本文中文版已获原文作者 Matthew Mayo 授权。
在最近由 Kdnuggets 举办的自动化数据科学与机器学习博客大赛中,Auto-sklearn 开发团队勇夺了冠军。Matthew Mayo 采访了 Auto-sklearn 开发团队,了解了 Auto-sklearn 项目的基本情况,以及开发人员的背景和自动化数据科学的动态。
KDnuggets 最近举办了一场自动数据科学和机器学习博客比赛,获得了众多参赛者的作品提交,涌现了许多获奖作品以及一系列的荣誉称号。
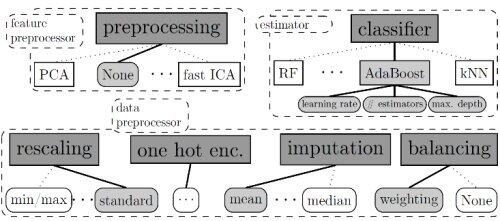
来自弗莱堡大学的Matthias Feurer、Aaron Klein 和Frank Hutten 撰写的题为“ Contest Winner: Winning the AutoML Challenge with Auto-sklearn ”的获奖作品,概要介绍了 Auto-sklearn ,一个可以自动确定有效的机器学习管道进行分类和回归数据集的开源 Python 工具。这个项目围绕成功的 scikit-learn 库而构建,并赢得了不久前的 AutoML 挑战。
鉴于这篇文章如此受欢迎,我们询问了作者是否有兴趣谈谈关于自己和项目的轶事,以及自动化数据科学的一些后续问题。以下是访谈记录。
Matthew Mayo:首先祝贺你们的 Auto-sklearn 项目在 KDnuggest 自动化数据科学和机器学习博客大赛获胜!你们能为读者介绍一下团队成员,并讲述你们每个人的背景情况吗?
Matthias Feurer:我是 Frank 集团的二年级博士生,致力于超参数优化和自动化机器学习。大多时间,我对预定义机器学习管道的优化感兴趣。在我硕士研究生期间,就开始为 Frank 工作,在我的大部分学习项目中,经常为超参数的调整而感到困扰。
Aaron Klein:我也是 Frank 集团的二年级博士生,研究方向是超参数优化和自动化机器学习。像 Matthias 一样,在加入 Frank 集团之前,我是弗赖堡大学的硕士生。
Frank Hutter:我是弗莱堡大学计算机科学系的助理教授,主要从事人工智能、机器学习和自动化算法设计。在来到弗赖堡大学之前,我在加拿大温哥华不列颠哥伦比亚大学工作了九年。
所有:除了我们三个人(撰写了 KDnuggets 博客大赛的博文),我们的团队还包括来自弗赖堡大学的博士生和博士后:Katharina Eggensperger、Jost Tobias Springenberg、Hector Mendoza、Manuel Blum、Stefan Falkner 和 Marius Lindauer。
这篇文章非常翔实,很好地描述了 Auto-sklearn。您希望我们的读者在了解 Auto-sklearn 或自发布以来的任何进展有什么需要额外注意的吗?对于它的未来发展计划,有什么可以分享给读者吗?
我们的短期目标是回归,以便我们可以做更多的工作。而我们的长期目标,是希望 Auto-sklearn 能够成为 scikit-learn 灵活的扩展,能够帮助用户优化机器学习管道。我们还要沿着 Auto-Net 的方向进行更多的工作,通过考虑跨数据集、跨数据子集和基于时间的任意时间算法(anytime algorithms)来显著地加速优化过程。
那么,你认为机器学习和数据科学在多大程度上可以自动化?所谓的全自动化系统需要何种程度的人机交互?
尽管有一些方法可以用来调试机器学习管道的超参数,但是目前为止,很少有工作能发现新管道。Auto-sklearn 以固定的顺序使用一系列的预定义的预处理器和分类器。加入一个方法对于找到新管道很有效,那么这个方法将会很有用处。当然,人们可以继续这种思路,并尝试自动寻找新的算法。最近,已经有几篇论文这样做了。比如 Learning to learn by gradient descent by gradient descent。当机器学习模型进行训练过于费时费钱时,人们可以调整超参数,比自动化方法做得更好,例如最先进的用于大型数据集的深层神经网络。我们正在努力将专家的启发式方法转换为完全形式化的算法,比如我们的 Fabolas 方法先从较小数据子集上开始优化神经网络的超参数,从而加快了解全部数据集的最佳超参数。
考虑到先前的问题,短期之内数据科学家是否会失业?或者,如果让脑洞大开,目前被媒体大肆炒作的数据科学家,将来会不会被自动化压制?如果是这样的话,会有什么样的程度?
当然不是,我们发展自动化机器学习方法是为了向数据科学家提供帮助,而不是代替他们。这些方法使数据科学家摆脱了讨厌复杂的任务(比如说超参数优化),机器可以很好地解决这些任务。然而数据分析与结论获取仍然需要人类专家来完成,尤其是通晓应用领域的数据科学家仍然非常重要。然而我们相信,自动化将会提高数据科学家的工作效率,因此,这有可能确实会影响到数据科学家需要做的工作量。
数据科学家能够做什么来避免被淘汰的命运?当然,提出这个问题并非捣乱,而是为了增加本次采访的价值。
分析和解释统计分析的结果,总得由数据科学家来完成,因此,对于开始数据科学工作的年轻毕业生来说,掌握这个技能可能比其他技能更为永不过时(例如,手动调整超参数以充分利用神经网络)。
您过去一直积极参与机器学习比赛,您有什么有趣的技巧、诀窍或见解与读者分享吗?
自动化和仔细的重采样策略。由于自动化允许进行大量实验,为防出现过拟合(overfitting),因此需要像仔细的交叉验证那样的重采样策略。进一步开放思想也是非常重要的,只需让数据来说明哪种方法对数据集效果最好。
最后一个问题,你认为在五年内,机器学习技术将会到达什么样的水平?
未来会怎么样,这很难预测,这点在机器学习领域尤为如此。要知道在五年前,并没有人预见到深度学习的兴起。但是我们相信,机器学习将会越来越普遍,在大家都使用的商业工具中将会见到机器学习的身影。
非常感谢您百忙之中抽出这一点宝贵的时间接受我的采访。
相关资料:
- Contest Winner: Winning the AutoML Challenge with Auto-sklearn
- Contest 2nd Place: Automated Data Science and Machine Learning in Digital Advertising
- Contest 2nd Place: Automating Data Science
原文链接:
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




