Netflix 最近推出了 Hollow ,一款 Java 库和工具包,旨在有效缓存不属于“大数据”的数据集。这些数据集可能是电子商务和搜索引擎的元数据,或者是 Netflix 电影和电视节目的元数据。处理这种数据集的传统方法包括数据存储或串行化,但这可能会有可靠性和延迟问题。Hollow 的入门指南中总结了核心概念和命名方法:
Hollow 管理由单个 _ 生产者 _ 构建的数据集,并向一个或多个 _ 消费者 _ 传送以用于只读访问。数据集会随着时间而改变。改变的数据集的时间线可以分为离散的 _ 数据状态 _,每个状态都是那个特定时间点数据的完整快照。
生产者和消费者通过在数据状态之间转换的 _ 状态引擎 _ 来处理数据集。生产者使用 _ 写状态引擎 _,而消费者使用 _ 读状态引擎 _。
Hollow 取代了 Netflix 原先的内存数据集框架 Zeno 。数据集现在用紧凑的、固定长度的、强类型的数据编码表示。这种编码最小化了数据集占用的空间,并将编码记录“打包在 JVM 堆上合并的可重用内存条中,以避免影响繁忙的服务器上的 GC 行为。”
入门
要开始使用 Hollow 示例,请参考以下 POJO:
public class Movie {
long id;
String title;
int releaseYear;
public Movie(long id,String title,int releaseYear) {
this.id = id;
this.title = title;
this.releaseYear = releaseYear;
}
}
上述 POJO 上简单的数据集可以这样填充:
List<Movie> movies = Arrays.asList(
new Movie(1,"The Matrix",1999),
new Movie(2,"Beasts of No Nation",2015),
new Movie(3,"Goodfellas",1990),
new Movie(4,"Inception",2010)
);
Hollow 将这样的 movies 列表转换为新的编码形式,如下所示:
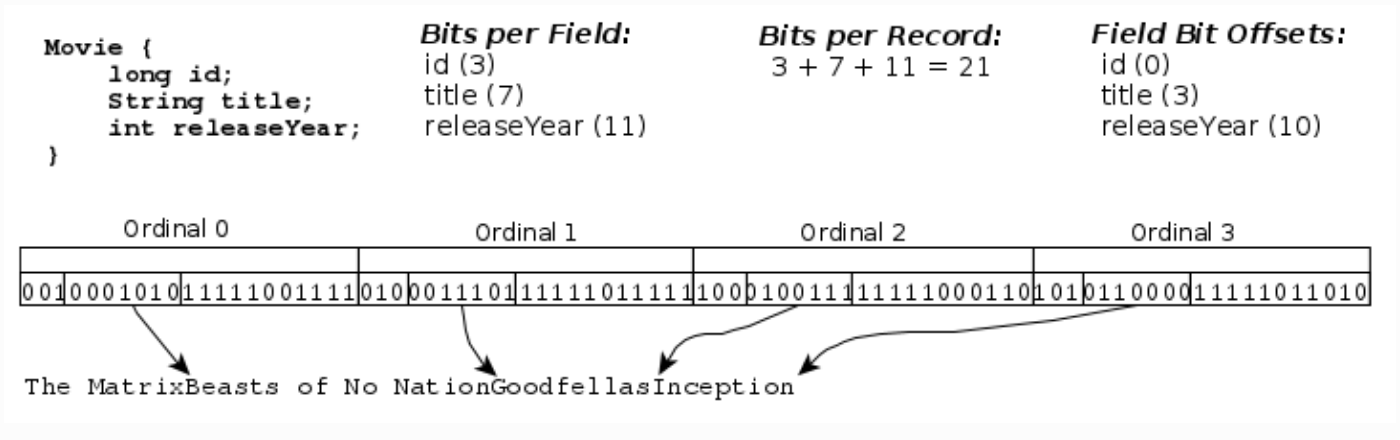
有关编码的更多详细信息,请参阅 Hollow 网站的高级主题章节。
生产者
生产者的第一个示例发布了数据集(本例中的电影)的初始数据状态,并通知消费者在哪里找到该数据集。对数据集的后续更改会系统地发布并传送给消费者。
生产者使用 HollowWriteStateEngine 作为数据集的句柄:
HollowWriteStateEngine writeEngine = new HollowWriteStateEngine();
HollowObjectMapper 填充 HollowWriteStateEngine:
HollowObjectMapper objectMapper = new HollowObjectMapper(writeEngine);
for(Movie movie : movies) {
objectMapper.addObject(movie);
}
HollowObjectMapper 是线程安全的,也可以并行执行。
生产者将数据集(也称 blob)写入定义的输出流:
OutputStream os = new BufferedOutputStream(new FileOutputStream(snapshotFile));
HollowBlobWriter writer = new HollowBlobWriter(writeEngine);
writer.writeSnapshot(os);
为消费者生成 API
客户端 API 基于数据模型生成必要的 Java 文件,并且必须在写入初始的消费者源代码前执行:
HollowAPIGenerator codeGenerator = new HollowAPIGenerator(
"MovieAPI", // a name for the API
"org.redlich.hollow.consumer.api.generated", // the path for generated API files
stateEngine); // the state engine
codeGenerator.generateFiles(apiCodeFolder);
消费者
一旦通知消费者已发布的数据集,消费者使用 HollowWriteReadEngine 作为数据集的句柄:
HollowReadStateEngine readEngine = new HollowReadStateEngine();
HollowBlobReader 将 blob 从生产者消费到 HollowReadStateEngine:
HollowBlobReader reader = new HollowBlobReader(readEngine);
InputStream is = new BufferedInputStream(new FileInputStream(snapshotFile));
reader.readSnapshot(is);
通过生成的 API 可以访问到数据集中的数据:
MovieAPI movieAPI = consumer.getAPI();
for(MovieHollow movie : movieAPI.getAllMovieHollow()) {
System.out.println(movie._getId() + ", " +
movie._getTitle()._getValue() + ", " +
movie._getReleaseYear());
}
这将打出结果输出:
1, "The Matrix", 1999
2, "Beasts of No Nation", 2015
3, "Goodfellas", 1990
4,"Inception", 2010
完整的 Hollow 项目可以在 GitHub 上找到。
InfoQ 最近和 Netflix 高级软件工程师及 Hollow 主要贡献者 Drew Koszewnik 进行了详细的访谈,讨论了Hollow 的具体实现细节。
查看英文原文: Netflix Introduces Hollow, a Java Library for Processing In-Memory Datasets




