前不久在百度世界大会上,百度首席科学家吴恩达首次宣布对外开放百度深度学习平台,以推动人工智能技术的快速普及,把在搜索、图像识别、语音识别、自然语言处理、用户画像及情感分析等人工智能领域的优势整合升级,为程序开发者提供了一个功能更全、效果更好的深度学习框架。
其实,百度很重视对于开源软件的使用,也愿意把内部的技术以开源的形式贡献出来,正如在 10 月 22 号由百度开发者中心、百度开源委员会联合举办的第 67 期“百度开源专场”技术沙龙上,来自百度的工程师于洋和颜世光,分别分享了百度开源的两个最新项目:PaddlePaddle 百度深度学习框架和百度搜索架构开源产品线(例如 Tera、BFS、Galaxy 等),并结合具体的产品案例,分享百度开源技术最新实践经验。目前这些项目都已经在 github/baidu 上开源。
什么是 PaddlePaddle 深度学习平台?
首先做个简单的介绍,PaddlePaddle 是百度自主研发的性能优先、灵活易用的深度学习平台,是一个已经解决和将要解决一些实际问题的平台。目前百度有超过 30 个主要产品都在使用 PaddlePaddle。关于机器学习、深度学习和浅层学习的内容就不详细介绍了,接下来重点讲述一下 PaddlePaddle 的整体架构。
关于 PaddlePaddle 整体架构( PPT 下载)
说到 PaddlePaddle 的整体架构,主要从这几个方面入手:多机并行架构、多 GPU 并行架构、Sequence 序列模型和大规模稀疏训练。多机的并行架构和序列模型的实现都是实现神经网络最复杂的东西,那么具体怎么实现全连接?
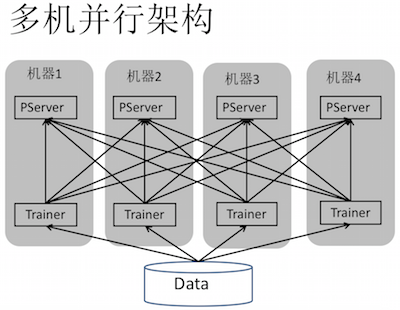
PaddlePaddle 是 2013 年启动时比较流行的架构是 Pserver 和 Trainer 的架构。在多机并行架构中数据分配到不同节点,下图里灰色部分表示机器,方框里表示一个进程,Pserver 和 Trainer 是分布在两个进程里,中间的部分是网络通讯连接。
下面来介绍一下什么是大规模稀疏模型训练。稀疏模型训练是说输入数据是稀疏的,由于稀疏输入,那么灰色的神经元和连接在训练中都没有作用,灰色神经元的输出是 0,灰色连接的梯度是 0,梯度是 0 的话,简单的 SGD 不更新权重。所以只有蓝色的连接有价值,需要从 PServer 服务器获得最新参数,需要计算梯度,并将梯度传送回参数服务器。(如下图)
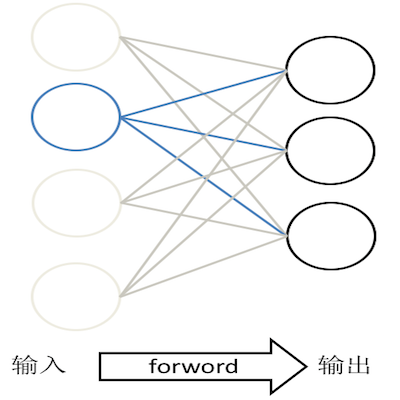
除了上面所提到的,还有两外两种情况下的稀疏模型:
- 大规模稀疏模型(多机器)——每个 Trainer Prefetch 出自身需要的参数和服务器通信。
- 大规模稀疏模型(正则化)——简单的 SGD 确实在梯度为 0 的时候,不去更新参数,但是加上正则化就不一定了;比如 L2 正则化,就要求参数的 2 范数持续减小。
PaddlePaddle 实现时的一些思考
基于 OP(操作)还是基于 Layer(层)?
- 基于 OP——从矩阵乘法配起,一步一步对应一个一个数学运算。
- 基于层——直接写一个全连接层,LSTM 层。
- 基于 OP 的优势 Tensorflow——更灵活,更可以让研究人员构造新的东西
- 基于 Layer 的优势 Caffe——更易用,让细节暴露的更少;更容易优化。
基于 OP 还是基于 Layer?——支持大部分 Layer,但是也支持从 OP 开始配网络(矩阵乘发,加法,激活等等);对于成型的 Layer(LSTM)使用 C++ 重新优化。原因在于,PaddlePaddle 是企业解决现有问题的框架,不是纯粹的科研框架;企业需要性能,也需要灵活性。
多机通信基于 MPI 还是 Spark 还是 K8s + Docker?PaddlePaddle 底层通信不依赖于任何网络框架,PaddlePaddle 的网络任务需求相对简单,根源在于任务周期短(连续运行几周);任务可以失败(多存 checkpoint)。同时,PaddlePaddle 的网络需要高性能,从头手写网络库更方便性能调优,RDMA 可以更好的支持。同理,PaddlePaddle 底层不依赖任何 GPU 通信框架。
百度搜索开源基础架构( PPT 下载)
颜世光是百度搜索基础架构负责人,在这次沙龙上介绍了百度当前的这套搜索引擎,以及搜索引擎背后的事件。重点部分是百度这套开源的基础架构软件站,它包括分布式数据库、文件系统、管理系统、分布式协调服务、网络通信框架。下面来一一介绍。
当前,用户通过互联网搜索引擎的期望在不断的变化,整个搜索引擎的期望从之前的几周变成现在的几分钟,之前几周之内可以处理几百亿的数据,现在要在几分钟之内处理几万亿的数据,这是个鲜明的矛盾。其实解决方案就是构建一个大数据处理平台,也称之为“基础架构系统”。这个基础架构系统目标首先是海量的目标数据。其次就是在于集群利用率的保证,这个利用率可能是 CPU 利用率,它会为你节省成本。
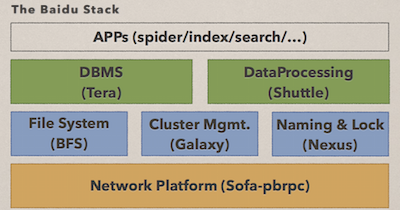
这里可以简单介绍一下百度内从事开发的平台——baidu stack(如上图)。这个平台分三层,最的底层是网络通讯,是一个高性能的 RPC 框架,它会把所有的网络问题屏蔽掉,让上层的系统在开发中不需要考虑网络拓扑。中间一层是基础服务,包括分布式文件系统,它解决了数据处理。第二就是集群管理系统,它管理的数据可以让程序部署变得代价很小。第三是分布式的协调服务,一方面用做服务发现,另外就是分布式。最上层是核心数据库和数据处理系统。在理解上可以将这套系统和 Hadoop 相关的系统类比。从中间这层说起,Hadoop 有 HDPS,Hadoop 在分布式服务这块使用 Cukaber,比如也有 Storm、Spark 这些。整个基础架构系统的设计思想有两个,第一是分层。无论是 Hadoop 系还是谷歌,他们都使用类似的思想,这个思想主要是分工和借用,让不同分工解决不同问题。另外一个思想就是高效,解决用户对处理速度的期望。百度主要使用 SSD、万兆网卡,这套分布式基础架构完全是用 C++ 实现的。首先是核心的数据库 Tera,这里列了 Tera 数据库的核心功能,包括全局有序、自动分裂、合并、支持快照。
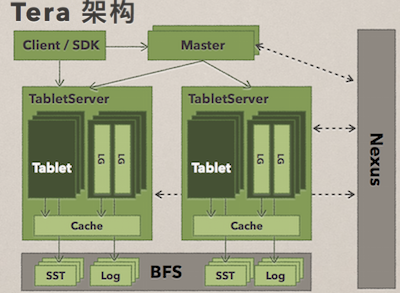
Tera 的架构可以看(如上简图),从图上我们可以看到它有核心就是绿色两部分,是 Master 和 TableServer,提供整个数据节点都是 TableServer,所有的访问经过 Master,让它扩展到几千台服务器中。灰色的底层数据都是在分布式文件系统上,自身没有任何数据,被设计成无状态,当一个 TableServer 宕机后,会从另外一个机器拉取数据,不会有任何损失。同样底层的分布式文件系统可以提供很大的帮助,它是通过 Nexus 做的。
这里简单介绍一下 Tera 的核心技术。⽔水平扩展方面能做到无单点;在线分裂、合并;⾃自动负载均衡;通过 LSM-Tree 做到实时同步,并且 Tera 还具有多语言支持的特点。Tera 在百度内部有非常广泛的应用,例如百度的网页库, 百度将万亿量级的网页存储在 Tera 中。
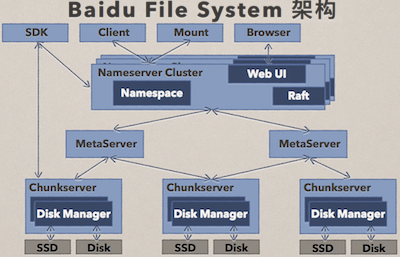
这里再介绍一下如上图的百度文件处理系统(BFS),不仅在百度,BFS 在外部的使用价值也是很高的。那么 BFS 具有哪些特点呢?首先是持续可⽤:分布式 Master,多机房数据冗余。其次就是实时高吞吐:慢节点处理,元数据管理。
因为篇幅有限的原因,这里就介绍这么多,更多详细的内容,大家可以下载两位讲师的演讲 PPT,也可以观看后期整理出来的演讲视频。




