Apache Kylin 社区非常高兴地宣布,继 1.5.0 后的又一个主要发行版 v1.6.0 于日前正式发布。
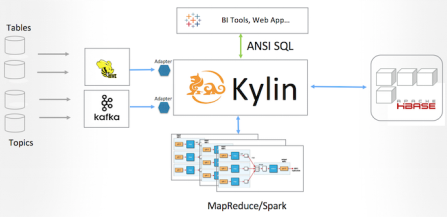
Apache Kylin 是一个开源的分布式分析引擎,提供 Hadoop 之上的 SQL 查询接口及多维分析(OLAP)能力,支持对超大规模数据进行秒级查询。
Apache Kylin v1.6.0 带来了更可靠更易于管理的从 Apache Kafka 流中直接构建 Cube 的能力,使得用户可以在更多场景中更自然地进行数据分析,使得数据从产生到被检索到的延迟,从以前的一天或数小时,降低到数分钟。
全新的流式构建引擎
全新的 Apache Kylin 流式构建引擎是在 Kylin v1.5 的"可插拔 "架构下的一个完美实现︰ 将 Kafka 主题视为一种数据源,实现相应的适配器,将数据先抽取、转换和保存到 HDFS,接下来使用各种 Kylin 的构建引擎(MR/Spark 等)对数据进行并行计算 。
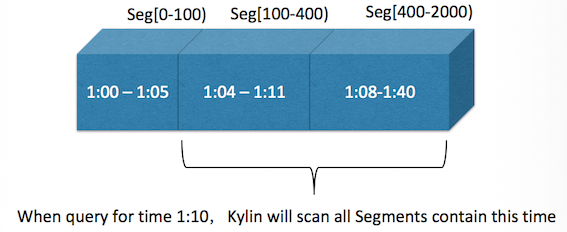
Kylin 将开始 / 结束消息的偏移量(offset)计入了每个 Cube segment,并使用偏移量作为分区值,从而对于早到达和晚到达的消息最终都能够被检索到,从而保证了查询结果的准确性。
此外,Kylin ODBC Driver 也发布了新的 1.6 版本,对 Tableau、PowerBI 和 Cognos BI 有了更好支持。
在这一版本中 Apache Kylin 社区一共解决了 102 个 issue,包括 Bug 修复,功能增强及一些新特性等。主要 issue 有:
[KYLIN-1726] - 可伸缩的流式 Cube 构建
[KYLIN-1917] - TopN 性能增强
[KYLIN-1919] - 支持 Kafka 的嵌入格式的 JSON 消息
[KYLIN-2012] - 可靠同步 hive 表模式更改
[KYLIN-2054] - 支持更多 Kafka 消息的时间戳格式
[KYLIN-2055] - 增加 Boolean 编码
[KYLIN-2070] - 支持多 segment 并行构建/合并/刷新
[KYLIN-2082] - 支持更新流式表模式和配置的修改
下载安装:
下载 Apache Kylin v1.6.0 源代码及二进制安装包,请访问下载页面。
升级:
此版本的元数据向前兼容,请参考 https://kylin.apache.org/docs16/howto/howto_upgrade.html"> 升级指南进行升级 %E8%BF%9B%E8%A1%8C%E5%8D%87%E7%BA%A7)。
获得支持
升级和使用过程中有任何问题,请:
提交至 Kylin 的 JIRA: https://issues.apache.org/jira/browse/KYLIN/
或者
发送邮件到 Apache Kylin 邮件列表: user@kylin.apache.org 和 dev@kylin.apache.org
感谢每一位朋友的参与和贡献!
作者介绍:
史少锋,Kyligence 技术合伙人 & 资深架构师 Apache Kylin 核心开发者和项目管理委员会成员(PMC),专注于大数据分析和云计算技术。曾任 eBay 全球分析基础架构部大数据高级工程师,IBM 云计算部门软件架构师;曾是 IBM 公有云 Bluemix dev&ops 团队核心成员,负责平台的规划、开发和运营。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




