几乎每个人都在以这样或那样的方式抱怨数据库的性能问题,数据库管理员和程序员时常要面临服务器资源不够用或数据库查询一直执行不完的情况。这些情况对我们来说太正常不过了。解决办法多种多样,最典型的一种就是把枪口指向查询语句,并谴责程序员没能写出高效的查询。他们本可以使用恰当的索引和物化视图,或者写出更好的查询。你需要增加更多的节点来缓解这些压力。在某些情况下,你的服务器因执行太多低效的查询而过载,你会考虑为不同的查询设置不同的优先级,这样那些紧急的查询(比如 CEO 要求的查询)可以得到优先处理。如果你使用的数据库不支持优先级队列,那么数据库管理员有可能会取消掉一些查询,以便腾出资源处理紧急的查询。
不管你所经历的是哪一种情况,你都深谙其苦,你要等待低效的查询执行完毕,或者购买更多的云服务实例或更快跟大的服务器。大多数人对传统的数据库调优和查询优化技术都很熟悉,这些技术各有优缺点,不过我们不打算在这里讨论它们。在这篇文章里,我们将会讨论最近出现的技术,它们不为众人所知,但在多数情况下它们会为我们带来更好的性能,帮助我们把握住机会。
我们将着重探讨三种场景。
场景一(探索性分析)。作为一个分析师,你通过捣鼓数据来挖掘其中的价值,或者对业务、客户或服务进行验证测试。在这些情况下,你一般不知道该关注哪些方面的问题。你运行了一个查询,查看结果,然后决定要不要再运行另外一个查询。换句话说,你周旋于一系列的探测性查询之中,直到找到你想要的结果。这些查询中只有一小部分是有用的,它们可能被用于生成公司报表、填充表格或为客户生成图表。不过每次在提交查询之后,你可能需要等上几分钟才能拿到结果,等待时间的长短取决于数据量的大小以及并发运行的查询个数。在等待结果期间,你无法决定下一步该做怎样的查询,因为下一步的查询依赖上一个查询的结果!
解决方案:在等待结果期间,你可以立即看到“近似完美”的结果。这里的“近似完美”指的是什么?请比较下面的两个图表。
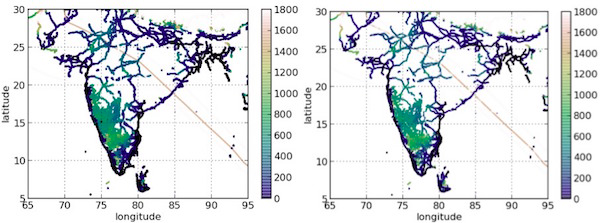
这两个图表分别是同一个 BI 工具两次从后端数据库加载查询数据的结果。右边的查询用了 71 分钟从 1B 的数据里得出结果,而左边的查询只用了 3 秒钟从 1M 的数据里得出结果!确实,跟右边的结果相比,左边的结果不是很精确。不过这样做是否值得呢?你可以为了得到完整的结果等上 71 分钟,或者如果不想等,那么可以立即得到一个几乎相同的结果。看着左边的那副图,很难想象会有人认为 71 分钟的等待是值得的!
当然,这并非什么新点子!实际上,所有的浏览器都在使用这种模式。当你使用浏览器加载一张高分辨率图片时,可以看到浏览器先是加载一张粗糙的图片,然后图片会慢慢变清晰。不过想到在数据库和 SQL 查询上使用这种模式的人并不多。
也许你会有所疑问:在实际应用当中如何实现这种提速呢?如果数据不是正态分布的可以吗?还能看到那些特征值吗?它是否需要一个特定的数据库?我希望能在这篇文章结束之前回答所有问题,不过先让我介绍完其它的场景,在这些场景里你会看到一些更有意思的想法:以快 200 倍的速度看到 99.9% 准确度的结果!
场景二(过载的集群)。现今大多数数据库用户都无法拥有自己的专用数据库集群。也就是说,你通常要跟团队共享集群,或者是其它的报告和 BI 工具,它们在相同的数据库资源上执行 SQL 查询。当这些集群发生过载,那么只有三种结果:
A. 全局瘫痪。你什么事情都做不了,其他人也一样。也就是说,一旦数据库请求队列被挂起,并且没有更多的 CPU 资源可用,那么就没有人能以他们所期望的速度得到查询结果。
B. 部分瘫痪。你可以终结或挂起一些低优先级的查询,让紧急的查询(例如你的上司要求执行的查询)先执行。也就是说,你让一小部分重要的人开心,但会让其他人不高兴!
C. 如果经常发生上述情况,你可能会购买更多更强大的服务器,或者把系统迁移到云端,根据实际情况使用更多的节点。当然,这需要投入更多的钱,而且会带来不便,而且这是一个长期的方案。
很多人不知道还有第四种情况,它比前面两种更好,而且不像第三种那么费钱。那么它是什么?
为低优先级的查询返回 99.9% 准确度的结果,而为高优先级的查询返回 100% 准确度的结果!根据统计法则,通常使用 0.1% 的数据就可以得到 99.9% 准确度的结果。这就是为什么牺牲 0.1% 的准确性却能换来 100 到 200 倍的速度。我知道没有人愿意接受只有 99.9% 准确度的结果,不过除此以外你所能做的,要么中断查询,排很长的队等候,要么空等查询结束。在场景一里已经提到过,大多数情况下不需要很长时间都能够得到 100% 准确度的结果,但对于那些需要等待很久的查询,可以尝试使用 99.9% 准确性的结果。在文章结束部分我会告诉你们“如何”做到这些。现在只要记住,99.9% 的准确性不代表你会失去 0.1% 的结果。你仍然可以看到所有的东西,只是少了 0.1%,而在大多数时候你根本无法看出区别,除非你非常在意。比较下面两张图表:
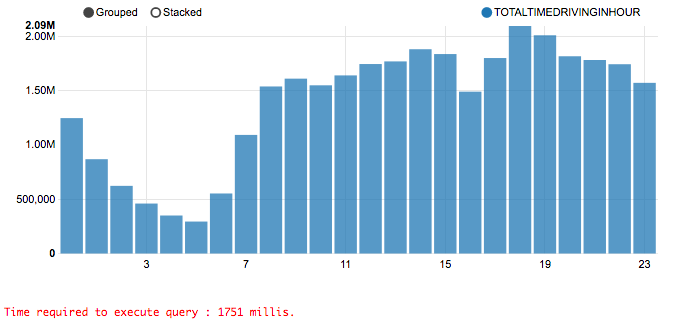
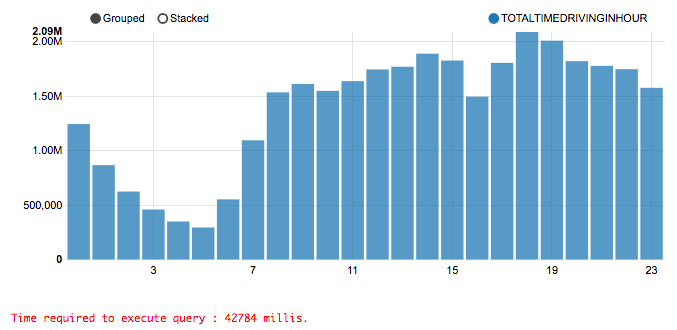
这些查询结果来自著名的 NYC 出租车数据集,它们所展示的是到市区所需要的时间。
你能分辨出哪个是 100% 准确的结果,哪个是 99.9% 的结果吗?对大多数人来说,它们是没有区别的。但上面那个查询只用了 1.7 秒,而下面那个用了 42.7 秒。也就是说,虽然牺牲了 0.1% 的准确性,却节省了 25 倍的 CPU 时间!让我们再来看一种场景,然后我会告诉你们“如何”做到这些。
场景三(机器学习和数据科学)。如果你是一个机器学习专家或数据科学家,你会发现自己经常做一些诸如训练统计模型、参数调优、特性选型或工程方面的事情。最让人感到崩溃的是需要逐个尝试大量的参数和特性,而且机器学习模型的训练会占用很长的时间。集群总是忙于运行和测试模型训练,数据科学家无法在上面尝试更多的模型和参数,因此拖慢了整个进程。
对于大多数应用来说,你完全可以基于非完美的结果做出合理的决策。比如, A/B 测试、问题根源分析、特性选型、可视化、噪音数据或包含缺失数据的数据集。不过如果你是在财务部门工作,那么你应该不会考虑这么做的!
我想另写一篇文章专门讲解如何通过参数调优和特性选型来提速。
那么,我们“如何”做到只牺牲一点准确性就可以换来 200 倍查询速度的提升?
答案是使用近似查询处理技术(AQP)。实现 AQP 有很多种方式,最简单的做法是使用随机取样数据。事实表明,如果你的数据是非正态的,那么使用随机取样数据会导致大部分特征值丢失,而只有少数几个会出现在你的原始表里。所以更常用的是一种叫作“分层取样”的技术。为什么要分层取样?考虑以下情况:
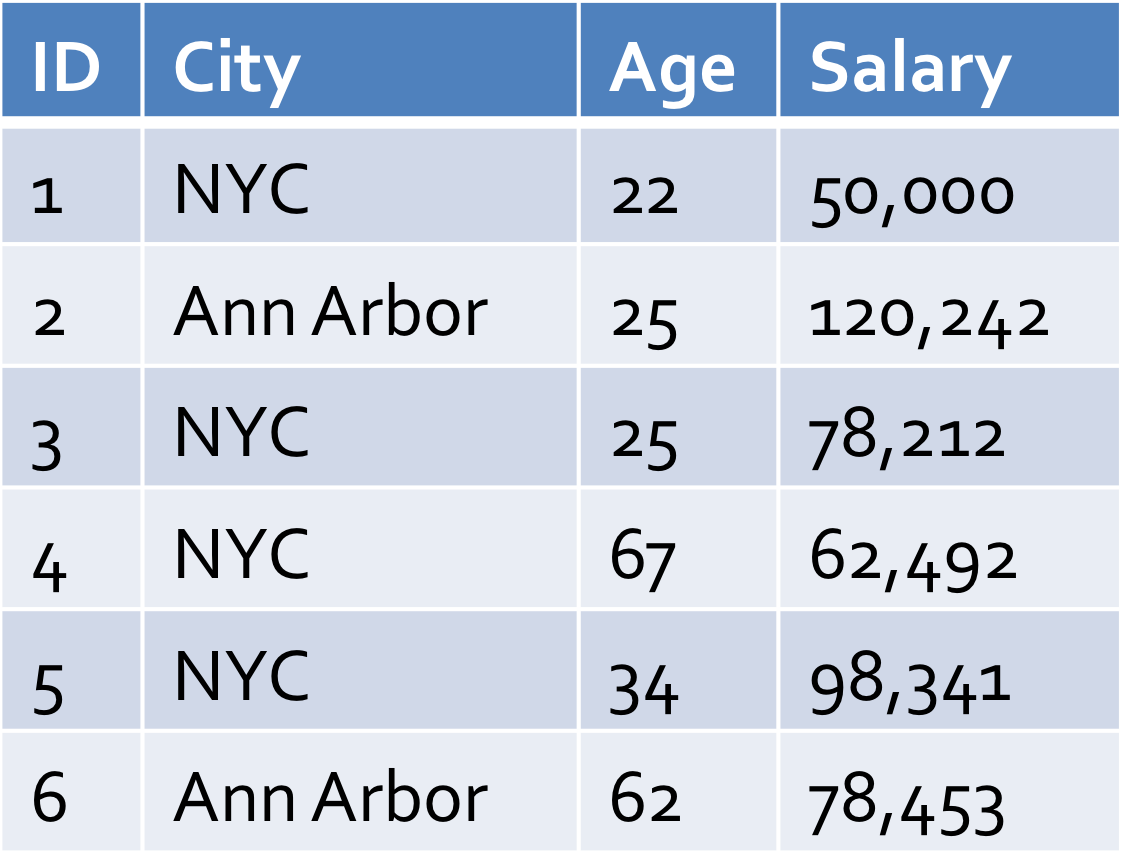
假设你想在这个表上面运行下面的查询:
SELECT avg(salary) FROM table WHERE city = ‘Ann Arbor’
运行这个查询是没有问题的,不过如果这个表有一亿条数据或者这些数据分布在多个机器上,那么这个查询可能需要运行几分钟才能得到结果。你可以在随机的取样数据上运行这个查询,比如:
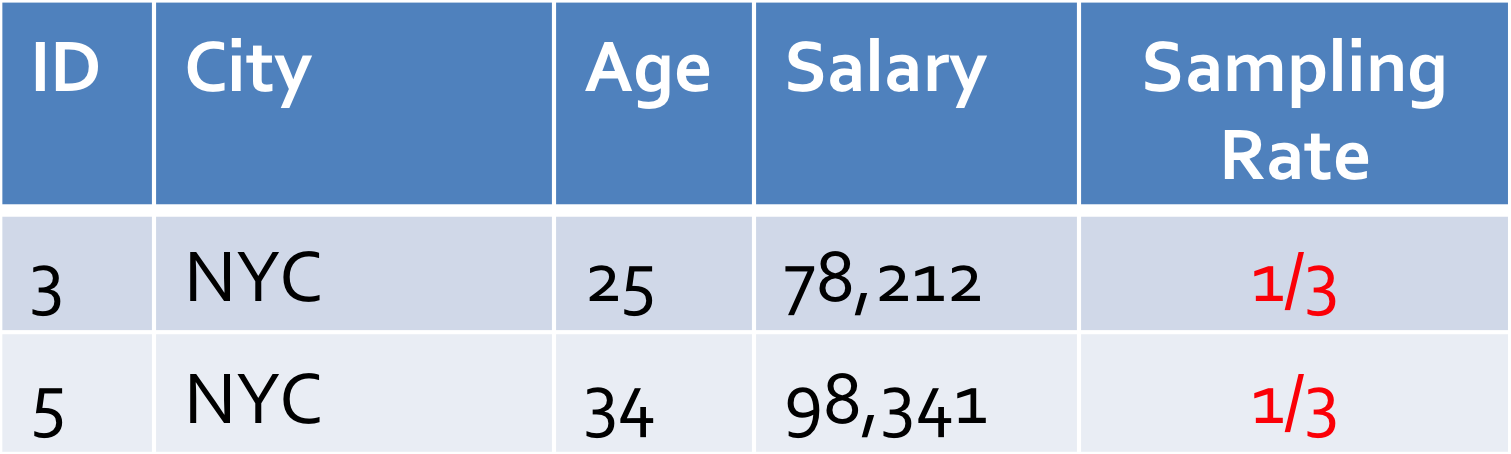
因为 Ann Arbor 元组相比原始表里完整的 NYC 元组会少很多,所以你从取样数据里可能只能看到少许的几个,或者根本看不到。而分层取样会先对数据表按照 City 进行分层(例如,分区),然后针对每个 City 的数据进行取样:
|
ID |
City |
Age |
Salary |
Sampling Rate |
| 3 | NYC | 67 | 62,492 | 1/4 |
| 5 | Ann Arbor | 25 | 120,242 | 1/2 |
不需要太多的统计数据,我们可以看到这样的分层取样可以保证得到非常精确的结果,而我们只使用了原始数据的一小部分。
接下来的问题是你该怎么对数据进行分层取样以及如何衡量结果的准确性。我在一本书里写了一个章节介绍这方面的内容。不过我们可以借助一些工具自动完成这些工作。有一些现成的产品可以使用,你只需要按下按钮,它们会自动帮你完成剩下的工作,并很快地返回结果。有时候,根据这些结果,你完全可以决定如何在准确性和速度之间做出权衡。
BlinkDB/G-OLA
尽管有很多的 AQP 技术可选择,不过 BlinkDB 仍然可以算是第一个开源的分布式(高并行)AQP 引擎。我参与了这个项目,所以我可能会偏袒它。我很喜欢BlinkDB 的解决方案,我认为它给后来出现的学院派或商业的解决方案带来了灵感。 Databricks 公司接手了 BlinkDB 后续的开发工作(这个公司把 Apache Spark 商业化了)。不久前,Databricks 发布了 BlinkDB 的一个插件,这个插件可以允许用户对结果进行随意的调整,直到满意为止。这个插件叫作 G-OLA ,不过它并没有被公开发布,而且 BlinkDB 也很久没有更新了。
SnappyData
SnappyData 是一个开源的内存混合分析平台,它的引擎同时支持 OLTP、OLAP 和流。这个数据库引擎直接对 Apache Spark 进行了扩展(所以与 Spark 完全兼容),并提供了可控的分层取样和概率性结构来支持 AQP。它的查询语法跟 BlinkDB 类似,允许用户指定准确度,也就是说准确度是可以调整的。例如,如果你需要完整的结果,那么你可以指定 100% 的准确度(默认就是这样的)。不过如果你想快点得到结果,可以使用 99% 的准确度,这样可能在一秒钟内就可以得到结果。在我看来,SnappyData 的一个优势是它使用了可控的分层取样。也就是说,你可以在几秒内运行完一个查询,就算查询的是几 T 的数据,或者查询是运行在笔记本上或在同时运行着几个查询的集群上。SnappyData 还内置了对流的支持,你可以实时地对输入流进行取样。
SnappyData 另一个优点是它提供了很多上层的用户界面,你不需要具备很专业的统计知识也能使用 AQP 特性。例如,他们现在提供了一个云服务,叫作 iSight ,它会在后台运行查询的同时使用 Apache Zeppelin 作为前端来可视化查询结果。
爆料:我是 SnappyData 的推崇者。
Presto
Facebook 的 Presto 有一些实验性的特性可以满足基本的近似聚合查询。我不知道这些特性是否是最新的,不过它的不足之处在于你需要使用不一样的查询语法(需要修改 SQL)才能使用这些特性。对现有的 BI 工具和应用程序来说,这样会有点麻烦,因为这样就无法体现潜在的提速价值,除非我们使用新的语法对原有的查询进行重写。
InfoBright
InfoBright 提供了近似查询特性( IAQ )。跟其它系统不一样的是,IAQ 完全不使用样本。可惜的是,对于 IAQ 的工作原理,我们也知之甚少,也不知道它是如何提供准确性保证的。不过通过阅读他们的博客,我认为他们针对底层数据进行了建模,然后使用这些结果代替样本。IAQ 不是开源的,在他们的网站也找不到更多的细节信息,不过他们的解决方案看起来挺有意思。
ABS
Analytical Bootstrap System(ABS)是另一款近似查询引擎,它使用样本和高效的统计技术来检查错误。不过它的代码有点旧了,而且只支持早期版本的 Apache Hive。这个项目目前处在不活跃状态。
Verdict
Verdict 是一款中间件,它的客户端端是应用程序或 BI 工具,后端是 SQL 数据库。你可以像往常一样在现有数据库上运行查询,并立即得到近似结果。原则上,可以在任何 SQL 数据库上使用 Verdict,也就是说,它不会限制你使用特定的关系型数据库。不过目前它只提供了 Spark SQL、Hive 和 Impala 的驱动。它的优点在于,它可以通用于任何 SQL 数据库,而且它是开源的。它的不足之处在于,因为它是一个中间件,所以它可能不像 InfroBright 或 SnappyData 那么高效。
爆料:我是 Verdict 的设计者。
Oracle 12C
Oracle 12C 支持近似 count distinct 和近似百分率。这些近似聚合不仅改进了性能而且使用更少的内存。Oracle 12C 还支持物化视图,这样用户就可以对近似聚合进行预处理。不过,虽然近似 count distinct 和近似百分率很有用,也很常用,不过 Oracle 12C 并没有提供对其它类型查询的支持,不过这些特性已经给用户带来很大的好处了。不过据我所知,有很多数据库厂商一直以来都支持 count distinct(例如,使用 HyperLogLog 算法)。这里有一篇论文,如果你对 Oracle 12C 的这些新特性感兴趣,可以读一读。
查看英文原文: How To Make Your Database 200x Faster Without Having To Pay More?
感谢陈兴璐对本文的审校。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




