毫无疑问,运维技术的发展已经进入了深水期。随着 Docker、OpenStack、Puppet 等技术的流行,以及 CI/CD、DevOps 等理念的落地生根,自动化运维的发展迎来了小高潮。整体来看,自动化运维平台帮助提升了运维的效率,并减少了因人工和流程操作而引起的运维故障。
记得在 2001 年的时候,Gartner Group 有一个调查显示在 IT 项目经常出现的问题中,源自技术或产品(包括硬件、软件、网络、电力失常及天灾等)的问题只占 20%,但流程失误方面却占 40%,人员疏失方面也占到了 40%。这些年来,企业通过自动化运维平台以及 DevOps 等协作理念逐步解决了 Gartner 提到的流程失误和人员疏忽相关的 80% 的问题,虽然目前没有具体的统计数据,但可以确认的是,这一问题得到了有效解决。
但另外一个值得注意的点是当前的 IT 项目基础设施环境与 5 年前已经没有办法同日而语,更不用说 10 年前。近几年,随着云计算、微服务等技术的流行,以及互联网业务的迅速发展,运维人员要关注的服务数量也呈现了指数级增长,自动化运维虽然提升了效率,解决了一部分问题,但也遇到了新的难题,比如面对繁多的报警信息,运维人员应该如何处理?故障发生时,又如何能够迅速定位问题?
当企业遇到这些新的问题却无从下手时,恰好历史进入了人工智能时代,那上面的这些问题可否通过『AI + Ops』的这种跨界创新的方式来解决呢?于是 Gartner 在 2016 年时便提出了 AIOps 的概念,并预测到 2020 年,AIOps 的采用率将会达到 50%。简单来说,AIOps 就是希望基于已有的运维数据(日志、监控信息、应用信息等)并通过机器学习的方式来进一步解决自动化运维没办法解决的问题。
就目前来看,国内的百度、搜狗、宜信、阿里巴巴都已经探索尝试了AIOps,并且取得了不错的收益。在2017 年InfoQ 举办的 CNUTCon 全球运维技术大会上,也有不少 AIOps 相关的议题,甚至会议主题也从去年的容器生态迭代到今年的智能时代的新运维,感兴趣的读者可以关注。
那对于 AIOps 这个新名词,它又会涉及到哪些新技术?从运维的发展角度看,为什么说 AIOps 是必然趋势?它与自动化运维之间会有什么样的关系?InfoQ 记者就这些问题采访了美丽联合集团运维经理赵成。
InfoQ:如何理解 AIOps?AIOps 会涉及哪些技术?这又是一个新名词吗?
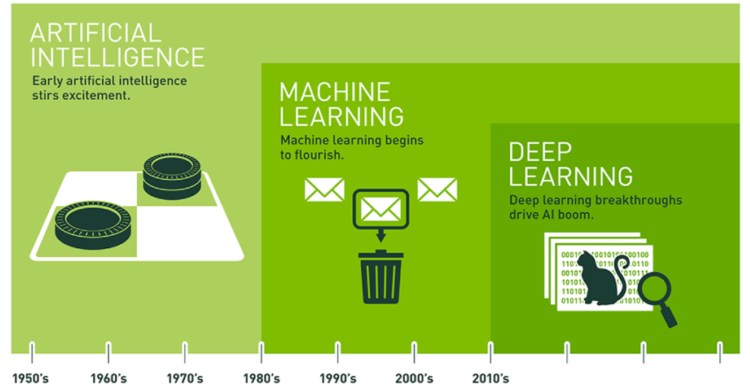
赵成:我觉得理解 AIOps 之前,还是先理解下 AI、机器学习、深度学习这样几个概念。如果用一张图,来表示,就是下图:
同时,这张图的来源文章,也建议看一下,讲的还是比较清晰的。
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/简单来说,AI,人工智能是一个广义概念,最早期提出来的时候,人们的愿景是希望 AI 能够完全具备人类智慧,这属于“强人工智能(General AI)”。但是除了在科幻电影和科幻小说外,在现实中还没有实现,可能不仅仅是要求对计算机技术要求极高,对生物医学技术也会有很高的要求,因为前提是我们得弄懂人类大脑运转的每一个细节吧。
但是过程中,研究人员发现我们虽然没法让机器完全具备人类一样的智慧,但是在非常具体和特定的领域,机器是可以做的比人类更好的,比如图形图像处理、语音识别等等,这些人工智能的应用,称之为“弱人工智能(Narrow AI)”,这些应用的实现手段,就得益于机器学习算法长足的进步,而深度学习又是机器学习领域很精深的一部分。
所以,我们现在提到的 AI,更多的是依赖机器学习(包含深度学习)算法的实现的 AI 场景,或者说机器学习算法只是实现 AI 的其中一种手段。
了解了上面的概念,再回到 AIOps 上来,拆分为 AI + Ops 会准确一些,也就是 Ops 与 AI 相结合可以做的事情。Gartner 的定义是 Algorithmic IT,而不是 Artificial Intelligence,我起初觉得也不是很合理,但是我认真理清楚整个关系之后,我觉得这样定义也没有问题。
最后,我觉得定义如何到没有必要纠结,因为不管 AIOps 里这个 AI 到底是 Algorithmic IT 还是 Artificial Intelligence,最终,我们根本上使用的,还是机器学习算法这个手段。
AIOps 涉及的技术,从 AI 的角度,主要还是机器学习算法,以及大数据相关的技术,因为涉及到大量数据的训练和计算,从 Ops 的角度,主要还是运维自动化相关的技术。另外 AIOps 一定是建立在高度完善的运维自动化基础之上的,只有 AI 没有 Ops,是谈不上 AIOps。
InfoQ:你认为 AIOps 是运维发展的必然趋势吗?从手工运维,到自动化运维,再到现在的 AIOps,谈谈你理解的运维发展趋势?
赵成:必然趋势。一个很明显的规律,凡是让能让我们的生活变得更美好、更简单、更方便的技术,一定会具有强大的生命力,也必然会成为发展趋势,而 AI 正是这样的技术之一,AIOps 又是其中的一个专业领域。
运维的发展变化,我的感受,是随着业务和技术发展变化的,根本上还是业务驱动和倒逼出来的。
比如 2008 年 -2010 年,我接触的是电信级软件的开发和维护,那个时期的软件有这么几个特点:
- 业务场景和形态上,相对固定,变化不大;
- 软件是分层架构 ,模块数量固定,架构上基本不会有太大的变化;
- 研发流程和规范非常严格,基本交付上线之后不会有太大的功能和性能问题 ,线上出问题会面临非常严格的处罚;
- 软件交付周期长,大的变更半年一次,小变更至少 3 个月,这期间研发会将发布脚本以及产品升级文档制定的非常详细,我们称之为 Step by Step,而且也是经过严格验证和测试的;
- 研发维优团队支持,一旦线上出现软件方面的问题,一线维护直接将问题转回研发进行定位处理,而且有严格的 SLA 约束;
这种情况下,变化不大、研发可以搞定绝大部分软件层面的事情,所以我们就会看到这个时期的运维更多的是网络、硬件、系统方面的维护职责,这个是由那个时期的业务特点,以及软件架构特点所决定的。
当然这并不代表那个时候业务的技术难度和复杂度不高,反而技术门槛是相当高的,协议之复杂,网元交互之多,架构图和交互逻辑画出来也是相当复杂,那个时候我们答辩和述职必做的事情就是看网讲网,要对所有的周边网元以及交互关系讲清楚。
之后,随着互联网业务的高速发展,业务场景上丰富多彩,复杂和多变,新业务和新场景也在不断涌现,为了快速验证产品和需求的方向是否有效,就要快速试错,对迭代开发和交付效率有了极高的要求,所以技术界逐渐催生出了服务化这样的软件架构,以及持续交付过程,同时随着业务体量快速膨胀,衍生出对稳定性有极高的要求,这时我们现在长听到的全链路跟踪、容量评估、限流降级、强弱依赖等稳定性的解决方案就涌现出来。
这时对于开发的诉求是能够将更多的精力放到需求实现上,而因服务化带来的大量的应用管理、持续交付、监控、稳定性、成本控制等非功能性体系的建设和保障就需要有专门的团队来做,这时对于运维的诉求也在悄然发生着变化,所以这也是为什么这个阶段会涌现出 DevOps、技术运营、PE、SRE 等等对运维重新定位的词汇。当然这个过程中,因为云计算发展,传统的网络、硬件和系统维护的职责在逐渐的被弱化,也在逼迫着运维的关注点从底层转向应用和业务层面。所以,我们看到就在近 2-3 年,自动化、发布系统、稳定性平台这些系统成为了运维团队重点关注和建设的部分。
这里就有一个趋势,就是 SpringCloud 和 Cloud Native,SpingCloud 让当前服务化的开发变得越来越方便和高效,而 Cloud Native 在打造应用的基础设施方面也已经取得了长足的进步,而且已经有了 CNCF 这样的组织在驱动响应的标准和体系建设。设想一下,后面从业界的角度,如果 Spring Cloud 成为微服务的开发标准,Cloud Native 成为应用的运维标准,是不是又会驱动着一波运维的转型和升级呢?
回到 AIOps 上来,当前这个阶段,现实情况,系统里面已经有大量软硬件模块、日志、监控告警指标也纷繁复杂,一方面是无法在问题萌芽状态就发现问题,无法提前做出预判,另一方面是发生了问题又无法快速确定根因,造成持续的资损。技术发展上,随着计算能力、数据量的积累、以及机器算法的进步,如何更加高效的开展 Ops 这个问题就摆在我们面前,AIOps 的模式应运而生。
所以,运维一步步发展到当前这个状态,根本上讲还是业务高速发展倒逼出来的,同时,从手动运维到运维自动化,再到 AIOps,这个过程根本上是在朝着如何更加高效运维的趋势在发展。
InfoQ:AIOps 的出现是为了解决哪些问题?这些问题运维自动化无法解决吗?
赵成:主要还是解决复杂环境下问题的快速发现甚至提前预判,以及出现问题后的如何在复杂的告警、报错和日志中快速进行根因分析。
运维自动化无法解决吗?我的理解,AI 和 Ops 要解决的还是两个层面的问题,可以类比到人,AI 相当于人的大脑,我们手脚和躯干是执行系统,大脑负责决策判断,手脚躯干负责完成大脑下发的动作指令。对应到运维上面,AI 要解决的是怎么快速发现问题和判断根因,而问题一旦找到,就需要靠我们高度完善的自动化体系去执行对应的运维操作,比如容量不够就扩容、流量过大就应该触发限流和降级等等。
AI 是能够让 Ops 执行的更加高效的强大助推力,下面是我之前整理出来的,我理解的 AIOps 的体系和建设思路。
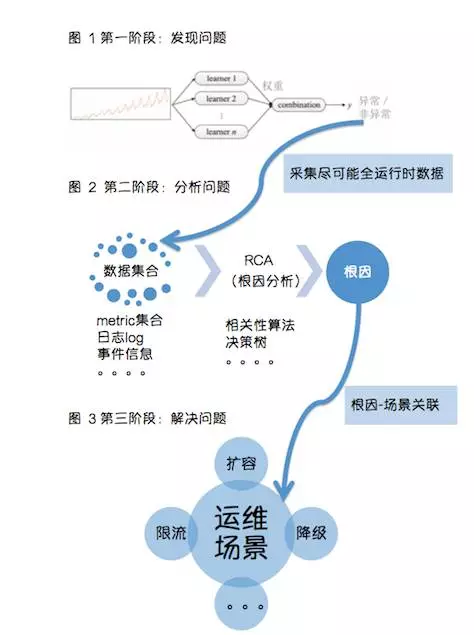
InfoQ:落地 AIOps 的前提条件是什么?什么样的团队适合落地 AIOps?
赵成:AIOps 的首要前提条件,一定是先要有高度完善的运维自动化,自动化都没做好前,先不要玩 AI,千万不要本末倒置。
从 AI 的角度,应该有三个方面的充要条件:机器学习算法、计算能力(类似于 GPU 的高性能设备)、海量数据。
先看算法,这个基础,在 AI 中我们使用到的各类算法,比如基于指数平滑的二次平滑、三次平滑算法,基于分解的傅里叶分解、小波分解算法等,基于深度学习的前馈神经网络、循环神经网络 RNN 算法等,这些算法早就已比较成熟了,并大量使用在其它的研究领域,比如我们熟悉的图形图像处理、语音识别,还有在医疗、电力以及通信行业的应用。所以在算法上,我们很早之前应该具备了这方面的理论基础。
但是 AI 为什么这几年突然火起来,或者在应用上有了长足的进步,很大原因就是计算能力提升了,海量数据积累起来了。比如随着硬件计算能力的提升,有了 GPU 这样的超高性能计算设备,同时还有云计算这样规模的基础设施支持;再就是,最近这些年随着互联网业务的高速发展,各行各业都积累了海量的现实的数据。
比如吴恩达教授非常著名的识别猫的实验,一方面吴教授有自己非常牛的深度学习算法,另外一方面,基于 16000 个处理器的计算能力搭建起了深度学习的平台,然后基于 Youtube 中千万级别的猫的视频图像进行算法的学习和训练,最终可以非常精确的从图像中识别出猫。
回到 AIOps 上面来,看这个三个条件:
- 算法还是那些算法,不过得要有相应专业能力的团队,如果是纯应用,我觉得运维团队倒是可以自学一下,但是不管怎么样,这个还是有一定门槛,需要大量的学习和能力提升。
- 数据就是要靠线上运行的真实数据和日志,所以必须要有大量的数据积累
- 计算能力上,目前看到我们基于大数据技术的数据处理能力已经足够,因为毕竟不是像图形图像这样的复杂计算场景。
从上面三个条件看,也就不难理解,AIOps 做的比较超前的为什么都是那些国内外的大厂,因为有技术实力、有足够的资源、有足够的数据,最关键的是足够复杂和变态的业务场景以及运维场景,在倒逼着 Ops 往这个方向上走。
至于什么样的团队适合落地,我暂时没想到什么标准,不过还是那个建议是,先尽快做好自动化,把基础打好,AI 的学习上做一些储备,当业务复杂度和体量到达一个量后,会自然倒逼着运维往这个方向发展,千万别自动化还没做完善,就跟风搞 AIOps。
InfoQ:AIOps 中的数据是怎么来的?数据是必要的吗?
赵成:AIOps 中的数据必须是线上产生的现实场景下的运行数据,不管是底层硬件和系统层面,还是应用和业务层面,以及运维的操作记录日志,要尽可能是全面的数据。这些数据一方面要做算法模型的训练,让算法能准确识别问题,一方面还要在问题分析时做根因分析使用。
数据是必要的,准确说是必需的。目前 AIOps 中,就异常发现来说,针对不同的应用场景,应该使用哪种算法模型,这个还是有一定挑战的,所以起初可能会同时使用多种算法同时运行,这时就需要大量真实的数据去验证算法运行的情况,同时做一些参数校正,也就是我们所说的训练的过程,最终我们根据跑出来的结果准确度选择合适的算法,或者设定相应的权重。所以,机器学习算法是否有效是离不开大量的真实数据的训练的。
InfoQ:可否谈谈你们的 AIOps 落地场景?
赵成:这块我们还在实践中,一块是异常检测,做一些关键监控 Metrics 的曲线监控,这块用到的基本是常见的指数平滑、3-Sigma 算法等。另一块是根因分析,在服务化的架构中,最头痛的还是出现了故障,无法快速的定位原因。大致思路是,根据全链路跟踪系统的每一次请求的依赖关系,做调用的关联度分析,当一个模块出现问题时,会同时导致依赖这个模块的所有模块都会告警,甚至还有业务层面的告警,这时就需要快速的根因分析,确定问题在哪儿。
嘉宾简介
赵成(谦益),美丽联合集团运维经理,负责美丽联合集团(原蘑菇街、美丽说)运维团队管理及运维体系建设工作。拥有近 10 年研发和运维经验,见证和参与了多个电信级和互联网产品从从无到有的建设,从微量到海量的成长过程,拥有非常丰富的电信级和互联网业务研发和运维经验。目前专注于运维创造价值,以及云计算和 AI 时代运维的转型和突破。 个人公众号 Forrest 随想【微信号:forrest_thinking】,欢迎关注。




