英特尔认为到 2025 年将有 500 亿台设备互联上网,那时人们将更加受惠于 AI 带来的价值:自动驾驶、疾病诊断、靶向医疗、智能工厂将会为人类社会带来更多的福祉。人工智能相关的研究虽然愈发成熟,但是目前距离大规模部署落地仍然有一定距离。AI 对技术平台首当其冲的要求就是提高数据处理能力,英特尔希望建立起一个好的数据库体系,并且从软件和硬件层面着手提高协同效应。
2016 年 11 月 30 日,英特尔于北京举办了人工智能论坛。以下为论坛内容简要总结和 InfoQ 对英特尔软件与服务事业部两位副总裁的采访。
AI 仍在婴儿期
计算机技术一直在不断发展:就后端服务而言,从最早的大型机,变成基于标准的服务器,到现在的云计算模式。
英特尔公司全球副总裁兼中国区总裁杨旭认为人工智能之所以会受到越来越多的关注,是因为现在数据洪流的庞大。在中国,现在人均每天产生 1.5GB 数据,这是人联网的效果。那么物联网会每天带来多少数据量呢?一个医院信息和设备等数据可以达到 3000GB,一辆无人驾驶的智能车可以产生 4000GB,一架飞机是 4 万 GB,而一座工厂则产生 100 万 GB 数据。
如果要更好地实现人工智能,一定需要有对大型数据的强大计算能力。英特尔预测认为,到 2020 年,AI 的计算量将会增长 12 倍。
人工智能技术的关键性就在于把收集的数据怎么更好的挖掘和分析,然后利用起来,实现增值,从而带来增值的业务。
AI 技术的简要总结
机器学习分为三种类型:
-
监督学习:根据标记数据指导预期的行为,即根据旧数据理解新数据
-
非监督学习:在没有标记数据的情况下进行推断,即发现位置模式或隐藏模式
-
强化学习:在特定环境下,创建具备学习能力的自动化代理。
上面三类机器学习按照时间顺序先后出现,机器学习的方法大致可分为两类:
-
经典机器学习:在原数据基础上通过既定的数学运算,提炼特征值和特征函数,进行各种算法的分类器,最后得出结果。
-
深度学习:特征的提取是通过多个抽象层提取,通过数据发现获得的特征并不是预先知道的;这种方式使用数据提升性能,并且数据越多越具有代表性。
英特尔对 AI 的多样性总结如下:

英特尔的软硬协同与致力 AI 生态
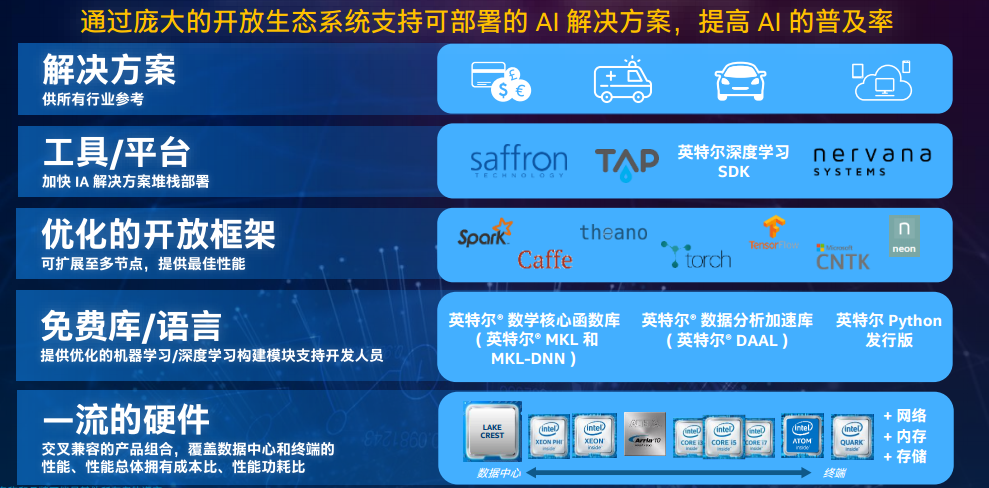
作为一个家喻户晓的硬件公司,英特尔敏锐地思考到了应该怎样从硬件角度对 AI 的应用进行针对性的加速。今年八月,英特尔收购了人工智能软件公司 Nervana Systems,后者提供的 SaaS 化的 Nervana Cloud 可供企业自行开发搭建深度学习应用。据资料显示,在收购之前,Nervana 拥有为深度学习而全面优化的软件和硬件堆栈;Nervana Cloud 虽然基于 Arm Neon 并且跑在 GPU 上,但是 Nervana 正在研制的为深度学习特制的 ASIC 要比 GPU 性能提高 10 倍。英特尔认为 Nervana 的知识产权以及他们在加速深度学习算法方面的领先技术将极大拓展其在人工智能领域的布局。
如今,英特尔的硬件平台涵盖至强处理器、至强融核处理器、Nervana 平台和 FPGA、Onmi-Path 网络、3D Point 存储等技术。Nervana 所带来的 Engine 芯片和专业技术将有助于改进英特尔的人工智能产品组合,提升英特尔至强和英特尔至强融核处理器的深度学习性能并降低它们的总体拥有成本,其推出了 Nervana 产品组合如下图,其中采用了张量运算、Flexpoint 技术的 Lake Crest 正在研制中预计 2017 年问世。

不过英特尔对 AI 的布局并不仅仅局限于硬件层面,英特尔自有深度学习数学核心函数库 MKL、数据分析加速库 DAAL 和 Python 发行版。对于新进的 Nervana 软件专业知识,英特尔称将不断整合以进一步优化其数学核心函数库,并帮助将其集成到行业标准框架中。
同时,英特尔称还致力于构建支持 AI 的开放生态系统,为开源软件框架如 Spark、Caffe、Theano 以及 Neon 等提供多节点架构。
在大会演讲结束后,英特尔的软件与服务事业部副总裁兼产品开发部门总经理 William Savage 和软件与服务事业部副总裁兼机器学习与翻译部门总经理李炜接受了 InfoQ 的采访。
问答对话
InfoQ:现在英特尔在发展 FPGA 和 ASIC,也提到 FPGA 可以提升和定制化用户针对 AI 应用的需求,请问能否对两种技术对 AI 中的应用进行下评价?
William: FPGA 在深度学习领域中更多地是为评分(Inference,也叫 Scoring)而预置的,FPGA 可以跟至强芯片整合在一起去满足深度学习 Inference 阶段的需求,这满足了深度学习一些非常特殊的需求。而 Nervana 的 ASIC 是针对训练(Training)阶段最为优越的解决方案。
李炜:在深度学习里面有两步:一步是训练模型(Training),一步是拿模型之后做预测及中文评分(Scoring/Inference)等。
InfoQ:软件层面的算法也可以在硬件上实现,但是硬件的开发有风险,费时且昂贵。对于算法实现,你们如何判断是选择硬件实现还是软件实现呢?
William:这是一个非常好的问题,这也是为什么大家如此关注 Nervana ASIC 以及 FPGA,因为这两款设计的周期比我们需要设计一个新的 CPU 快得多,也就是说我们可以更快的适应算法的变化。我们所采取的策略是先做 ASIC,等算法开始逐渐稳定下来之后,然后才会把它放到新的 CPU。
李炜:其实可以认为算法有两块,会改变的和非常固定和可靠的。对于前者,我们需要去适应。而对于后者,深度学习中常年积累下来的,如 Basic operation 基本操作、 Matrix computation 任务计算、Convolution 卷积计算这种一直都没怎么变。
InfoQ:能否简单说说英特尔怎么算法中变化的部分,你们如何跟上变革的步伐呢?
李炜:我认为算法界在快速地进化,但并不会变成是完全全新的样子。我认为恰当的说法是,深度学习在不断地进步。
William:是的。因为它具有快速变化的一方面,同时也有相对来说比较稳定的一方面,所以并不是说一夜之间所有都发生了变化。另外,其实在我们这块,变化最多的是多少浮点是最准确的,是 16B 还是 8B,现在数学在这方面还在演进当中,还没有确定下来。
(记者注:大会上,英特尔中国研究院院长宋先生也同样提到这一点:大模型训练后很稀疏,很多参数是 0,在模型里面做裁剪时,0 的地方就不需要参与运算。原来用 16 位计算,现在 Intel 在尝试用 8 位、4 位、2 位甚至到 1 位,是否也能够完成对应的模型运算,并且同时保证性能、准确度,这也是目前 Intel 在研究的一个重点。同时还在研究如何扩展,采用更大的 Batch Size 还有 High-order 的方法去做深度学习的训练。)
InfoQ:英特尔有两个函数库,MKL 和 DAAL,他们是何时发布的?
William:这是一个很好的问题。首先 MKL 是二十年前就已经推出来了,主要针对的是高性能计算。对于 DAAL 的话,是四年之前才建立起来的,一方面在 MKL 低功耗加速能力的基础之上,同时又增加了一些针对机器学习的性能。另外还有一个,MKL-DNN 其实是会使用 MKL 的性能,应该是在一年之内推出的。
李炜:DAAL 是机器学习,不是深度学习,而 MKL-DNN 是深度学习;两者有不同的目的作用。
InfoQ:人工智能会成为英特尔的头等战略吗?
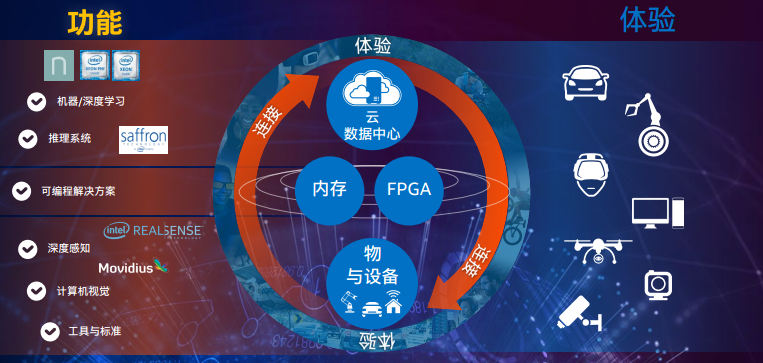
William: “AI 已经是顶级的或者是最重要的战略”这句话是不准确的,也无法完整的描述我们的战略。其实大会演讲上我们有一张幻灯片,在幻灯片里面讲到了我们的数据中心和设计之间的关系所形成的良性的增长循环,这才是我们顶级的战略。
InfoQ:英特尔跟众多高等院校和开源社区有合作关系,如 TensorFlow 开源项目,你们是如何同开源社区合作的,又是如何做出贡献的?
李炜:这个问题我想分成从两个层面来回答:一个是怎样决定,还有一个是决定之后真正怎么做。具体做哪个开源框架主要取决于需求,比如我们自己需要做 Spark 就做 Spark,商业需求要做 Caffe 或者做 TensorFlow 我们就去做这个事情。
那一旦我们开始做优化之后,再怎么推动到开源里,就有不同的做法了。这里举两个例子,TensorFlow 是跟谷歌一起合作,把优化过的部分给谷歌,让谷歌发布出去。另外一个是 Caffe,Caffe 是与伯克利合作,这个是涉及到与高校合作。但目前因为伯克利只有几个研究生,人力不够,所以目前还在积极推进中。具体而言,在 Caffe 里面英特尔还有一个分支,也是开源的。现在正在跟伯克利在交谈怎么把我们这个也并进去,共同来推进开源的发展。
William:对不同的框架来说我们的方式和方法是不太一样的。




