Redis 和 Twemcache。更具体地说,Twitter 有一个专用和多租户混用的 Memcached(twemcache)集群,以及夜鹰集群(分布式 Redis)。Twitter 也迁移了几乎所有的主要的缓存到 Mesos,以降低运行成本。
对于 Cache 来说,扩展性和性能是首要挑战。Twitter 运营了数个集群,总计每秒 320M 数据包的数据包速率,提供超过 120GB/s 的数据给客户,Twitter 的目标是即便在高峰段,也要确保每次响应的延迟约束在 0.1% 到 0.01% 之间。
为了满足 Twitter 的高吞吐量和低延迟服务水平目标(SLO),Twitter 需要持续测试系统性能,寻找更有效的优化方案。为了帮助内部做到这一点,Twitter 写了 rpc-perf 工具,更好地理解缓存系统是如何工作的。当 Twitter 尝试从专有机器上迁移到现在的 Mesos 基础设施时这个工具的作用就很重要了,帮助制定了容量规划。这些优化努力的结果是 Twitter 在没有延迟的基础上每台机器的吞吐量提升了一倍以上。Twitter 仍然坚信存在很大的调优空间。
Twitter 作为一家互联网服务提供商,它在建设通信软件服务时遇到的网络问题、软件系统架构问题、软件技术选型等等都值得我们学习。Twitter 发表的文章有助于读者从整体理解互联网软件开发、发布、问题解决等整个体系结构相关知识,也帮助读者从侧面完成技术选型。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




