12 月 18 日,深圳 - 腾讯大数据宣布推出面向机器学习的第三代高性能计算平台——Angel,并预计于 2017 年一季度开放其源代码,鼓励业界工程师、学者和技术人员大规模学习使用,激发机器学习领域的更多创新应用与良好生态发展。
InfoQ 采访了腾讯大数据负责人蒋杰,本文根据采访稿件以及姚星和蒋杰在腾讯大数据技术峰会暨 KDD China 技术峰会上的演讲内容整理而来。
研发背景
腾讯公司是一家消息平台 + 数字内容的公司,本质上也是一家大数据公司,每天产生数千亿的收发消息,超过 10 亿的分享图片,高峰期间百亿的收发红包。每天产生的看新闻、听音乐、看视频的流量峰值高达数十 T。这么大的数据量,处理和使用上,首先业务上存在三大痛点:
第一,需要具备 T/P 级的数据处理能力,几十亿、百亿级的数据量,基本上 30 分钟就要能算出来。
第二,成本需低,可以使用很普通的 PC Server,就能达到以前小型机一样的效果;
第三,容灾方面,原来只要有机器宕机,业务的数据肯定就有影响,各种报表、数据查询,都会受到影响。
其次是需要融合所有产品平台的数据的能力。“以前的各产品的数据都是分散在各自的 DB 里面的,是一个个数据孤岛,现在,需要以用户为中心,建成了十亿用户量级、每个用户万维特征的用户画像体系。以前的用户画像,只有十几个维度主要就是用户的一些基础属性,比如年龄、性别、地域等,构建一次要耗费很多天,数据都是按月更新”。
另外就是需要解决速度和效率方面的问题,以前的数据平台“数据是离线的,任务计算是离线的,实时性差”。
“所以,我们必须要建设一个能支持超大规模数据集的一套系统,能满足 billion 级别的维度的数据训练,而且,这个系统必须能满足我们现网应用需求的一个工业级的系统。它能解决 big data,以及 big model 的需求,它既能做数据并行,也能做模型并行。”
经过 7 年的不断发展,历经了三代大数据平台:第一代 TDW(腾讯分布式数据仓库), 到基于 Spark 融合 Storm 的第二代实时计算架构,到现在形成了第三代的平台,核心为 Angel 的高性能计算平台。
Angel 项目在 2014 年开始准备,15 年初正式启动,刚启动只有 4 个人,后来逐步壮大。项目跟北京大学和香港科技大学合作,一共有 6 个博士生加入到腾讯大数据开发团队。目前在系统、算法、配套生态等方面开发的人员,测试和运维,以及产品策划及运维,团队超过 30 人。
Angel 平台是使用 Java 和 Scala 混合开发的机器学习框架,用户可以像用 Spark, MapReduce 一样,用它来完成机器学习的模型训练。
Angel 采用参数服务器架构,支持十亿级别维度的模型训练。采用了多种业界最新技术和腾讯自主研发技术,如 SSP(Stale synchronous Parallel)、异步分布式 SGD、多线程参数共享模式 HogWild、网络带宽流量调度算法、计算和网络请求流水化、参数更新索引和训练数据预处理方案等。
这些技术使 Angel 性能大幅提高,达到常见开源系统 Spark 的数倍到数十倍,能在千万到十亿级的特征维度条件下运行。
自今年初在腾讯内部上线以来,Angel 已应用于腾讯视频、腾讯社交广告及用户画像挖掘等精准推荐业务。未来还将不断拓展应用场景,目标是支持腾讯等企业级大规模机器学习任务。
腾讯为何要选择自研?
首先需要一个满足十亿级维度的工业级的机器学习平台,蒋杰表示当时有两种思路: 一个是基于第二代平台的基础上做演进,解决大规模参数交换的问题。另外一个,就是新建设一个高性能的计算框架。
当时有研究业内比较流行的几个产品:GraphLab,主要做图模型,容错差;Google 的 Distbelief,还没开源;还有 CMU Eric Xing 的 Petuum,当时很火,不过它更多是一个实验室的产品,易用性和稳定性达不到要求。
“其实在第二代,我们已经尝试自研,我们消息中间件,不论是高性能的,还是高可靠的版本,都是我们自研的。他们经历了腾讯亿万流量的考验,这也给了我们在自研方面很大的信心”。
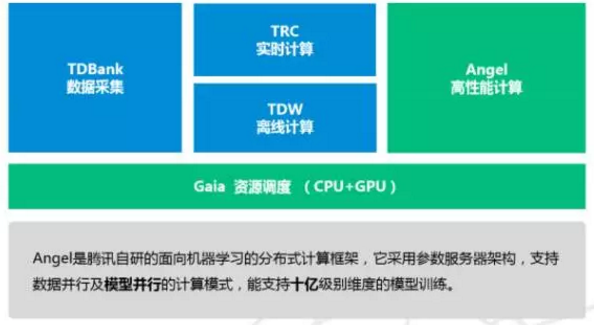

第三代高性能计算平台
“同时,我们第三代的平台,还需要支持 GPU 深度学习,支持文本、语音、图像等非结构化的数据”。
Angel 的整体架构
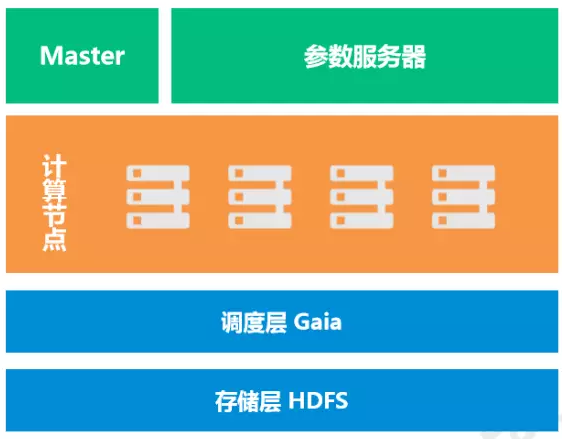
Angel 架构图
Angel 是基于参数服务器的一个架构,整体架构上参考了谷歌的 DistBelief。Angel 在运算中支持 BSP、SSP、ASP 三种计算模型,其中 SSP 是由卡耐基梅隆大学 EricXing 在 Petuum 项目中验证的计算模型,能在机器学习的这种特定运算场景下提升缩短收敛时间。Angel 支持数据并行及模型并行。
在网络上有原创的尝试,使用了港科大杨强教授的团队做的诸葛弩来做网络调度,
ParameterServer 优先服务较慢的 Worker,当模型较大时,能明显降低等待时间,任务总体耗时下降 5%~15%。
另外,Angel 整体是跑在 Gaia(Yarn)平台上面的。
主要的模块有 3 个:
Master:主控节点,负责资源申请和分配,以及任务的管理。
ParameterServer:包含多个节点,可对参数进行横向扩展,解决参数汇总更新的单点瓶颈, 支持 BSP,SSP,ASP 等多种计算模型,随着一个任务的启动而生成,任务结束而销毁,负责在该任务训练过程中的参数的更新和存储。
WorkerGroup:一个 WG 包含多个 Worker,WG 内部实现模型并行,WG 之间实现数据并行, 独立进程运行于 Yarn 的 Container 中。
Angel 已经支持了 20 多种不同算法,包括 SGD、ADMM 优化算法等,我们也开放比较简易的编程接口,用户也可以比较方便的编写自定义的算法,实现高效的 ps 模型。并提供了高效的向量及矩阵运算库(稀疏 / 稠密),方便了用户自由选择数据、参数的表达形式。在优化算法方面,Angel 已实现了 SGD、ADMM,并支持 Latent DirichletAllocation (LDA)、MatrixFactorization (MF)、LogisticRegression (LR) 、Support Vector Machine(SVM) 等。
Angel 的优势包括几点:
- 能高效支持超大规模(十亿)维度的数据训练;
- 同样数据量下,比 Spark、Petuum 等其他的计算平台性能更好;
- 有丰富的算法库及计算函数库,友好的编程接口,让用户像使用 MR、Spark 一样编程;
- 丰富的配套生态,既有一体化的运营及开发门户,又能支持深度学习、图计算等等其他类型的机器学习框架,让用户在一个平台能开发多种类型的应用。
Angel 做过哪些优化?
Angel 是基于参数服务器的一个架构,与其他平台相比,在性能上很多优化。首先,我们能支持 BSP、SSP、ASP 三种不同计算和参数更新模式,其次,我们支持模型并行,参数模型可以比较灵活进行切分。第三,我们有个服务补偿的机制,参数服务器优先服务较慢的节点,根据我们的测试结果,当模型较大时,能明显降低等待时间,任务总体耗时下降 5%~15%。最后,我们在参数更新的性能方面,做了很多优化,比如对稀疏矩阵的 0 参数以及已收敛参数进行过滤,我们根据参数的不同数值类型进行不同算法的压缩,最大限度减少网络负载,我们还优化了参与获取与计算的顺序,边获取参数变计算,这样就能节省 20-40% 的计算时间。
我们除了在性能方面进行深入的优化,在系统易用性上我们也做了很多改进。第一,我们提供很丰富的机器学习算法库,以及数学运算算法库;第二,我们提供很友好的高度抽象的编程接口,能跟 Spark、MR 对接,开发人员能像用 MR、Spark 一样编程;第三,我们提供了一体化的拖拽式的开发及运营门户,用户不需要编程或只需要很少的开发量就能完成算法训练;第四,我们内置数据切分、数据计算和模型划分的自动方案及参数自适应配置等功能,并屏蔽底层系统细节,用户可以很方便进行数据预处理;最后一点,Angel 还能支持多种高纬度机器学习的场景,比如支持 Spark 的 MLLib,支持 Graph 图计算、还支持深度学习如 Torch 和 TensorFlow 等业界主流的机器学习框架,提供计算加速。
Angel 的性能项目测试结果
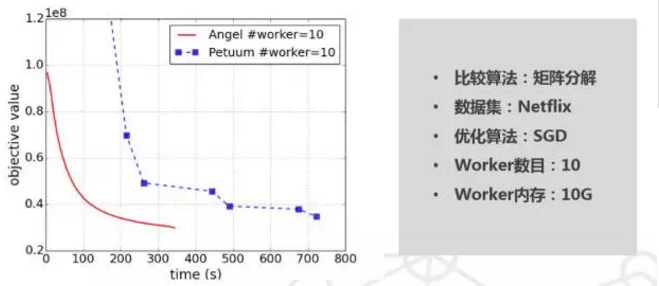
同等数据量下的性能测试。Angel 跟其他平台相比,比如 Petuum,和 spark 等,在同等量级下的测试结果,Angel 的性能要优于其他平台。比如用 Netflix 的数据跑的 SGD 算法,结果可以看上图中的对比。
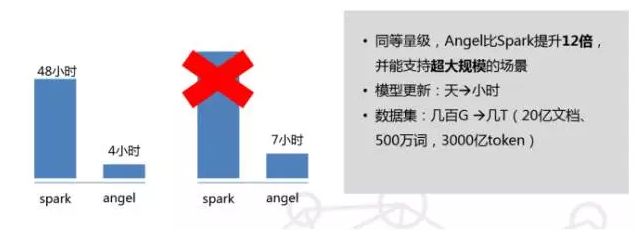
超大规模数据的训练测试。目前 Angel 支持了很多腾讯内部的现网业务。举两个例子,比如,在构建用户画像方面,以前都是基于 Hadoop 和 Spark 来做,跑一次模型要 1 天甚至几天,话题只有 1k;而在 Angel 上,20 多亿文档、几百万个词,3000 亿的 token,1 个小时就跑完了。以前 Spark 能跑的,现在 Angel 快几十倍;以前 Spark 跑不了的,Angel 也能轻松跑出来。

大规模数据集的训练能力。例如腾讯视频的点击预测,同等数据量下,Angel 的性能是 Spark 的 44 倍以上。用了 Angel 以后,维度从千万扩展到亿,训练时间从天缩短到半小时,而准确度也有很大的提升。
为什么开源?
Angel 不仅仅是一个只做并行计算的平台,它更是一个生态,我们围绕 Angel,建立了一个小生态圈,它支持 Spark 之上的 MLLib,支持上亿的维度的训练;我们也支持更复杂的图计算模型;同时支持 Caffe、TensorFlow、Torch 等深度学习框架,实现这些框架的多机多卡的应用场景。

Angel 的生态圈
腾讯大数据平台来自开源的社区,受益于开源的社区中,所以我们自然而然地希望回馈社区。开源,让开放者和开发者都能受益,创造一个共建共赢的生态圈。在这里,开发者能节约学习和操作的时间,提升开发效率,去花时间想更好的创意,而开放者能受益于社区的力量,更快完善项目,构建一个更好的生态圈。
我们目前希望能丰富 Angel 配套生态圈,进一步降低用户使用门槛,促进更多开发人员,包括学校与企业,参与共建 Angel 开源社区。而通过推动 Angel 的发展,最终能让更多用户能快速、轻松地建立有大规模计算能力的平台。
我们一直都向社区做贡献,开放了很多源代码,培养了几个项目的 committer,这种开放的脚步不会停止。
小结
腾讯公司通过 18 年的发展今天已经成为了世界级的互联网公司。“在技术上,我们过去更加关注的是工程技术,也就是海量性能处理能力、海量数据存储能力、工程架构分布容灾能力。未来腾讯必将发展成为一家引领科技的互联网公司,我们将在大数据、核心算法等技术领域上进行积极的投入和布局,和合作伙伴共同推动互联网产业的发展。”
受访嘉宾:蒋杰 国内知名大数据专家,CCF 大数据专家委员会委员,ACM 数据挖掘中国分会委员,拥有超过 12 年以上从业经验,在数据库、分布式架构、高性能计算、机器学习等方面积累了丰富经验。目前是腾讯首席数据专家、数据平台部总经理,全面负责腾讯数据业务。




