谷歌旗下的 DeepMind 公司近日公布了 WaveNet 项目,这是一种全面卷积(Convolutional),基于概率,可自动回归的深度神经网络。根据DeepMind 的介绍,该项目可以用比现有最好的文字转语言( TTS )系统更棒的效果通过音频和声音合成更自然的语音和音乐。
语音合成能力主要源自串接式(Concatenative) TTS,会通过由单一录音者录制的简短语音片段组成的数据库选择语音片段,重新组合并形成语音。这种方式不够灵活,无法轻松地进行调整输出新的声音,如果需要对现有声音的特诊进行较大改变,通常需要彻底重建数据库。
DeepMind 认为,原有模式极大依赖通过一个输入源,或一个录音者生成的大容量音频数据库,WaveNet 依然保留了这种模式,并将其作为一组参数,可根据新的输入结果对原有模式进行修改。这种方法也叫做参数化(Parametric)的TTS 实现,可通过支持参数的模型生成在音调或语调等特征方面有所差异的语音,随后这些语音还可通过模型进行进一步的完善。相比以往的方法使用预先生成的原始音频片段对模型进行训练,WaveNet 的 Phoneme 可调整字词和句子的顺序参数,生成更有意义的词语和句子结构,并可独立于有关声调、声音质量,以及音素语调的参数进行调整。借此 WaveNet 可以生成连续的语言类声音,并通过语言结构为这些声音赋予相关的含义。
“由于这个模型不以文字为条件,因此可以通过更为平滑的方式生成不存在,但类似人类语言的字词,同时在声音语调方面也更真实… 我们发现这个模型还可以吸收语音本身之外其他方面的音频特征,例如可以模仿声学效果和录音质量,以及讲话者的换气和嘴部活动。”
试听者在听过 WaveNet 生成的英文和普通话音频后,认为该系统能生成比最棒的参数化和串接式系统更自然的声音。DeepMind 在论文中详细介绍了这个实验的细节,并补充说:
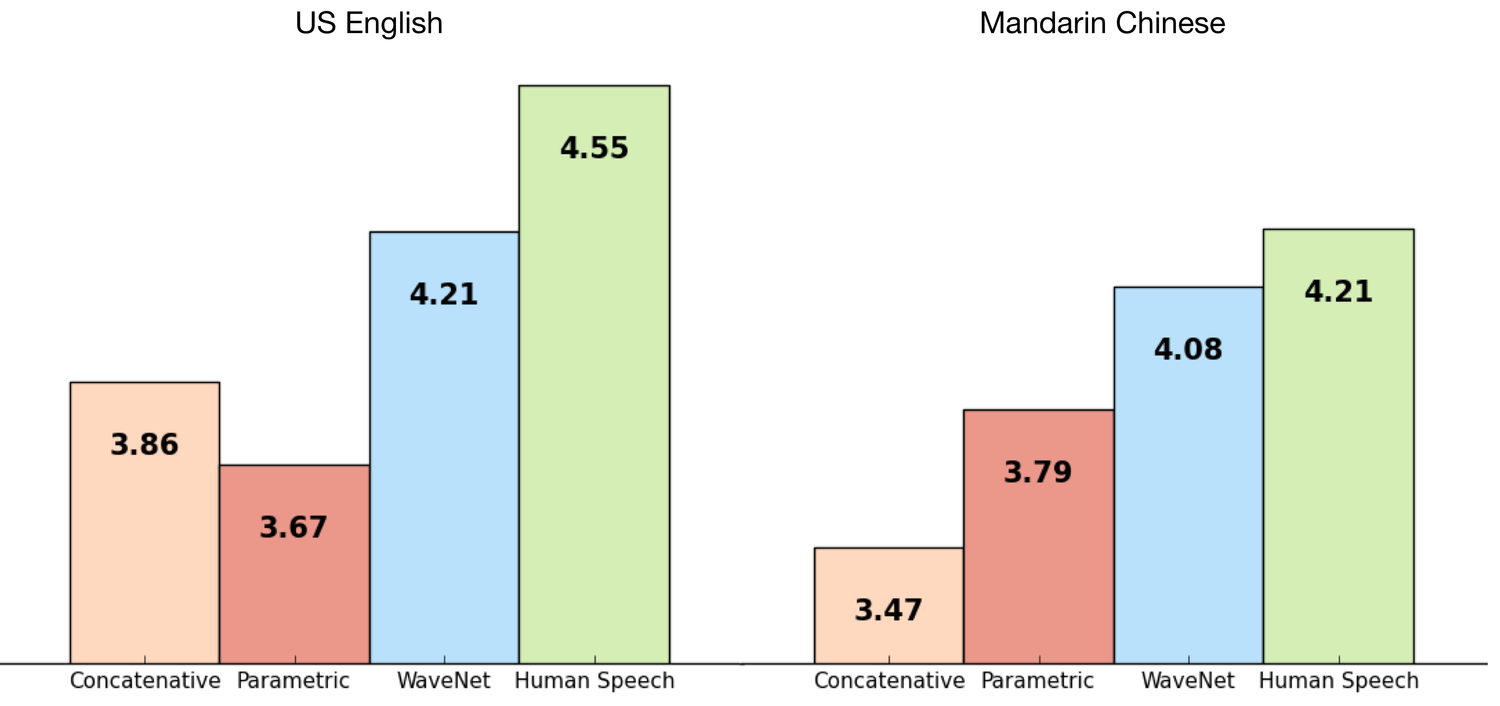
“第一个试验中我们尝试了自由式的语音生成(不以文字为条件)。我们使用了 CSTR 声音克隆工具包(VCTK)中的英文多讲话者语料(Yamagishi,2012),并通过条件设置让 WaveNet 只关注讲话者。这个条件是通过 One-hot 向量形式以讲话者 ID 的方式提供给模型的。所用数据库包含来自 109 位讲话者,总时长 44 小时的数据… 第二个实验主要针对 TTS。我们使用了谷歌打造北美英文和中文普通话 TTS 系统时使用的同一个单一讲话者语音数据库,北美英文数据库包含 24.6 小时的语音数据,中文普通话数据库包含 34.8 小时的内容,所有内容均由专业的女性演讲者讲述。”
对串接式 TTS、参数化 TTS、WaveNet 以及人类语音音频样本(仅用作控制组)的人类语言自然度进行五分制盲测有了结果。试听者在不知道音频来源的前提下,听过音频样本后为每个样本打分。该论文所用数据集包含针对100 个测试短句给出的超过500 个评分,通过这些评分计算出平均意见得分( MOS )作为最终分数,只有 WaveNet 的自然度评分最接近人类语言的音频样本。
DeepMind 还演示了如何通过 WaveNet 最为核心的“学习型抽象”利用音频训练数据集合成音乐。目前该技术最大的问题主要围绕语音合成技术的长远影响以及一些人所谓的人工智能。但目前还不确定WaveNet 包含哪些核心语言或处理引擎,并且他们尚未提供范例代码。
查看**** 英文原文: DeepMind Unveils WaveNet - A Deep Neural Network for Speech and Audio Synthesis





{kind=link}