本文对 GitLab 事件进行了全盘回顾,继续追踪 GitLab 在 2 月 1 日发布的申明,追溯各种问题根本原因。然后陈列了恢复在线后,GitLab 声明了哪些下一步举措。最后摘录了一些网友在 Twitter 和 YouTube 的评论,大多数人都对 GitLab 表达了自己的支持和宽容。
事件总览
2017 年 1 月 31 日 18:00(UTC 时间),GitLab 通过推特发文承认 300GB 生产环境数据因为 UNIX SA 的误操作,已经被彻底删除(后发文补充说明已经挽回部分数据),引起业界一片哗然。
2017 年 2 月 1 日 18:14(UTC 时间),GitLab.com 恢复在线。通过使用一个之前的 6 小时备份数据库,GitLab 申明 1 月 31 日下午 17:20(UTC 时间)至晚上 23:25(UTC 时间)之间的数据已经被恢复并可以在生产环境使用,包括项目、问题、合并请求、用户、注释等等。
GitLab 背景
GitLab 目前是硅谷一颗冉冉升起的新星,它估值 3.29 千万美元并且存放着宝贵的用户数据。
GitLab 是基于 Ruby on Rails 开发的一个开源的版本管理系统,它实现了一个自托管的 Git 项目仓库,支持通过 Web 界面进行访问公开的或者私人项目。
GitLab 拥有与 Github 类似的功能,能够浏览源代码,管理缺陷和注释。可以管理团队对仓库的访问,非常易于浏览提交过的版本并提供一个文件历史库。团队成员可以利用内置的简单聊天程序进行交流。此外,GitLab 提供了一个代码片段收集功能,可以轻松实现代码复用,便于日后有需要的时候进行查找。
自 2012 年上线以来,GitLab 已经被超过 10 万个公司或组织使用,包括 IBM、Alibaba.com、Uber、Intel、VMWare 等等。
事件影响
一句话概述
GitLab 申明指出其一个数据库出现了异常,导致 GitLab.com 丢失 6 个小时的数据库数据(问题、合并请求、用户、注释等等),不过 Git / wiki 存储库和自托管安装不受影响。
五点详情
- 大约 6 个小时的数据丢失
- 大约丢失 5037 个项目(其中 4613 个常规项目,74 个 fork, 350 个 import)。由于 Git 的 repository 没有任何损失,所以 GitLab 可以重建数据事故之前已经存在的用户 / 组的全部项目,但是并不能修复事故中的任何问题。
- 丢失了大约 4979(即 5000)左右的注释。
- 可能丢失了 707 个用户,很难准确进行评估(部分源自 Kibana 记录)
- 受影响的时间点:1 月 31 日 17:20 之后创建的数据
Offline 前的种种挣扎
首次事故:垃圾邮件用户的数据库负载的峰值
2017 年 1 月 31 日 18:00(UTC 时间)发现垃圾邮件发送者正在通过创建片段方式攻击数据库,目的是让数据库不稳定。工作人员随即开始寻找问题并准备应对方案。
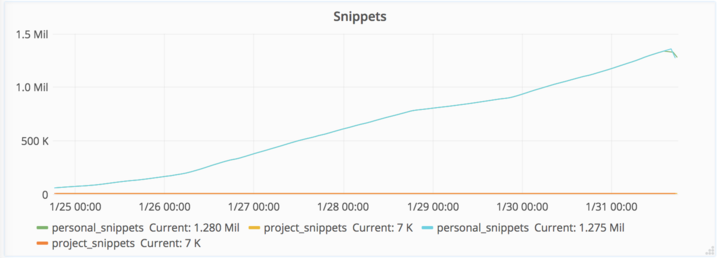
2017 年 1 月 31 日 18:00-21:00(UTC 时间),工作人员(team-member-1 )正在预发布环境安装 pgpool 和备份工具,为了拿到最新的生产环境数据他创建了一个 LVM 快照,这个快照会用于预发布环境,他希望可以重用这个快照用于引导其他的副本。这个操作在丢失数据前的 6 小时完成。
副本启用的过程中发现存在问题,并且需要消耗大量时间(根据估计仅仅是初始化 pg_basebackup 同步过程就需要耗时 20 个小时以上)。LVM 快照在工作人员可以修复问题之前又不能再其他副本上使用。整个修复过程都被这个问题耽搁下来。
2017 年 1 月 31 日 21:00(UTC 时间),开始出现锁定数据库写操作,并引起一些停机情况。进一步进行处理,措施包括锁定垃圾邮件的发送 IP、删除一个用户并启用仓库(造成 47000 个 IP 使用了相同的账户签名,进而导致数据库高负载)、删除垃圾邮件用户。
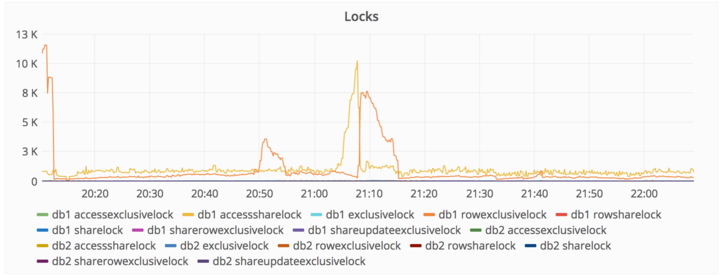
第二个事故:复制延迟触发警报
2017 年 1 月 31 日 22:00(UTC 时间),数据库备份进展出现落后情况,查明造成原因是备份数据库写入操作时出现异常,导致没有跟上备份节奏。
采取处理措施包括:尝试修复 db2 数据库,这时候备份落后了大概 4GB。然后 db2 集群开始拒绝执行备份作业,db2 集群拒绝连接到 db1,调整 max_wal_senders 为 db2,重启 PostgreSQL 数据库,随即 PostgreSQL 数据库提醒存在很多打开的连接,并拒绝启动服务。管理人员随即调整 max_connections 参数从 8000 调整至 2000,PostgreSQL 随即启动。注意,此时 db2 集群依然拒绝执行备份,处于未知原因的挂起状态。
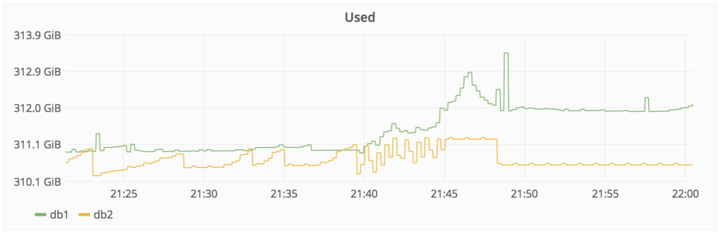
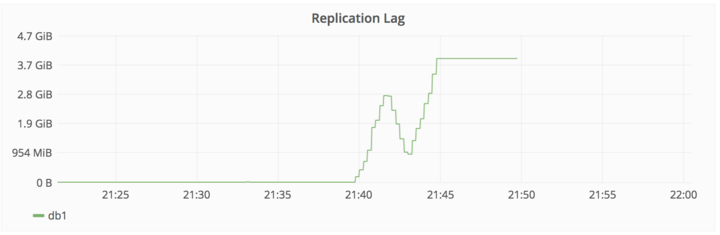
第三个事故:误删操作
2017 年 1 月 31 日 23:00(UTC 时间),工作人员(team-member-1 )感觉 pg_basebackup 拒绝执行的原因是 PostgreSQL 数据文件夹已经存在,所以决定去移除这个文件夹。执行 rm 操作之后,该工作人员意识到命令正在 db1.cluster.gitlab.com 执行,而不是 db2.cluster.gitlab.com。
2017 年 1 月 31 日 23:27(UTC 时间),工作人员(team-member-1 )终止了删除操作,300GB 的数据仅剩余 4.5GB。
下线,进入紧急状态
GitLab 决定下线 GitLab.com 并将事故通过推特向外公布,并且通过 YouTube 对外进行了修复过程的直播。

思考,罗列问题清单
GitLab 进一步对遇到的问题进行梳理和逐一解释,包括:
-
LVM 镜像默认每 24 小时执行一次。工作人员(team-member-1 )事故发生 6 小时之前手动执行了一次。
-
常规备份也是 24 小时执行一次,但是工作人员(team-member-1 )无法确定存放于何处。另外一名工作人员(team-member-2)认为这意味着失效,因为产生的文件只有几个字节。
一名工作人员(Team-member-3):PostgreSQL9.2 的二进制文件开始运行,导致 pg_dump 失败。由于数据库版本设置为 PostgreSQL9.6,最终导致SQL 备份不启用。
-
Azure 上的磁盘镜像只是针对 NFS 服务器,没有针对数据库服务器。
-
同步过程移除了 webhooks。除非我们可以从过去 24 小时的常规备份中提取这些内容,否则将丢失。
-
复制过程极度脆弱,很易出错,依赖于一系列 Shell 脚本,而这些脚本的注释很差。
-
S3 备份过程没有正常工作。
-
当备份失败时,没有可靠的警报 / 分页,在 dev host 上面现在也看到这一点
综上所述,5 个备份 / 复制技术都没有正常工作。无奈之下,我们最终启用 6 小时之前的备份。
pg_basebackup 需要等待主机启动复制过程完毕,这个过程需要 10 分钟。这个过程会导致我们认为复制过程卡住了。使用 strace 命令也看不出什么问题原因。
行动, 恢复过程
GitLab 的官方声明中说明了恢复过程的执行步骤:
- 2017 年 2 月 1 日 00:36(UTC 时间),备份 db1.staging.gitlab.com 数据。
- 2017 年 2 月 1 日 00:55(UTC 时间),挂载 db1.staging.gitlab.com 到 db1.cluster.gitlab.com。从 /var/opt/gitlab/postgresql/data/ 拷贝数据到生产环境 /var/opt/gitlab/postgresql/data/。
- 2017 年 2 月 1 日 01:05(UTC 时间),nfs-share01 服务器被征用作为临时备份服务器,放置于 /var/opt/gitlab/db-meltdown。
- 2017 年 2 月 1 日 01:18(UTC 时间),包括还存在的生产环境数据,包括 pg_xlog,命名为 20170131-db-meltodwn-backup.tar.gz。
下面这张图显示了删除和随后恢复事件的时间。
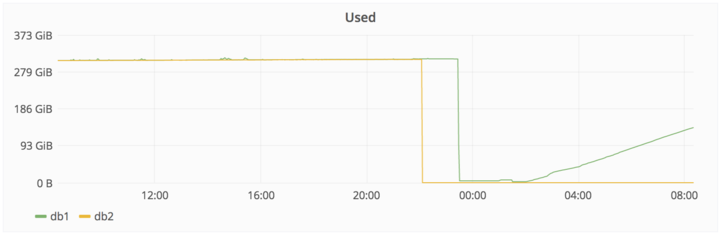
未完,GitLab 下一步打算
Todo list
- 为不同的环境改变 Linux 终端的格式或者颜色,例如红色代表生产环境,黄色代表测试环境。针对所有用户在 shell 提示符处显示机器的完整名字,例如 db1.staging.gitlab.com,而不是仅仅是“db1”。: https://gitlab.com/gitlab-com/infrastructure/issues/1094
- 针对 postgresql 的文件夹拒绝执行 rm -rf 这样的命令?可以设置命令执行保护或者针对数据库文件夹有对应的备份措施。
- 为备份增加提醒:检查 S3 仓库之类的体型。增加图形化界面,显示时间变化后的备份大小,当下降超过 10% 时发出警报。: https://gitlab.com/gitlab-com/infrastructure/issues/1095
- 找出为什么 PostgreSQL 在 max_connections 被设置为 8000 之后突然出现问题,这个设置在 2016 年 5 月 13 日就已经完成了。因为这个问题的突然出现导致了其他很多问题。 https://gitlab.com/gitlab-com/infrastructure/issues/1096
- 通过 WAL 归档增加备份阈值,这个方法对审计失败也许有用。 https://gitlab.com/gitlab-com/infrastructure/issues/1097
- 针对上线产品创建常见问题查找指南手册。
- 从一个数据中心移动数据到另一个数据中心可以通过 AxCopy 完成:微软声称这个工具比 rsync 要快很多。看上去这是 Windows 上面的问题,但是没有任何 Windows 专家参与。
五天内公开自省报告
GitLab 官方申明指出丢失生产环境数据是不可以接受的错误,5 天之内 GitLab 将对外发布错误发生及保护措施失效的原因,并将发布一系列措施避免悲剧再次发生。
网友们的关注
GitLab 致谢网友
GitLab 申明最后感谢了共计 42 位网友的外援,他们通过 Twitter 和其他渠道上给出的技术建议。
网友留言
“keturu ta”的评价
我们在日本工作,我们能够理解你们的痛苦和精神上的挫折。我们会一如既往地支持你们。
“Axel Dreyfus”的评价
现在已经很少看到这么开放的工作态度了。祝你们好运,永远支持你们。千万不要针对那个 UNIX SA,他已经瘦了 20 磅(开玩笑)。
“Neer”的评价
这样的事故对于任何人都有可能发生,我鼓励涉及团队不要有挫折感。这篇文章已经开始在社交媒体上流传开来了,让我感到这是一家非常公开和透明的公司。我之前没有听说过这个产品,但是从此以后我会开始使用它。
“Codepotato”的评价
感谢这样的全面解释。问题发生确实让人感觉很丢脸,但是同时也体现了你们对外的开放态度。当务之急我们需要找到办法提升恢复速度。
公开,直播修复过程
除了在网络上对事故进行文字说明,GitLab 还在 YouTube 上直播了其数据库修复过程。该过程视频时长 8 小时,共计有 32 万人次观看。 https://www.youtube.com/watch?v=nc0hPGerSd4
写在后面
事故处理过程中,GitLab 采用了开放的态度,事故发生后第一时间对外公布,并对处理过程进行现场直播,让全世界所有程序员都有机会一起参与恢复过程。GitLab 也针对网友提出的关于肇事工作人员如何处理问题进行了官方回应,表态不会因为这次事件解雇事故相关技术人员。
正是由于这样的开放性姿态,网友并没有对事故的发生而进行谩骂、嘲讽,而是一起通过网络对 GitLab 进行鼓励,对处理事故团队提供积极的技术建议。这样的处理方式可以作为 IT 公司生产环境经典解决案例被写入教科书。
参考资料
https://docs.google.com/document/d/1GCK53YDcBWQveod9kfzW-VCxIABGiryG7_z_6jHdVik/pub
https://about.gitlab.com/2017/02/01/gitlab-dot-com-database-incident/
https://www.theregister.co.uk/2017/02/01/gitlab_data_loss/
感谢木环对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




