大家好,非常高兴能在这里给大家分享,首先简单自我介绍一下,我叫曾勇,是 Elastic 的工程师。Elastic 将在今年秋季的时候发布一个 Elasticsearch V5.0 的大版本,这次的微信分享将给大家介绍一下 5.0 版里面的一些新的特性和改进。
5.0? 天啦噜,你是不是觉得版本跳的太快了。
好吧,先来说说背后的原因吧。

相信大家都听说 ELK 吧,是 Elasticsearch、Logstash、Kibana 三个产品的首字母缩写,现在 Elastic 又新增了一个新的开源项目成员:Beats。

有人建议以后这么叫:ELKB?
为了未来更好的扩展性:) ELKBS?ELKBSU?…
所以我们打算将产品线命名为 ElasticStack
同时由于现在的版本比较混乱,每个产品的版本号都不一样,Elasticsearch 和 Logstash 目前是 2.3.4;Kibana 是 4.5.3;Beats 是 1.2.3;

版本号太乱了有没有,什么版本的 ES 用什么版本的 Kibana?有没有兼容性问题?
所以我们打算将这些的产品版本号也统一一下,即 v5.0,为什么是 5.0,因为 Kibana 都 4.x 了,下个版本就只能是 5.0 了,其他产品就跟着跳跃一把,第一个 5.0 正式版将在今年的秋季发布,目前最新的测试版本是:5.0 Alpha 4
目前各团队正在紧张的开发测试中,每天都有新的功能和改进,本次分享主要介绍一下 Elasticsearch 的主要变化。
Elasticsearch5.0 新增功能
首先来看看 5.0 里面都引入了哪些新的功能吧。
首先看看跟性能有关的。
第一个就是 Lucene 6.x 的支持。
Elasticsearch5.0 率先集成了 Lucene6 版本,其中最重要的特性就是 Dimensional Point Fields,多维浮点字段,ES 里面相关的字段如 date, numeric,ip 和 Geospatial 都将大大提升性能。
这么说吧,磁盘空间少一半;索引时间少一半;查询性能提升 25%;IPV6 也支持了。
为什么快,底层使用的是 Block k-d trees,核心思想是将数字类型编码成定长的字节数组,对定长的字节数组内容进行编码排序,然后来构建二叉树,然后依次递归构建,目前底层支持 8 个维度和最多每个维度 16 个字节,基本满足大部分场景。
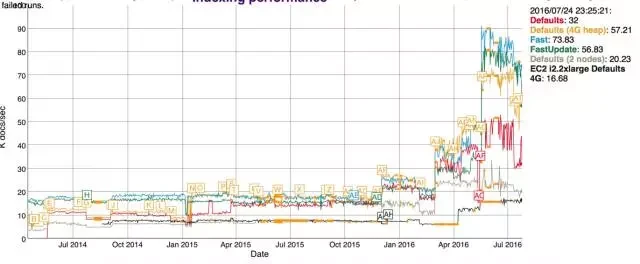
说了这么多,看图比较直接。
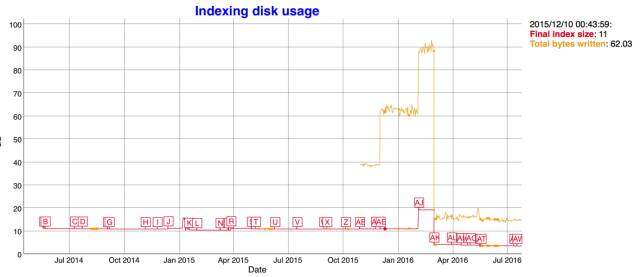
图中从 2015/10/32 total bytes 飙升是因为 es 启用了 docvalues,我们关注红线,最近的引入新的数据结构之后,红色的索引大小只有原来的一半大小。
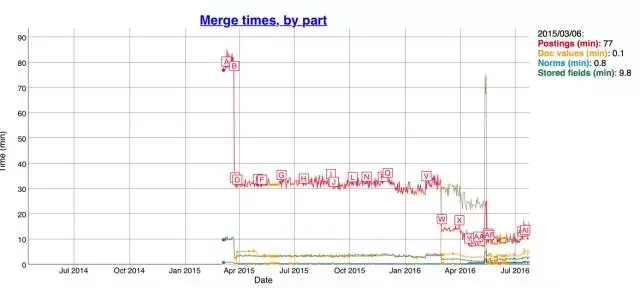
索引小了之后,merge 的时间也响应的减少了,看下图:
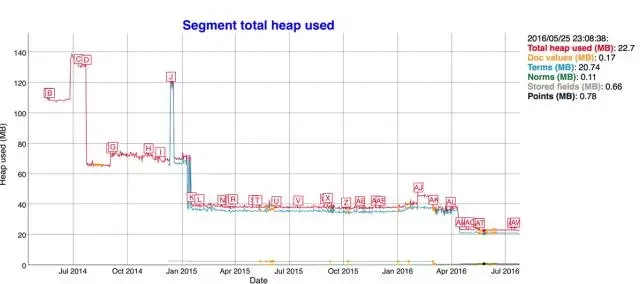
相应的 Java 堆内存占用只原来的一半:
再看看索引的性能,也是飙升:
当然 Lucene6 里面还有很多优化和改进,这里没有一一列举。
我们再看看索引性能方面的其他优化。
ES5.0 在 Internal engine 级别移除了用于避免同一文档并发更新的竞争锁,带来 15%-20% 的性能提升 #18060。
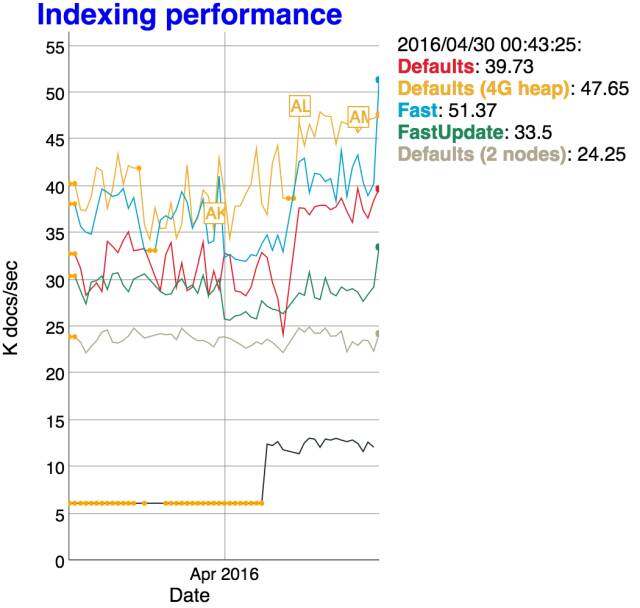
以上截图来自 ES 的每日持续性能监控: https://benchmarks.elastic.co/index.html
另一个和 aggregation 的改进也是非常大,Instant Aggregations。
Elasticsearch 已经在 Shard 层面提供了 Aggregation 缓存,如果你的数据没有变化,ES 能够直接返回上次的缓存结果,
但是有一个场景比较特殊,就是 date histogram,大家 kibana 上面的条件是不是经常设置的相对时间,如:
from:now-30d to:now,好吧,now 是一个变量,每时每刻都在变,所以 query 条件一直在变,缓存也就是没有利用起来。
经过一年时间大量的重构,现在可以做到对查询做到灵活的重写:
首先,now关键字最终会被重写成具体的值;
其次,每个 shard 会根据自己的数据的范围来重写查询为 match\_all或者是match\_none查询,所以现在的查询能够被有效的缓存,并且只有个别数据有变化的 Shard 才需要重新计算,大大提升查询速度。
另外再看看和 Scroll 相关的吧。
现在新增了一个:Sliced Scroll 类型
用过 Scroll 接口吧,很慢?如果你数据量很大,用 Scroll 遍历数据那确实是接受不了,现在 Scroll 接口可以并发来进行数据遍历了。
每个 Scroll 请求,可以分成多个 Slice 请求,可以理解为切片,各 Slice 独立并行,利用 Scroll 重建或者遍历要快很多倍。
看看这个 demo

可以看到两个 scroll 请求,id 分别是 0 和 1,max 是最大可支持的并行任务,可以各自独立进行数据的遍历获取。
我们再看看 es 在查询优化这块做的工作。
新增了一个 Profile API。
https://www.elastic.co/guide/en/elasticsearch/reference/master/search-profile.html#_usage_3
都说要致富先修路,要调优当然需要先监控啦,elasticsearch 在很多层面都提供了 stats 方便你来监控调优,但是还不够,其实很多情况下查询速度慢很大一部分原因是糟糕的查询引起的,玩过 SQL 的人都知道,数据库服务的执行计划(execution plan)非常有用,可以看到那些查询走没走索引和执行时间,用来调优,elasticsearch 现在提供了 Profile API 来进行查询的优化,只需要在查询的时候开启 profile:true 就可以了,一个查询执行过程中的每个组件的性能消耗都能收集到。
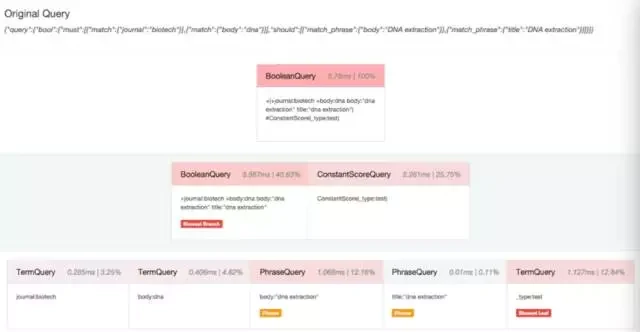
那个子查询耗时多少,占比多少,一目了然。
同时支持 search 和 aggregation 的 profile。
还有一个和翻页相关的问题,就是深度分页,是个老大难的问题,因为需要全局排序(number_of_shards * (from + size)),所以需要消耗大量内存,以前的 es 没有限制,有些同学翻到几千页发现 es 直接内存溢出挂了,后面 elasticsearch 加上了限制,from+size 不能超过 1w 条,并且如果需要深度翻页,建议使用 scroll 来做。
但是 scroll 有几个问题,第一个是没有顺序,直接从底层 segment 进行遍历读取,第二个实时性没法保证,scroll 操作有状态,es 会维持 scroll 请求的上下文一段时间,超时后才释放,另外你在 scroll 过程中对索引数据进行了修改了,这个时候 scroll 接口是拿不到的,灵活性较差,现在有一个新的 Search After 机制,其实和 scroll 类似,也是游标的机制,它的原理是对文档按照多个字段进行排序,然后利用上一个结果的最后一个文档作为起始值,拿 size 个文档,一般我们建议使用 _uid 这个字段,它的值是唯一的 id。
#(Search After
来看一个 Search After 的 demo 吧,比较直观的理解一下:

上面的 demo,search_after 后面带的两个参数,就是 sort 的两个结果。
根据你的排序条件来的,三个排序条件,就传三个参数。
再看看跟索引与分片管理相关的新功能吧。
新增了一个 Shrink API
相信大家都知道 elasticsearch 索引的 shard 数是固定的,设置好了之后不能修改,如果发现 shard 太多或者太少的问题,之前如果要设置 Elasticsearch 的分片数,只能在创建索引的时候设置好,并且数据进来了之后就不能进行修改,如果要修改,只能重建索引。
现在有了 Shrink 接口,它可将分片数进行收缩成它的因数,如之前你是 15 个分片,你可以收缩成 5 个或者 3 个又或者 1 个,那么我们就可以想象成这样一种场景,在写入压力非常大的收集阶段,设置足够多的索引,充分利用 shard 的并行写能力,索引写完之后收缩成更少的 shard,提高查询性能。
这里是一个 API 调用的例子
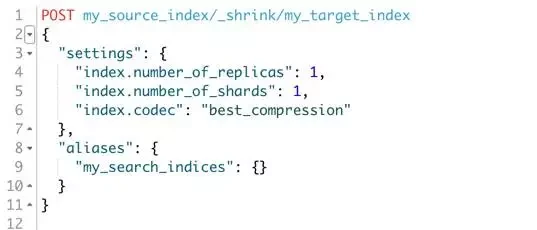
上面的例子对 my_source_index 伸缩成一个分片的 my_targe_index, 使用了最佳压缩。
有人肯定会问慢不慢?非常快! Shrink 的过程会借助操作系统的 Hardlink 进行索引文件的链接,这个操作是非常快的,毫秒级 Shrink 就可收缩完成,当然 windows 不支持 hard link,需要拷贝文件,可能就会很慢了。
再来看另外一个比较有意思的新特性,除了有意思,当然还很强大。
新增了一个 Rollover API。
前面说的这种场景对于日志类的数据非常有用,一般我们按天来对索引进行分割(数据量更大还能进一步拆分),我们以前是在程序里设置一个自动生成索引的模板,大家用过 logstash 应该就记得有这么一个模板 logstash-[YYYY-MM-DD] 这样的模板,现在 es5.0 里面提供了一个更加简单的方式:Rollover API
API 调用方式如下:

从上面可以看到,首先创建一个 logs-0001 的索引,它有一个别名是 logs_write, 然后我们给这个 logs_write 创建了一个 rollover 规则,即这个索引文档不超过 1000 个或者最多保存 7 天的数据,超过会自动切换别名到 logs-0002, 你也可以设置索引的 setting、mapping 等参数, 剩下的 es 会自动帮你处理。这个特性对于存放日志数据的场景是极为友好的。
新增:Reindex。
另外关于索引数据,大家之前经常重建,数据源在各种场景,重建起来很是头痛,那就不得不说说现在新加的 Reindex 接口了,Reindex 可以直接在 Elasticsearch 集群里面对数据进行重建,如果你的 mapping 因为修改而需要重建,又或者索引设置修改需要重建的时候,借助 Reindex 可以很方便的异步进行重建,并且支持跨集群间的数据迁移。
比如按天创建的索引可以定期重建合并到以月为单位的索引里面去。
当然索引里面要启用 _source。
来看看这个 demo 吧,重建过程中,还能对数据就行加工。

再看看跟 Java 开发者最相关的吧,就是 RestClient 了
5.0 里面提供了第一个 Java 原生的 REST 客户端 SDK,相比之前的 TransportClient,版本依赖绑定,集群升级麻烦,不支持跨 Java 版本的调用等问题,新的基于 HTTP 协议的客户端对 Elasticsearch 的依赖解耦,没有 jar 包冲突,提供了集群节点自动发现、日志处理、节点请求失败自动进行请求轮询,充分发挥 Elasticsearch 的高可用能力,并且性能不相上下。 #19055。
然后我们再看看其他的特性吧:
新增了一个 Wait for refresh 功能。
简单来说相当于是提供了文档级别的 Refresh: https://www.elastic.co/guide/en/elasticsearch/reference/master/docs-refresh.html。
索引操作新增 refresh 参数,大家知道 elasticsearch 可以设置 refresh 时间来保证数据的实时性,refresh 时间过于频繁会造成很大的开销,太小会造成数据的延时,之前提供了索引层面的 _refresh 接口,但是这个接口工作在索引层面,我们不建议频繁去调用,如果你有需要修改了某个文档,需要客户端实时可见怎么办?
在 5.0 中,Index、Bulk、Delete、Update 这些数据新增和修改的接口能够在单个文档层面进行 refresh 控制了,有两种方案可选,一种是创建一个很小的段,然后进行刷新保证可见和消耗一定的开销,另外一种是请求等待 es 的定期 refresh 之后再返回。
调用例子:

新增:Ingest Node
https://www.elastic.co/guide/en/elasticsearch/reference/master/ingest.html
再一个比较重要的特性就是 IngestNode 了,大家之前如果需要对数据进行加工,都是在索引之前进行处理,比如 logstash 可以对日志进行结构化和转换,现在直接在 es 就可以处理了,目前 es 提供了一些常用的诸如 convert、grok 之类的处理器,在使用的时候,先定义一个 pipeline 管道,里面设置文档的加工逻辑,在建索引的时候指定 pipeline 名称,那么这个索引就会按照预先定义好的 pipeline 来处理了;
Demo again:

上图首先创建了一个名为 my-pipeline-id 的处理管道,然后接下来的索引操作就可以直接使用这个管道来对 foo 字段进行操作了,上面的例子是设置 foo 字段为 bar 值。
上面的还不太酷,我们再来看另外一个例子,现在有这么一条原始的日志,内容如下:
{
"message": "55.3.244.1 GET /index.html 15824 0.043”
}
google 之后得知其 Grok 的 pattern 如下:)
那么我们使用 Ingest 就可以这么定义一个 pipeline:
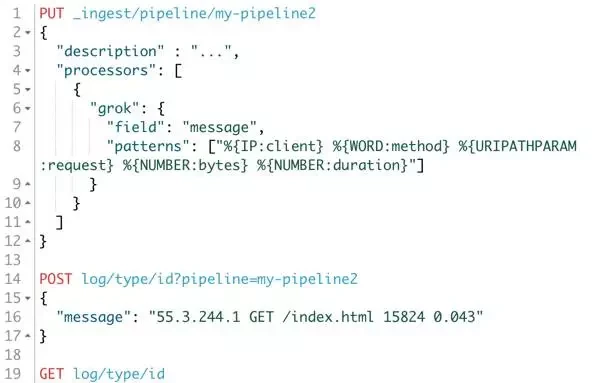
那么通过我们的 pipeline 处理之后的文档长什么样呢,我们获取这个文档的内容看看:
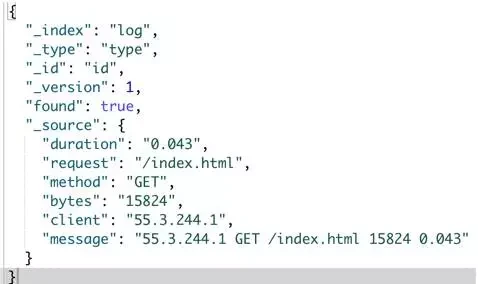
很明显,原始字段 message 被拆分成了更加结构化的对象了。
** 再看看脚本方面的改变 **
** 新增 Painless Scripting**
还记得 Groove 脚本的漏洞吧,Groove 脚本开启之后,如果被人误用可能带来的漏洞,为什么呢,主要是这些外部的脚本引擎太过于强大,什么都能做,用不好或者设置不当就会引起安全风险,基于安全和性能方面,我们自己开发了一个新的脚本引擎,名字就叫 Painless,顾名思义,简单安全,无痛使用,和 Groove 的沙盒机制不一样,Painless 使用白名单来限制函数与字段的访问,针对 es 的场景来进行优化,只做 es 数据的操作,更加轻量级,速度要快好几倍,并且支持 Java 静态类型,语法保持 Groove 类似,还支持 Java 的 lambda 表达式。
我们对比一下性能,看下图
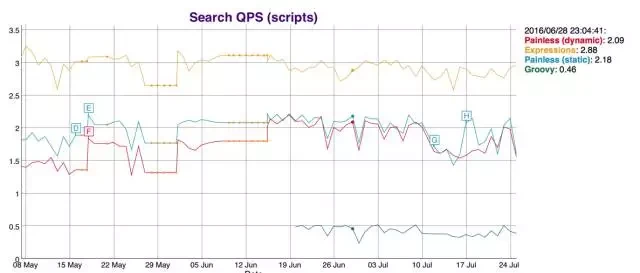
Groovy 是弱弱的绿色的那根。
再看看如何使用:
def first = input.doc.first\_name.0;
def last = input.doc.last\_name.0;
return first + " " + last;
是不是和之前的写法差不多
或者还可以是强类型(10 倍速度于上面的动态类型)
String first = (String)((List)((Map)input.get("doc")).get("first\_name")).get(0);
String last = (String)((List)((Map)input.get("doc")).get("last\_name")).get(0);
return first + " " + last;
脚本可以在很多地方使用,比如搜索自定义评分;更新时对字段进行加工等
如:

** 再来看看基础架构方面的变化 **
** 新增:Task Manager**
这个是 5.0 引入任务调度管理机制,用来做离线任务的管理,比如长时间运行的 reindex 和 update\_by\_query 等都是运行在 TaskManager 机制之上的,并且任务是可管理的,你可以随时 cancel 掉,并且任务状态持久化,支持故障恢复;
** 还新增一个:Depreated logging**
大家在用 ES 的时候,其实有些接口可能以及打上了 Depreated 标签,即废弃了,在将来的某个版本中就会移除,你当前能用是因为一般废弃的接口都不会立即移除,给足够的时间迁移,但是也是需要知道哪些不能用了,要改应用代码了,所以现在有了 Depreated 日志,当打开这个日志之后,你调用的接口如果已经是废弃的接口,就会记录下日志,那么接下来的事情你就知道你应该怎么做了。
** 新增: Cluster allocation explain API**
『谁能给我一个 shard 不能分配的理由』,现在有了,大家如果之前遇到过分片不能正常分配的问题,但是不知道是什么原因,只能尝试手动路由或者重启节点,但是不一定能解决,其实里面有很多原因,现在提供的这个 explain 接口就是告诉你目前为什么不能正常分配的原因,方便你去解决。
** 另外在数据结构这块,新增: half\_float 类型 **
https://www.elastic.co/guide/en/elasticsearch/reference/master/number.html
只使用 16 位 足够满足大部分存储监控数值类型的场景,支持范围:2 负 24 次方 到 65504,但是只占用 float 一半的存储空间。
**Aggregation 新增: Matrix Stats Aggregation #18300**
金融领域非常有用的,可计算多个向量元素协方差矩阵、相关系数矩阵等等
** 另外一个重要的特性:为索引写操作添加顺序号 #10708**
大家知道 es 是在 primary 上写完然后同步写副本,这些请求都是并发的,虽然可以通过 version 来控制冲突,
但是没法保证其他副本的操作顺序,通过写的时候产生顺序号,并且在本地也写入 checkpoint 来记录操作点,
这样在副本恢复的时候也可以知道当前副本的数据位置,而只需要从指定的数据开始恢复就行了,而不是像以前的粗暴的做完整的文件同步,另外这些顺序号也是持久化的,重启后也可以快速恢复副本信息,想想以前的大量无用拷贝吧和来回倒腾数据吧。
**Elasticsearch5.0 其他方面的改进 **
我们再看看 **mapping 这块的改进 ** 吧。
** 引入新的字段类型 Text/Keyword 来替换 String**
以前的 string 类型被分成 Text 和 Keyword 两种类型,keyword 类型的数据只能完全匹配,适合那些不需要分词的数据,
对过滤、聚合非常友好,text 当然就是全文检索需要分词的字段类型了。将类型分开的好处就是使用起来更加简单清晰,以前需要设置 analyzer 和 index,并且有很多都是自定义的分词器,从名称根本看不出来到底分词没有,用起来很麻烦。
另外 string 类型暂时还在的,6.0 会移除。
** 还有关于 Index Settings 的改进 **
Elasticsearch 的配置实在太多,在以前的版本间,还移除过很多无用的配置,经常弄错有没有?
现在,配置验证更加严格和保证原子性,如果其中一项失败,那个整个都会更新请求都会失败,不会一半成功一半失败。下面主要说两点:
1. 设置可以重设会默认值,只需要设置为 `null`即可
2. 获取设置接口新增参数`?include\_defaults`, 可以直接返回所有设置和默认值
** 集群处理的改进: Deleted Index Tombstones**
在以前的 es 版本中,如果你的旧节点包含了部分索引数据,但是这个索引可能后面都已经删掉了,你启动这个节点之后,会把索引重新加到集群中,是不是觉得有点阴魂不散,现在 es5.0 会在集群状态信息里面保留 500 个删除的索引信息,所以如果发现这个索引是已经删除过的就会自动清理,不会再重复加进来了。
文档对象的改进: 字段名重新支持英文句号,再 2.0 的时候移除过 dot 在字段名中的支持,现在问题解决了,又重新支持了。
es 会认为下面两个文档的内容一样:

** 还有其他的一些改进 **
Cluster state 的修改现在会和所有节点进行 ack 确认。
Shard 的一个副本如果失败了,Primary 标记失败的时候会和 Master 节点确认完毕再返回。
使用 UUID 来作为索引的物理的路径名,有很多好处,避免命名的冲突。
\_timestamp 和 \_ttl 已经移除,需要在 Ingest 或者程序端处理。
ES 可直接用 HDFS 来进行备份还原(Snapshot/Restore )了 **\#15191**。
Delete-by-query 和 Update-by-query 重新回到 core,以前是插件,现在可以直接使用了,也是构建在 Reindex 机制之上。
HTTP 请求默认支持压缩,当然 http 调用端需要在 header 信息里面传对应的支持信息。
创建索引不会再让集群变红了,不会因为这个卡死集群了。
默认使用 BM25 评分算法,效果更佳,之前是 TF/IDF。
快照 Snapshots 添加 UUID 解决冲突 **\#18156**。
限制索引请求大小,避免大量并发请求压垮 ES **\#16011。**
限制单个请求的 shards 数量,默认 1000 个 **\#17396。**
移除 site plugins,就是说 head、bigdesk 都不能直接装 es 里面了,不过可以部署独立站点(反正都是静态文件)或开发 kibana 插件 **\#16038**。
允许现有 parent 类型新增 child 类型 **\#17956。**
这个功能对于使用 parent-child 特性的人应该非常有用。
支持分号(;)来分割 url 参数,与符号(&)一样 **\#18175**。
比如下面这个例子:
curl http://localhost:9200/\_cluster/health?level=indices;pretty=true
好吧,貌似很多,其实上面说的还只是众多特性和改进的一部分,es5.0 做了非常非常多工作,本来还打算讲讲 bug 修复的,但是太多了,时间有限,** 一些重要的 bug 在 2.x 都已经第一时间解决了,大家可以查看下面的链接了解更多更详细的更新日志:**
https://www.elastic.co/guide/en/elasticsearch/reference/master/release-notes-5.0.0-alpha1-2x.html
https://www.elastic.co/guide/en/elasticsearch/reference/master/release-notes-5.0.0-alpha1.html
https://www.elastic.co/guide/en/elasticsearch/reference/master/release-notes-5.0.0-alpha2.html
https://www.elastic.co/guide/en/elasticsearch/reference/master/release-notes-5.0.0-alpha3.html
https://www.elastic.co/guide/en/elasticsearch/reference/master/release-notes-5.0.0-alpha4.html
** 下载体验最新的版本 **:https://www.elastic.co/v5
** 升级向导:**https://github.com/elastic/elasticsearch-migration/blob/2.x/README.asciidoc
如果有 es 相关的问题也欢迎前往 **Elastic 中文社区 **:http://elasticsearch.cn
进行交流和讨论,可以加我微信单独探讨,也欢迎上 elasticsearch.cn 发帖讨论,谢谢大家。
**Q&A**
**Q1:** 是否有用 es 做 hbase 的二级索引的
**A1:** 这种案例说实话比较少,因为成本比较高,在两套分布式系统里面做结合,并且要满足足够的性能,有点难度,不建议这样去做。
**Q2:** 批量更新数据会出现少量数据更新不成功
**A2:** 这个首先要看少量失败的原因是什么,es 的返回信息里面会包含具体的信息,如果 json 格式不合法也是会失败的。
**Q3:**ik 插件有没有计划支持同义词,专有名词热更新?对于词库更新比较频繁的应用场景,只能采取全部重新建立索引的方式吗?
**A3:** 同义词有单独的 filter,可以和 ik 结合一起使用的,关于热更新这个确实是需要重建,词库变化之后,分词产生的 term 不一样了,不重建的话,倒排很可能匹配不上,查询会失败。
**Q4:** 老师,你好,我有个问题想咨询一下,我们原来的商品基本数据,商品评价数据,收藏量这些都在 mysql 里,但我们现在想上 es,我们想把商品的基本数据放 es,收藏、评价这些实时数据,还是放 mysql,但做排序功能的时候,会参考一个商品的收藏量,评价量,这时候在还涉及数据分页的情况下,怎么结合 es 和 mysql 的数据进行排序呢?
**A4:** 这个问题得具体看业务场景,如果更新频繁,但是还在 es 承受能力范围和业务响应指标内,可以直接放 es 里面,在 es 里面做排序,如果太大,建议放外部存储,外部存储和 es 的结合方式又有很多种,收藏评价是否真的需要那么实时?另外 es 的评分机制是可以扩展的,在评分阶段使用自定义插件读取外部数据源,进行混合打分也是可行的。
**Q5:** 现在大 agg 查询可以 cancel 吗?
**A5:** 现在还不能。
**Q6:** 有考虑提供 sql 语法查询吗?
**A6:** 目前暂时还没计划。
**Q7:**128g 内存的机器,官方建议机器上放两个 es 实例,目前也是推荐这样做吗?
**A7:** 这个其实看场景的,单台机器上面的索引比较大的话,建议多留一点给操作系统来做缓存,多个实例可以提供足够吞吐。
**Q8:** 请问用于计算 unique count 的算法有变化吗?
**A8:** 有的,elasticsearch 里面叫 cardinality。这里有篇文章:https://www.elastic.co/blog/count-elasticsearch。
**Q9:** 请问在 es5 中,每个服务器有 256G 内存,那每个服务器带的存储多少比较合适?是 24T,48T 还是可以更多?
**A9:** 这个看场景啦,有超过 48T 的。
**Q10:** 请问下 Elastic Stack 是只要安装一次这个就行,还是要像原来 elk 一样,分别安装不同的组件?
**A10:** 安装方式和之前一样的.
**Q11:** 请问 es 中的如何做到按某个字段去重?具体问题是这样的,我们有一个文章索引,其中有 2 亿数据量,每次搜索的结果总是存在大量重复的 title,我们希望在查询时能根据 title 进行去重。也就是 Field Collapsing 特性,官方有一个通过 terms aggregation 进行去重的方案,但效果不是很理想,仍然会有很多重复,我们希望哪怕是按 title 严格相等来去重也可以接受。 另外我们有一个通过 simhash 来去重的思路,就是计算 title 的 simhash,一并存入索引,在搜索阶段通过 simhash 计算相似性,但这需要全量重新计算,数据量太大。所以还是希望能在不动现有索引的情况下,通过某种技巧,实现这个功能。
**A11:** 直接去重,这个目前没有比较好的方案,不过很多变通的做法,首先你的场景需要确认,title 重复是不是不允许的,如果是,那么建索引的时候就可以 hash 掉作为主键,这样就不会有重复的了,如果你觉得原始数据也要,那么索引阶段产生一个独立的去除 title 的索引,来做 join,当然还是要看你业务的场景具体研究。
**Q12:硬件受限的情况下,清理过期数据的策略。**
**A12:** 如果你的数据结构固定,结合 5.0 的 Rollover 接口,估计能够承载的最大索引量,定期检测删索引就行了。
** 讲师介绍:曾勇 (Medcl), Elastic 开发工程师与技术布道师。**
曾勇是 Elasticsearch 国内首批用户,自 2010 年起就开始接触 Elasticsearch 并投入到生产环境中使用,并编写过一系列的中文处理相关的插件,是 Elasticsearch 中文社区发起人,筹办了一系列线上线下的 Elasticsearch 技术分享与交流活动,出于对 Elasticsearch 的喜爱,目前已全职加入 Elasticsearch 项目背后的 Elastic 公司。微信号:medcl123。
- - - - - -
感谢 [杜小芳](http://www.infoq.com/cn/author/%E6%9D%9C%E5%B0%8F%E8%8A%B3) 对本文的审校。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 [editors@cn.infoq.com](mailto:editors@cn.infoq.com)。也欢迎大家通过新浪微博([@InfoQ](http://www.weibo.com/infoqchina),[@丁晓昀](http://weibo.com/u/1451714913)),微信(微信号:[InfoQChina](http://weixin.sogou.com/gzh?openid=oIWsFt0HnZ93MfLi3pW2ggVJFRxY))关注我们。



