本月初,Kubernetes 在其官网上宣布了百度的 PaddlePaddle 成为目前唯一官方支持 Kubernetes 的深度学习框架。PaddlePaddle 是百度于 2016 年 9 月开源的一款深度学习平台,具有易用,高效,灵活和可伸缩等特点,为百度内部多项产品提供深度学习算法支持。两个开源项目的结合意味着深度学习对于广大开发者正变得“触手可及”。还有呢?
一、编者按
AlphaGo 围棋之战引燃了人工智能,也激发了技术圈的研究热情;江湖传言其单个训练作业要依赖数千个 GPU,而更有人猜测规模恐怕远超于此,纵然 Google 对其使用的集群规模等技术细节三缄其口,也没有阻挡住技术人探索的脚步。机器 / 深度学习作为人工智能领域中的重要分支,有着如 TensorFlow、Torch、Theano、Caffe 等不少的开源项目,PaddlePaddle(PArallel Distributed Deep LEarning)是百度于 2016 年 9 月开源的一款深度学习平台,具有易用,高效,灵活和可伸缩等特点,为百度内部多项产品提供深度学习算法支持。
这套打磨逾三年的技术,需要在大规模集群上进行分布式作业。如何启动系统并将分散的资源和众多的学习任务良好匹配是一个无法回避的技术问题。问题总是相似的,容器技术也面临着如何简单地管理好分散的物理计算资源这个难题。解决方案之一 Kubernetes 是 Google 为生产环境设计的开源的容器管理调度系统。
本月初,Kubernetes 在其官网上宣布了百度的 PaddlePaddle 成为目前唯一官方支持 Kubernetes 的深度学习框架。两个开源项目的结合意味着深度学习对于广大开发者正变得“触手可及”。为什么会有这样的组合?PaddlePaddle on Kubernetes 的意味着什么?如何看待深度学习拥抱容器技术?带着这些问题 InfoQ 采访了博客文章的原作者百度王益和 CoreOS 李响探求更多的技术内容,同时还采访了 Kubernetes Project Manager、HyperHQ 项目成员 张磊,本文整理自三位嘉宾的采访素材。
二、大规模深度学习遭遇痛点
在人工智能专家王益博士看来,现代的人工智能是建立在大数据基础之上的,而大数据的主要来源有两个:互联网服务的 log(记录用户行为)以及通过各种 crawler 采集的外部数据。在具体落地上,对于工业级应用,需要把从 Web 服务到内外部数据收集和处理的整个通道,都与 AI 建设在一个机群上,才能实现高效的知识提取,然后将结果反馈从而提升服务质量。
在百度,分布式深度学习平台 PaddlePaddle 在徐伟博士的带领下经过三年多研发和打磨,已经应用于包括搜索、翻译、电商和计算基础架构等方面共五十余个应用,该项目现已开源。王益在成为百度 PaddlePaddle 团队负责人之后,非常希望该项目可以更容易地部署与运行。
王益在与李响等容器专家们的交流讨论之后,PaddlePaddle on Kubernetes 项目于 2016 年 10 月拉开帷幕。
Kubernetes 可谓容器生态圈的当红明星,业界甚至有人断言 “Kubernetes 已经赢得了容器生态的圈地战争”;在李响看来,Kubernetes 将会是今后的云管理平台的统治者。
PaddlePaddle on Kubernetes 也恰好符合于 Kubernetes 社区所喜闻乐见的,后者希望将一些流行的应用在 Kubernetes 上原生运行起来,可以让更多人感受到 Kubernetes 的神奇之处。
三、Kubernetes 被用来做哪些事情?
Kubernetes 把很多分散的物理计算资源抽象成一个巨大的资源池,它利用这些资源来帮助用户执行计算任务。对于用户来说,操作一个分散的集群资源可以像使用一台计算机一样简单。
对于这个项目,Kubernetes 主要负责将学习任务分配到集群的物理节点上进行运算;如果遇到任务失败的情况,Kubernetes 会自动重启任务。
具体而言,技术层面需要通过实现 fault-tolerable 的训练——AI 作业在进程数量发生变化的时候不要暂停或者失败——来实现机群里各个作业的 auto-scaling。Kubernetes 可以把很多并发进程组织成 service,并且实现 auto scaling——白天用户数量多的时候,增加 Web service 里的进程数,减少 AI 作业的进程数。晚上减少 Web service 里的进程数,释放资源给 AI 作业。
四、为什么是 Kubernetes,而不是其他?
除了 Kubernetes 之外,还有 Mesos、Fleet 和 Swarm 等容器调度方案。目前还没有一个开源深度学习框架和 Kubernetes 深度结合,那为什么百度选择了 Kubernetes 呢?
在王益看来,现有容器调度方案们各有千秋,但是 PaddlePaddle 兼容 Kubernetes 是开源社区用户的选择。
PaddlePaddle 最初在百度的集群上运行。但是 PaddlePaddle 并不依赖特定的并行计算平台——只要有办法在一个平台上启动 PaddlePaddle,就可以运行分布式训练作业。百度的大数据团队(BDG)的同学们做了一套 PaddlePaddle on Spark 系统,确保 PaddlePaddle 和 Spark 的兼容。而 PaddlePaddle on Kubernetes 要感谢社区贡献了。
到目前为止,PaddlePaddle on Kubernetes 的结合工作也不是百度的 PaddlePaddle 开发团队做的,而是由 CoreOS 公司的 etcd 项目负责人李响、百度上海 JPaaS 团队的周倜、陈国彦、CISCO 硅谷办公室的 tech lead 陈曦以及百度美研 ADU 团队的王鹤麟做的。同时,PaddlePaddle 正在和 Kubernetes 社区合作这项工作,王益称期待尽快给大家带来一个惊喜。
五、为什么社区技术人如此喜爱 Kubernetes?
在容器圈专家张磊先生看来,相对而言,Kubernetes 确实是最好的技术选择。
单纯就离线计算业务而言,“老”项目 Mesos 在大数据领域被大规模应用多年,固然有着明显的优势。但是,要更好地支持深度学习框架作业,Mesos 的资源管理和调度能力只能说是锦上添花的功能。
能不能将框架的作业和任务模式,同“容器”这个全新的部署概念匹配起来,才是现阶段最重要的。毕竟,如果框架连正常运行起来都很困难,再好的资源利用率提升机制也没有用武之地。在这一点上,Kubernetes 应该说是现有的容器管理项目中做的最好的。
就比如前面已经说过它的 Pod 设计,就能很好地跟 Paddle 的作业模型匹配:一个 Pod 里放两个容器,分别是参数服务器(parameter server)和训练器(trainer)。这个匹配并非巧合,而是因为 Kubernetes 从一开就认为容器之间往往存在像这样紧密的协作关系,这是“lesson learned from Borg”。只不过在过去,大家都只关注在容器里运行简单 Web 服务的时候,才会认为 Pod“没什么用”。
除了 Pod,Kubernetes 提出的比如 Replica(容器副本),Job(计算型任务),StatefulApp(有状态应用)等诸多已经被业界采纳为标准的编排概念,都体现出了这个项目在容器作业管理方面独到的技术视野(虽然还一度被国内用户诟病为理念太超前),这一点上其它项目与 Kubernetes 之间存在着 follower 和 leader 的差距。实际上,Kubernetes 不仅简单地解决了容器业务部署和运行的问题,它还关注如何帮助用户构建容器化分布式服务这个问题,对于在容器化道路上尚需要“摸着石头过河”的用户来说,这是非常重要的。
相比之下,Docker 的集群模式(Swarm 模式)关注的范畴要小很多,相当于 Kubernetes 在应用管理方面的一个子集。它的关注重点之一是用户友好,但也为此牺牲了不少可扩展性。对于开发者而言,比如做一个 PaaS,这是够用并且很方便的,但是如果要依赖于它作为基础设施、甚至在它之上再构建另一套更复杂的系统,这个集群模式就比较难胜任了,如果这中途还需要自己定制和扩展的话,会更加困难重重。
不过 Kubernetes 也还存在不足:首先,作为一个正在快速演进的项目,Kubernetes 本身有很多特性亟待完善,说的直白一点就是潜在的坑还是很多的,这也是采用新技术的必然代价。好在 Kubernetes 的社区足够繁荣,一定程度上能够弥补一些。其次,相比于 Swarm 模式的用户友好程度,Kubernetes 的 Geek 气息依然太浓,很多时候需要用户自己拿主意(比如“故意”不提供内置的跨主网络和分布式存储方案)。
总体上看,要支持 PaddlePaddle、Tensorflow 这样非云原生应用(多容器协作,甚至有状态)项目,Kubernetes 目前是个最佳的选择。
六、对容器圈而言,这是一个里程碑事件
PaddlePaddle on Kubernetes 项目的消息一经发布,技术圈内反响强烈。容器圈专家张磊先生,他告诉 InfoQ 早期的小道消息是在 InfoQ 的 CNUTCon 全球容器技术大会 2016(注:王益、李响和张磊三位大牛均为大会的讲师,技术圈的学习交流社交哦~)的讲师晚宴获知的。当时对 Kubernetes 的 roadmap 有了很多讨论,后来百度 JPaaS 组负责了项目的实施。
在张磊看来,这次 PaddlePaddle 与 Kubernetes 框架的深度集成算得上一个里程碑事件。容器与容器编排管理技术在过去两年里的迅猛发展跟去年人工智能集中式的爆发终于产生了深度的化学反应,也让我们看到一套完善的容器编排与调度体系确实能够为技术人员带来更多价值,而非“空有热度”。这一点是非常重要的,容器热潮的兴起,源自于对的云原生应用(比如轻量级的 Web 服务)的完美支持,但容器云技术能否最终落地,还取决于它能不能对非云原生应用(传统服务、复杂应用)有良好的支持和扩展,深度学习框架正是非云原生应用的一个典型案例。
七、容器化实施深度学习的优点
事实上,2016 年人工智能热点爆发的一个强有力推动者正是同样源自 Google 的 Tensorflow 项目,它也很早就进行了同 Kubernetes 的集成工作。只不过由于师出同门,Tensorflow 集成的案例说服力一般。但是现在我们再参考 Paddle 的集成工作,我们不难看到容器编排和调度平台对于这类框架的一些独有优势。
轻量级
这个轻量级不只只是跟 OpenStack 比,而是因为哪怕是虚拟机,我们也可以通过 HyperContainer 的方式接入 Kubernetes,继续对用户提供秒级的响应能力。这种敏捷性是至关重要的,我们通常都喜欢把容器跟 CI/CD 联系在一起,说能够快速迭代交付云云。实际上,深度学习的训练过程,才是真正对“快速迭代”有着关键需求的作业方式,在这一点上,容器的轻量级特性就凸显出来了。
更高的资源利用率
深度学习框架的最终目的是提供 AI 服务,而不是做“挖矿机”,所以任何一个从业者都不可能像比特币那样不计成本的投入计算资源。相比于使用物理机或者虚拟化来做计算任务的管理,容器这种操作系统层面的进程封装已经被证明能够大大提高作业的部署密度,而 Borg 等知名项目所提供的理论支持,也对基于容器做资源利用率的进一步提升指明了方向。
基于容器的设计模式
深度学习框架不同于常规 Web 服务,它有着自己独有的作业组织和部署模式,一个作业往往需要多个任务协作完成,这就对下层的容器编排和调度系统的设计提出了更高的要求。Kubernetes 项目使用 Pod 这个概念使用户能够使用一组容器来完成一组相互协作的任务的编排。这套组织和调度容器的理论被业界成为为容器设计模式,这是基于容器支持深度学习框架另一个独有的优势,用虚拟机或者裸机都很难模拟。
高度的可扩展性和容错能力
这个不多说了,容器对于构建可扩展的分布式服务的便利程度已经被国内外企业实践过了。
八、容器化实施深度学习的挑战
容器管理技术的普及也就最近几年的时间,Kubernetes 也是非常年轻的项目,无论跟哪个深度学习框架都不可能 100% 贴合。接下来容器管理平台要着重解决的包括:
计算型作业(Job)的管理和调度
当前 Kubernetes 的 Job 特性虽然在容器管理领域内算得上是佼佼者,但是跟已经成熟多年的大数据框架相比还差距甚远的。这一部分的功能进一步完善、甚至能直接对接大多数计算框架已经是板上钉钉的事情。
GPU 支持
Kubernetes 对 GPU 支持的投入力度一直很大,目前也走在容器管理领域的前列。但 GPU 支持对于主流容器技术来说也只是刚刚起步,相比于物理机器和容器对 CPU 资源管理的完善程度,容器平台在 GPU 设备管理、GPU 资源共享、多 GPU 支持、OpenCL 等 GPU 框架支持上还有非常多的空白需要填补。目前这些都已经出现在 Kubernetes 的路线图上。
更高级的资源管理
Kubernetes 在资源管理模型设计上继承于 Borg,但是相比于前辈强大的资源分配和共享机制,现有的模型在支持计算型任务还很初步,也不能实现离线业务和在线业务高效混部、抢占,也不支持动态的资源边界。所以这一部分的优化空间还是非常大的,对于进一步提升深度学习作业的效率也非常重要。
九、PaddlePaddle on Kubernetes 项目技术细节
兜兜转转讲了很多宏观的内容,那么现在让我们看看项目的技术细节吧。
1、分布式训练
PaddlePaddle 是一个诞生在工业界的系统,从一开始就强调支持分布式训练。
在 PaddlePaddle 诞生的年代里,并没有今天这么多的开源深度学习框架。所以 PaddlePaddle 的很多设计,在当时都是领先的。其中一些重要的设计决定直到今天都是很独特的。
PaddlePaddle 有 parameter server,但是设计思路和 Google 在 DistBelief 论文中描述的 parameter server 很不一样。DistBelief 中的 parameter server 主要是为了能训练很大的模型(model parallelism)而设计的。每个 trainer 进程和每个 parameter server 进程都只拥有模型的一块(一部分)。PaddlePaddle 的 parameter server 也支持这样的使用模式,但是这么大的模型并不常见,所以 parameter server 的使用模式更经常是用来加速网络通信。在这种使用模式下,每个 trainer 都有整个模型,但是每个 parameter server 只拥有模型的一部分。
通信模式如这篇博客中图一所示。
http://blog.kubernetes.io/2017/02/run-deep-learning-with-paddlepaddle-on-kubernetes.html
百度经过证明,认为这种通信模式和 HPC 中经过多年来持续优化的 ring-based AllReduce 算法的效率是一样的。而且当模型的梯度矩阵比较稀疏的时候,甚至效率更高。
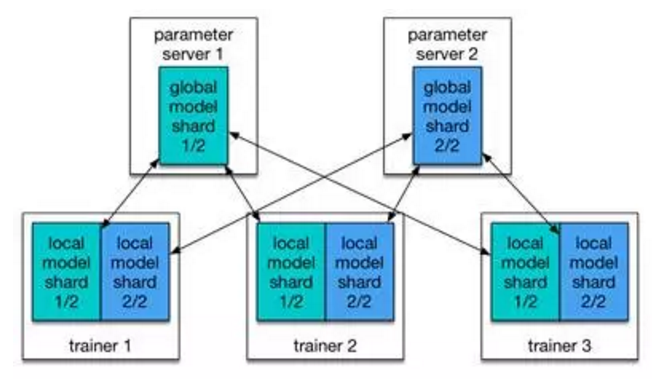
之前在百度里很多训练作业的配置是:trainers 进程和 parameter servers 进程的数量一样。但是其实不一定要是是一样的。百度希望努力做到根据机群的实际情况,自动动态启动或者杀死一些进程,使得作业的效率在规定的硬件使用下最高。Kubernetes 负责将学习任务分配到集群的物理节点,并且在任务失败时,实现自动对任务进行重新启动。
2、映射还是静态的,将会实现动态
目前主流的开源深度学习框架都没有动态任务分发机制,而 PaddlePaddle 也还不能实现动态的协调和容错。
非动态的映射有两个缺点:
整体学习任务有可能被延迟甚至终止
在并发规模不是很大的时候,数据分片到 trainer 的静态映射是没问题的。但是当训练规模变大,或者训练在通用机群(general-purpose clusters)上进行的时候,经常会碰到有些 trainer 被更高级别作业挤压杀死的情况。此时,其他 trainer(或者 parameter servers)如果要等待所有 trainer 的 gradients 的话,训练作业就陷入死结(halt)了。
资源利用率不能达到最优化
在学习过程中即使有更多的资源可以使用,也不能动态的增加资源。
王益称 PaddlePaddle 已经有一个 design doc 来实现任务的动态分配——引入一个 master 进程,负责把逻辑数据分片分发给“活着的”trainers 进程。这个设计同时考虑到如何用类似 Google MapReduce 框架的做法,实现训练作业的“不死”——即便一些 trainers 或者 parameter servers 被杀了(抢占了),训练作业也能继续进行,只是速度稍慢。当机群上其他高优先级作业结束之后,Kubernetes 会增加作业里的 trainers 数量,此时作业的进行速度也就自然更快了。
李响称希望今后利用 etcd 这样的分布式协调系统来专门为 PaddlePaddle 设计一个全局动态管理者组件。这个组件可以帮助 PaddlePaddle 动态地调节资源使用,在集群中有剩余资源的情况下增多学习者,对完成的部分任务设置检查点等等。
十、未来,敬请期待
对百度而言,PaddlePaddle 的目标从来都不是一统江湖,他们认为只有通过鼓励新的创新不断出现,才能维护好整个深度学习社区的健康。这样 PaddlePaddle 也才有机会借鉴和学习新的创新思路。PaddlePaddle 只有一个版本,内外部都使用开源版本。百度不会做 openwashing(伪开放)。
当然,没有完美的系统。和很多项目一样,PaddlePaddle 面临着不断增加新功能和维持好代码的精炼简洁之间的矛盾。百度告诉 InfoQ 通过借鉴 Keras、mxnet、和 DyNet 的长处,最近在重构 PaddlePaddle 的 API,接下来要重构分布式计算方法。希望持续保持好 PaddlePaddle 的健康状态,并期待三月初给大家带来一个更加易学易用的 PaddlePaddle。
PaddlePaddle on Kubernetes 这个项目的执行,是社区的功劳,而并非百度 PaddlePaddle 团队成员的工作。PaddlePaddle 社区会努力和 Kubernetes 进一步深化合作,把深度学习对机群管理的需求不断提给 Kubernetes 社区,帮助 Kubernetes 在支持 Web 服务和数据处理之后,也支持好 AI。
对于 PaddlePaddle 和 Kubernetes 融合这个项目来说,在当下更关注的是对开发者友好,因为在初级阶段,需要的是更快速地迭代开发普适的功能,而不是局限于去支持现有特定的企业级应用。当项目收获到越来越多开发者反馈的时候,逐渐成熟并具备强稳定性时,才会考虑根据企业具体情况增加功能。
作者介绍
王益,现任百度深度学习研究院资深科学家,超大规模人工智能系统专家。曾是硅谷 AI 创业公司 Scaled Inference 创始科学家,LinkedIn 高级主任数据科学家,腾讯社交广告技术总监,Google 研究员。2012 年开发的 Peacock 系统是语意理解系统的世界纪录保持者,利用三千 CPU 从数百 TB 数据中归纳和理解一百万小众语意。
李响,CoreOS 分布式项目主管,开源项目 etcd 作者。目前负责 Kubernetes、etcd 等分布式系统相关项目在 CoreOS 的开发工作,主要兴趣在于分布式一致协议、分布式存储、分布式系统调度等。
张磊,HyperHQ 项目成员,Kubernetes Project Manager 和 Feature Maintainer。曾任浙江大学科研人员并著有技术书籍《Docker 容器与容器云》。目前主要关注大规模容器集群管理和虚拟化容器运行时技术。




