Reddit 是著名的社交新闻网站,光是在 2012 年,它的独立访客就达到了 4000 万,页面浏览量达到了 370 亿次。几年过去了,网站用户有增无减,而随着用户的增多,网站的响应速度却一直在改进。这要得益于 Reddit 使用了大量的缓存。而随着网站规模不断增长,缓存数量也随着增加,那么 Reddit 是如何做到在增大缓存规模的同时又能保证它们的响应速度的?
我们知道,缓存的命中率越高,整体速度就越快,因为不需要重新从数据源加载数据。除此之外,如何管理缓存,比如缓存的过期时间,新旧缓存的交换,以及缓存的设计等等,它们对缓存的整体性能都有很大影响。来自 Reddit 的工程师 Daniel Ellis 在 Reddit 官方博客上分享了他们是如何使用 Memcached 集群来存储网站的缓存数据的。
Reddit 的缓存规模和基本策略
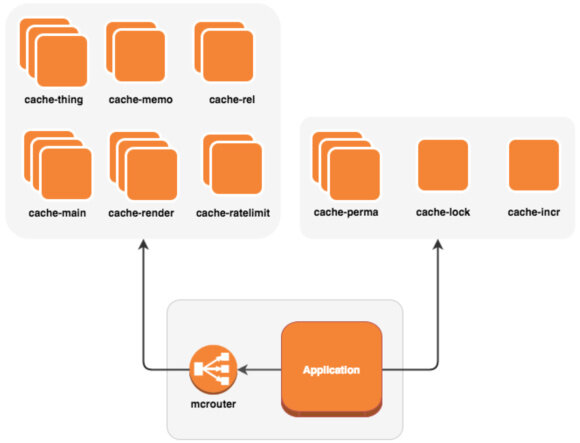
Reddit 目前使用了 54 个规格为 r3.2xlarge 的 AWS EC2 实例,每个实例拥有 61GB 内存,也就是说总的缓存大小差不多是 3.3TB,而且这些缓存并不包括应用程序的本地缓存。Reddit 的缓存包含了多种类型的数据,包括数据库对象、查询结果集、函数调用,还有一些看起来不太像缓存的东西,比如限定速率、分布式锁等等。如何管理这么大规模的缓存是一件很挑战性的事情,Reddit 采用的是“不要把所有鸡蛋放在同一个篮子里”的基本策略。也就是说,他们并不是把 3.3TB 的内存看成一个总的大缓存池,而是按照负载类型对缓存进行分类,每种类型占用一定数量的缓存空间。这样做有几个好处:
首先,按照负载类型对缓存进行分区,每种类型的缓存可以独立地伸缩。例如,对于数据库缓存来说,如果它的命中率降低,交换率变高,同时数据库变慢,那么就要考虑对数据库缓存进行扩展,而它的扩展不会影响到其它类型的缓存。
其次,按照负载类型对缓存进行分区,可以有针对性地对某种类型的缓存进行负载测试,从而预测该类型缓存的使用规模,并作出权衡。
第三个好处跟 Memcached 的内存分配模型有关系。Memcached 按照板块( slab )来分配内存,例如,1 至 96 字节的对象可能被放到板块 1,97 至 120 字节的对象被放到板块 2,并依此类推。这样做可以避免出现内存碎片。不过,Memcached 的这种分配机制不能动态变化,也就是说一旦设定好了这种模式就不能对其进行修改。如果一开始设定了用来存储 1KB 的对象,但后来想用它来存储 500KB 的对象,那么交换率就会变得很高。而按照负载类型来区分缓存,那么就可以根据实际数据类型的大小类设定板块大小。
新版本的 Memcached 可能支持 slab_automove 功能,不过这是后话了。
Reddit 的缓存类型
接下来我们来看看 Reddit 的几种缓存类型。
数据库对象缓存(thing-cache)
Instances 16 r3.2xlarge Memcached Version 1.4.30
Total RAM 976 GB Get Rate ~800k/s Set Rate ~13k/s Miss % 1.2-2% Typical Object Size 384-1184 bytes 数据库对象缓存是 Reddit 最大的缓存池。这些对象是无schema 的,开发人员可以很容易地对这些对象添加新属性,而无需对数据库schema 进行变更。这些对象包括用户评论、链接和账户等等。该类型缓存是Reddit 最繁忙也最有用的缓存,命中率高达99%。
主缓存(cache-main)
Instances 11 r3.2xlarge Memcached Version 1.4.30
Total RAM 671 GB
Get Rate ~82k/s
Set Rate ~10k/s Miss % ~75%
Typical Object Size <96 bytes 主缓存是 Reddit 第二大缓存池。这个缓存是一般性的缓存,里面存放的所有用来展示 /r/all 的结果集。不过从表格中可以看到,这个缓存的命中率并不高,大概只有 25% 左右。
渲染缓存(cache-render)
Instances 8 r3.2xlarge Memcached Version 1.4.30
Total RAM 488 GB
Get Rate ~224k/s
Set Rate ~103k/s Miss % ~45-55%
Typical Object Size 240-2320 bytes 第三大缓存用来存放渲染过的页面模板或页面片段。这个缓存相对安全,就算发生失效,也不会对系统造成太大影响。它的命中率只有大概 50% 左右,毕竟页面信息需要不断更新,所以渲染过的页面模板或片段也需要更新。再则,就算这个缓存失效,也不会给数据库负载带来多大影响,因为用来渲染页面的上下文内容已经在其它独立的缓存中加载过了。不过,因为缓存的 key 是基于上下文内容生成的,如果 key 发生变化,模板就需要重新缓存,这个需要消耗额外的 CPU,也会使页面响应时间变长。
持久缓存(cache-perma)
Instances 6 r3.2xlarge Memcached Version 1.4.17 Total RAM 366 GB
Get Rate 24k/s
Set Rate 4k/s Miss % <1% Typical Object Size 96-120 bytes 最后一个要细说的缓存,也是命中率最高的缓存——持久缓存,它的命中率超过了 99%。这个缓存用来存放数据库的查询结果,还有用户评论和链接。为什么管这个缓存叫持久缓存,因为他们使用了读 - 改 - 写(read-modify-write)的模式。例如,在用户新增一个评论时,他们会同时更新缓存和后端的数据库(Cassandra),而不是简单地让缓存失效,这样就避免了需要再次从数据库加载数据。
非缓存对象池
之前提过,除了上述的几种缓存,Reddit 还使用了速率限定和分布式锁。
对于一个并发量很大的网站来说,采取速率限定是很重要的一个措施,它可以避免用户无限制地消耗网站的资源。他们按照时间段把不同的 key 存放在不同的 bucket 里,每个 key 的 TTL 会随着每次调用逐步增加。通过检查这些 TTL 就可以确保它们不会超出限定的范围。因为一旦超过限定范围,该用户就无法再做任何操作。
另一方面,得益于 Memcached 的“add”原子操作命令,他们可以实现分布式锁。因为“add”命令每次会产生一个新的 key,只要这个 key 原先不存在,那么就相当于获得了一把锁。锁用完了就会被移除,下一次调用“add”会生成新的锁。这个操作保证同时只有一个进程可以获得这个锁。不过这也是他们的痛点之一。因为这里存在单点故障问题,一旦需要做迁移或维护,会让整个网站不可用。Reddit 团队计划在未来逐步减少甚至避免使用这种锁。
其它缓存池
除了上述几种缓存,Reddit 还有一些小型的缓存池,比如对象关系的缓存、函数调用结果的缓存等等。因为这些缓存都不大,这里不一一赘述。
mcrouter
上面介绍了 Reddit 的缓存分区策略,以及各种缓存类型的特点。接下来,我们来看看 Reddit 是如何使用 mcrouter 来满足各种复杂的使用场景的。
mcrouter 是由 Facebook 开源的 Memcached 连接池。为什么要用连接池?就像访问数据库要使用数据库连接池一样,使用连接池可以对连接进行重用和管理,避免了重复创建和销毁连接的开销。Reddit 有很多应用服务器,每个服务器上面运行着多个工作进程,如果这些进程独自向缓存集群发起连接,那么连接数量会暴增。无法重用连接是一种资源浪费,同时会给缓存集群带来更大压力。通过在应用服务器上使用 mcrouter,当前服务器上所有进程到缓存集群的连接可以形成一个连接池,并通过 mcrouter 这个唯一的出口连接到相应的缓存上。
除了作为连接池,mcrouter 还能处理很多复杂的场景。mcrouter 提供了多种路由类型,比如 PrefixSelectorRoute ,它通过匹配 key 的前缀来决定应该到哪个缓存上获取数据。这样就可以把特定功能的操作路由到特定的缓存上。
如果要往缓存集群里增加新的缓存实例,那么可以使用 WarmUpRoute 。新加入的缓存实例被称为“冷”缓存,而原先的实例叫作“热”缓存。WarmUpRoute 的工作原理是说,把所有写操作路由到“冷”缓存上,而把未命中的读操作路由到“热”缓存上,然后把在“热”缓存上命中的缓存结果异步地更新到“冷”缓存上,那么下次同样的读操作就也可以在“冷”缓存上命中。通过拷贝“热”缓存里的数据可以避免操作数据库,保证性能不会受到影响。
mcrouter 还提供了 FailoverRoute ,顾名思义,这个特性可以避免缓存的单点故障,因为它会为一种类型的缓存创建多个缓存池,如果其中一个失效了,请求会被路由到另一个备份的缓存实例上。
Reddit 还使用了影子缓存。不同于 WarmUpRoute,WarmUpRoute 只是把未命中的读操作拷贝到新实例上,而影子缓存会把读操作和写操作都拷贝一份到新的实例上,但前提是不改变数据源。通过影子缓存,他们可以对缓存的负载情况进行观察,因为新加的实例作为旧实例的“影子”而存在,在不影响旧实例的前提下可以看到整个缓存的工作情况。
mcrouter 还支持数据复制,这个功能不仅为缓存提供了高可用性,同时防止出现缓存热点。
自定义监控
缓存有时候会变成一个黑盒,所以对它们进行监控是很有必要的。GitHub 上有一个叫做 Diamond 的 Python 脚本可以收集 Memcached 的基本统计信息,比如对象的交换和命中率等等。不过这些信息还太简单,Reddit 团队需要知道在发生对象交换时,缓存内部还发生了其它什么状况。因为通过 Memcached 的“stats slabs”命令可以看到板块的度量指标,于是他们基于这些命令自己写了一个追踪板块度量指标的工具。他们还开发了一个简陋的可视化仪表盘:

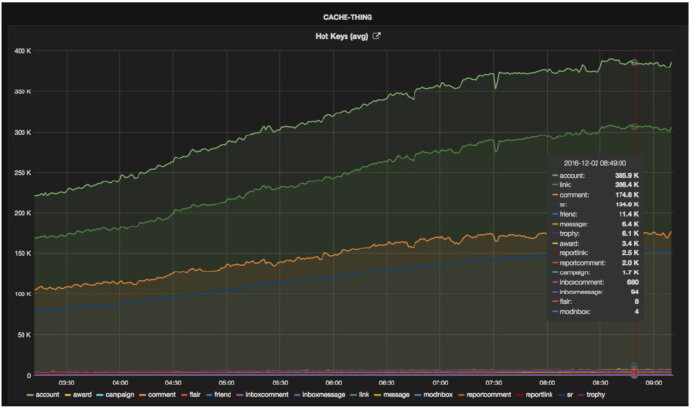
Reddit 团队还开发了另外一个工具,叫作 mcsauna 。这个工具被部署在每个缓存服务器上,它可以检测网络流量,并根据配置规则把不同的 key 保存在不同的 bucket 里,然后把结果输出到文件上。 FilesCollector 会收集这些文件,分析里面的 key,并以图形化的方式呈现出来。从这些图形上可以看出那些热点的 key。
展望
缓存为提升网站的响应速度做出了不可磨灭的贡献。而在如何使用缓存方面,Reddit 还有很长的路要走。接下来,他们可能要想着如何通过服务发现来对配置进行自动化,从而实现缓存的自动扩展,而不需要人工的介入。而随着 Memcached 版本的不断改进,他们也要针对现有系统进行调整,从而最大化缓存的性能。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




