不久前百度首席科学家吴恩达在百度语音开放平台上线三周年活动上,发布了百度四项最新语音技术——情感合成、远场方案、唤醒二期技术和长语音方案,并宣布这些技术通过免费接口提供给开发者使用。这在一定程度上促进了语音输入技术的发展,让更多的用户采纳语音输入。再加上这些年移动智能设备的普及,算法模型和语义分析技术的成熟,AI 技术的深度使用,帮助输入法在智能化道路上更快发展。
11 月 26 日,由百度开发者中心和极客邦科技、InfoQ 联合举办的第 68 期百度技术沙龙邀请了百度输入法团队的研发工程师们,从三个方面解析百度输入法移动端输入技术,包括对 iOS 输入法启动速度和内存的优化措施;AI 在手写引擎中的应用,输入体验的提升;以及智能语音输入的技术核心,实现方式,优化细节等。
iOS 输入法启动速度优化(下载 PPT )
百度资深研发工程师 范敏虎先是介绍了百度输入法 iOS 版本是 2014 年苹果在 iOS8 上线开放 Extension 开发之后,上线到 AppStore 的,它的前身是百度输入法越狱版。由于 Extension 的特殊性,系统对 Extension 的运行做了很多限制,首先限制的就是速度,其次就是内存限制。表面上看输入法仅仅是一个面板,但是麻雀虽小五脏俱全,开发输入法甚至会面临比普通 app 更多的技术问题。
启动过程中,需要进行三个步骤,Extension 查找、Extension 启动、Host 与 Extension 交互。Host 通过 xpc 的方式请求 pkd,找到需要的 Extension;Host 通过 name 连接 Extension,xpc.launchd 启动 Extension;在交互过程中,Host 远程调用 Extension 的方法来展示键盘。由下图可见,整个启动过程里可能会遇到四个问题。
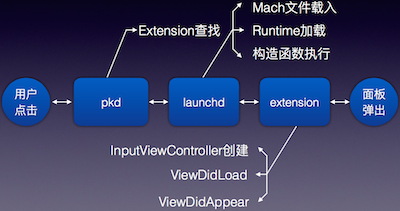
这四个问题包括:皮肤文件解码载入需要大量 CPU 时间,UI 渲染需要一定的 CPU 时间,内核词库的载入消耗大量 I/O 时间,静默任务处理也要耗费一定的时间。这里面还需要考虑皮肤文件的大小,词库的大小,I/O 的处理方式等等,这些都会直接影响启动速度。范敏虎说,他们的最终解决方案,就是在皮肤生成的时候把图片进行解码进行保留,然后载入解码信息。其次就是避免频繁创建对象,再次是内核操作在独立线程运行的。第四点就是内部单独调度,每个任务被当成一个进程处理。
上面提到的一个比较重要的事情就是关于面板重用,在手机上不同的 App 里面,都会出来一个新的输入面板,势必会影响输入速度。范敏虎的解决方案就是创建一个缓冲池,把面板对象放入缓冲池,同时尽量让数据层独立,好处就是不需要重复创建数据层对象。另外就是做了一个均衡,尽量使所有创建的面板对象占用尽可能相同的内存,其好处就是可以释放更多的内存。(如下图结构)
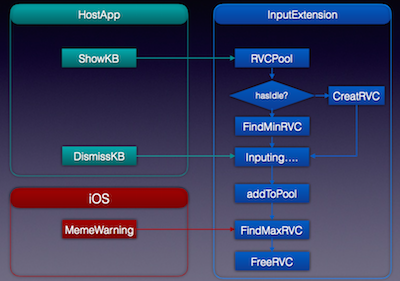
次任务调度
为了不影响输入,静默任务被添加到面板启动过程中,这会严重影响面板的启动时间和稳定性,同时还会出现面板上多次弹窗等问题。范敏虎说,这个问题的解决方案可以概括为如下:
- 将每个功能抽象成一个任务;
- 每个任务配置自己的触发条件,监控事件,所需资源,优先级等信息;
- 调度模块会调整任务优先级,统计运行时间;
- 当任务崩溃超过一定次数时,下次启动就会卸载该任务;
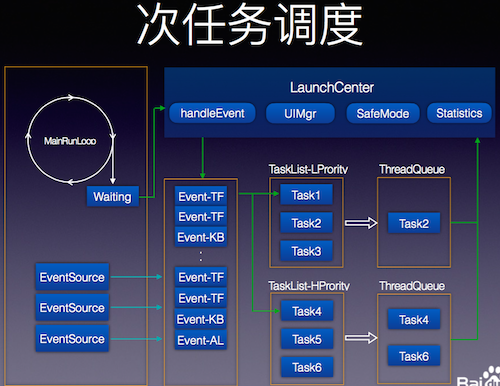
经过各种优化,包括内存和渲染独立,减少执行时间,实现交互流畅,最终给用户一个很好的操作体验。
AI 助力手写输入引擎提升输入体验(下载 PPT )
百度资深研发工程师贺亮说,机器学习是一个重要的领域,百度输入法也在使用机器学习的算法。百度输入法第一代使用的是比较传统的模式识别技术,仅仅是对界面上的笔记轨迹进行处理。现在使用的是基于深度学习网络的技术,就是直接抛到网络里面进行计算,得到一个识别结果。第一代手写引擎的架构(下图)。
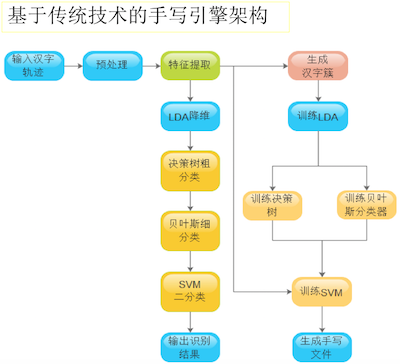
首先,特征提取部分就是一个训练过程和识别过程。训练过程就是先拿到已经标注好的字,对特征进行压缩。训练决策树是对于特征做粗分类,得到一个结果。分类器就是对于两个比较相近的字进行分类,最后得到一个输出结果。
关于轨迹预处理,通常情况下会遇到这些问题:
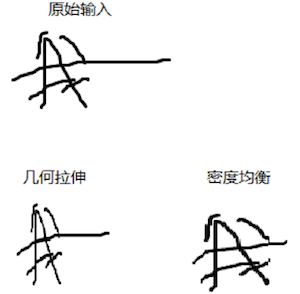
由于设备书写区域的分辨率差异,不同的人书写习惯差异等因素,导致我们接受到的笔迹数据有很大变异。1. 大小 / 长短几何变异(设备分辨率,书写随意性);2. 笔迹线速度差异(书写的快慢,设备的采样频率);3. 密度分布变异(书写随意性造成)。对轨迹重新采样之后,利用 Bézier 拟合对轨迹进行重采样等距的点,笔迹平滑,采用 Bézier 三阶曲线进行拟合,按曲率阈值进行分段拟合,几何拉升和密度拉升,让轨迹尽量归一化。
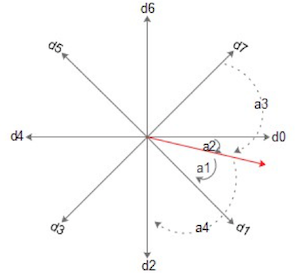
接下来是对轨迹进行特征提取,它的基本原理就是将笔迹采样点的位置和方向这两个属性进行向量化描述。方向特征采用 8 方向来表示切线方向,(如下图所示)利用 d0-d8(分别表示横竖撇折和反横竖撇捺折)8 个值来表示切线方向,其中 d0=a1,d1=a2,d2=a4,d7=a3(其余都为 0)来表示红色方向的特征值。
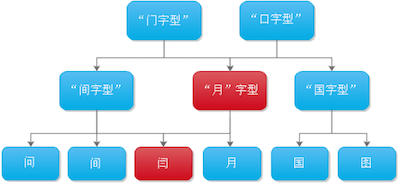
由于高维向量特征不利于计算,训练样本不足导致分类器泛化性能不足,所以要对特征进行降维处理,来判断它到底是什么词汇,这是一个很耗时的工作,于是采用了决策树的方式解决这个问题。如果训练阶段对汉字使用 K 均值模糊聚类,就形成(下图)决策树。识别阶段通过决策树进行粗分类(利用欧式距离来做出抉择),粗糙的识别出一些汉字作为备选。
贺亮说,在做进一步优化的时候遇到了一些瓶颈。所以采用了最近比较火的深度学习方法,选取了深度网络作为第二代手写引擎技术试验的方案。这个方案的识别率从传统模型的 90% 上升到了 95%。它的优点包括,从原始数据中总结出结构化的特征,层数越深,能表征的特征越复杂。
不同的网络模型对应着不同的特征,举例而言,方向特征 + 全链接神经网络模型;图像特征 + 卷积神经网络模型;方向特征 + 局部感知神经网络模型。在选择与构造神经网络模型的时候,要找到容量性能与识别效果的平衡点。作为在手机端上运行的手写引擎,我们最终选择了 5 层的神经网络结构,这在性能容量和识别率上都达到了一个令人满意的效果。
然后神经网络最大的一个问题就是性能问题,解决方案有两个方向。第一个方向,就是定点化数据,之前神经网络节点,里面的参数使用就是单精度浮点数,随后按照一定的范围内调整成一个无符号的整数。另一方面,可以降低它的计算复杂度。另外,可以通过神经网络计算来对硬件进行加速,例如利用 NEON 指令集进行硬件加速,最后的效果是速度提升了 6 倍。
语音输入方式已大势所趋(下载 PPT )
语音输入现在的应用场景确实很多,发展的进度也很快,上面两个演讲基本上都是基于技术的角度来解读。接下来,百度手机输入法 Android 团队经理、技术负责人施聪,和百度语音开放平台资深研发工程师魏利开,分别从语言技术跟输入法结合,以及案例的方向对百度语音输入法做了详细的介绍。
产品呈现
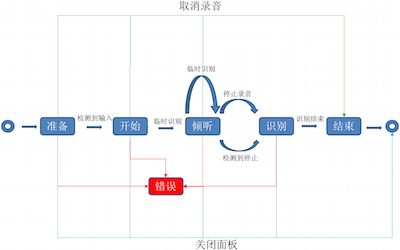
语音输入和文字输入有些差别,有的时候是一边说,一边转换成文字呈现在屏幕上;另一种是说完即一次性发送所有的结果,然后显示。这里需要关注的就是在讲话之际提前把麦克风预热。然后去启动语音输入。等语音输入准备好,就检测录音,真正检测到录音结束后,即关闭录音,释放资源,这是一整套理想的操作流程。实际场景中不可避免的会遇到中途接电话、网络不好、麦克风被手挡住等状况,所以需要做一些释放资源,或者跟踪麦克的设置。
正常情况下会有很多应用场景,例如输入“单身狗”语音过程当中,需要做一个语音识别,然后做语义识别,得出一个整体的语义结构,可以给这个结果设置最基本的可信度,如分数“0.65”,表示语译理解的可信度状态。
个性化输入
语音组做了深度定制跟产品结合,可以实现个性化的功能。比如说,在地图当中需要搜索地理位置,在音乐场景中需要搜索歌曲名称,在新闻场景中需要搜索热词,所以通过场景去定制识别。另外,为了减少对性能的消耗,提醒用户的内存状况,手机性能状况,于是给用户定制了不同的云包,其实到云端做识别精确度更高。
案例分享
魏利开在现场告诉了大家一个好消息,百度语音的识别准确率已经达到了 97%,事实上,并不是所有产品都能达到 97% 准确率的。当然,97% 准确率也是有前提的,它依赖 2 个条件:产品设计和用户配合。
- 产品设计上,应该很好理解,语音输入法主要是针对中文用户群体的;长按和点击的融合,尽量给软件更多的识别时间;提前启动录音机,延后关闭录音机。
- 用户配合方面,最好说普通话;选择高信噪比环境;不抢说,不抢停,让录音机有充分的时间来缓存录音。




