本篇文章介绍使用 TensorFlow 的递归神经网络(LSTM)进行序列预测。作者在网上找到的使用 LSTM 模型的案例都是解决自然语言处理的问题,而没有一个是来预测连续值的。
所以呢,这里是基于历史观察数据进行实数序列的预测。传统的神经网络模型并不能解决这种问题,进而开发出递归神经网络模型,递归神经网络模型可以存储历史数据来预测未来的事情。
在这个例子里将预测几个函数:
- 正弦函数:sin
- 同时存在正弦函数和余弦函数:sin 和 cos
- x*sin(x)
首先,建立 LSTM 模型,lstm_model,这个模型有一系列的不同时间步的 lstm 单元(cell),紧跟其后的是稠密层。
def lstm_model(time_steps, rnn_layers, dense_layers=None):
def lstm_cells(layers):
if isinstance(layers[0], dict):
return [tf.nn.rnn_cell.DropoutWrapper(tf.nn.rnn_cell.BasicLSTMCell(layer['steps']), layer['keep_prob'])
if layer.get('keep_prob') else tf.nn.rnn_cell.BasicLSTMCell(layer['steps'])
for layer in layers]
return [tf.nn.rnn_cell.BasicLSTMCell(steps) for steps in layers]
def dnn_layers(input_layers, layers):
if layers and isinstance(layers, dict):
return skflow.ops.dnn(input_layers,
layers['layers'],
activation=layers.get('activation'),
dropout=layers.get('dropout'))
elif layers:
return skflow.ops.dnn(input_layers, layers)
else:
return input_layers
def _lstm_model(X, y):
stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(lstm_cells(rnn_layers))
x_ = skflow.ops.split_squeeze(1, time_steps, X)
output, layers = tf.nn.rnn(stacked_lstm, x_, dtype=dtypes.float32)
output = dnn_layers(output[-1], dense_layers)
return skflow.models.linear_regression(output, y)
return _lstm_model
所建立的模型期望输入数据的维度与(batch size,第一个 lstm cell 的时间步长 time_step,特征数量 num_features)相关。
接下来我们按模型所能接受的数据方式来准备数据。
def rnn_data(data, time_steps, labels=False):
"""
creates new data frame based on previous observation
* example:
l = [1, 2, 3, 4, 5]
time_steps = 2
-> labels == False [[1, 2], [2, 3], [3, 4]]
-> labels == True [2, 3, 4, 5]
"""
rnn_df = []
for i in range(len(data) - time_steps):
if labels:
try:
rnn_df.append(data.iloc[i + time_steps].as_matrix())
except AttributeError:
rnn_df.append(data.iloc[i + time_steps])
else:
data_ = data.iloc[i: i + time_steps].as_matrix()
rnn_df.append(data_ if len(data_.shape) > 1 else [[i] for i in data_])
return np.array(rnn_df)
def split_data(data, val_size=0.1, test_size=0.1):
"""
splits data to training, validation and testing parts
"""
ntest = int(round(len(data) * (1 - test_size)))
nval = int(round(len(data.iloc[:ntest]) * (1 - val_size)))
df_train, df_val, df_test = data.iloc[:nval], data.iloc[nval:ntest], data.iloc[ntest:]
return df_train, df_val, df_test
def prepare_data(data, time_steps, labels=False, val_size=0.1, test_size=0.1):
"""
Given the number of `time_steps` and some data.
prepares training, validation and test data for an lstm cell.
"""
df_train, df_val, df_test = split_data(data, val_size, test_size)
return (rnn_data(df_train, time_steps, labels=labels),
rnn_data(df_val, time_steps, labels=labels),
rnn_data(df_test, time_steps, labels=labels))
def generate_data(fct, x, time_steps, seperate=False):
"""generate data with based on a function fct"""
data = fct(x)
if not isinstance(data, pd.DataFrame):
data = pd.DataFrame(data)
train_x, val_x, test_x = prepare_data(data['a'] if seperate else data, time_steps)
train_y, val_y, test_y = prepare_data(data['b'] if seperate else data, time_steps, labels=True)
return dict(train=train_x, val=val_x, test=test_x), dict(train=train_y, val=val_y, test=test
这将会创建一个数据让模型可以查找过去 time_steps 步来预测数据。比如,LSTM 模型的第一个 cell 是 10 time_steps cell,为了做预测我们需要输入 10 个历史数据点。y 值跟我们想预测的第十个值相关。
现在创建一个基于 LSTM 模型的回归量。
regressor = skflow.TensorFlowEstimator(model_fn=lstm_model(TIMESTEPS, RNN_LAYERS, DENSE_LAYERS),
n_classes=0,
verbose=1,
steps=TRAINING_STEPS,
optimizer='Adagrad',
learning_rate=0.03,
batch_size=BATCH_SIZE)
预测 sin 函数
X, y = generate_data(np.sin, np.linspace(0, 100, 10000), TIMESTEPS, seperate=False)
# create a lstm instance and validation monitor
validation_monitor = skflow.monitors.ValidationMonitor(X['val'], y['val'], n_classes=0,
print_steps=PRINT_STEPS,
early_stopping_rounds=1000,
logdir=LOG_DIR)
regressor.fit(X['train'], y['train'], validation_monitor, logdir=LOG_DIR)
# > last training steps
# Step #9700, epoch #119, avg. train loss: 0.00082, avg. val loss: 0.00084
# Step #9800, epoch #120, avg. train loss: 0.00083, avg. val loss: 0.00082
# Step #9900, epoch #122, avg. train loss: 0.00082, avg. val loss: 0.00082
# Step #10000, epoch #123, avg. train loss: 0.00081, avg. val loss: 0.00081
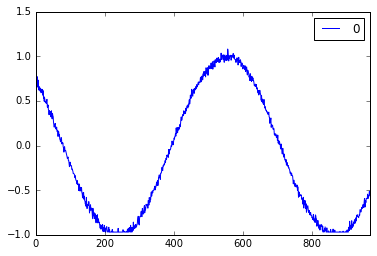
预测测试数据
mse = mean_squared_error(regressor.predict(X['test']), y['test'])
print ("Error: {}".format(mse))
# 0.000776
真实 sin 函数
预测 sin 函数
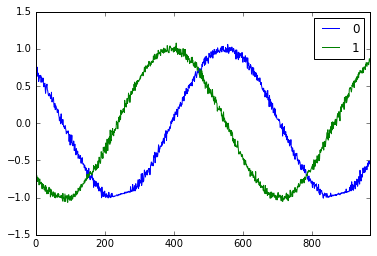
预测 sin 和 cos 混合函数
def sin_cos(x):
return pd.DataFrame(dict(a=np.sin(x), b=np.cos(x)), index=x)
X, y = generate_data(sin_cos, np.linspace(0, 100, 10000), TIMESTEPS, seperate=False)
# create a lstm instance and validation monitor
validation_monitor = skflow.monitors.ValidationMonitor(X['val'], y['val'], n_classes=0,
print_steps=PRINT_STEPS,
early_stopping_rounds=1000,
logdir=LOG_DIR)
regressor.fit(X['train'], y['train'], validation_monitor, logdir=LOG_DIR)
# > last training steps
# Step #9500, epoch #117, avg. train loss: 0.00120, avg. val loss: 0.00118
# Step #9600, epoch #118, avg. train loss: 0.00121, avg. val loss: 0.00118
# Step #9700, epoch #119, avg. train loss: 0.00118, avg. val loss: 0.00118
# Step #9800, epoch #120, avg. train loss: 0.00118, avg. val loss: 0.00116
# Step #9900, epoch #122, avg. train loss: 0.00118, avg. val loss: 0.00115
# Step #10000, epoch #123, avg. train loss: 0.00117, avg. val loss: 0.00115
预测测试数据
mse = mean_squared_error(regressor.predict(X['test']), y['test'])
print ("Error: {}".format(mse))
# 0.001144
真实的 sin_cos 函数
预测的 sin_cos 函数
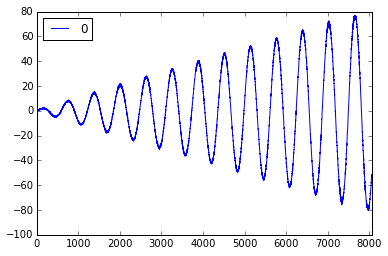
预测 x*sin 函数 ```
def x_sin(x):
return x * np.sin(x)
X, y = generate_data(x_sin, np.linspace(0, 100, 10000), TIMESTEPS, seperate=False)
create a lstm instance and validation monitor
validation_monitor = skflow.monitors.ValidationMonitor(X[‘val’], y[‘val’], n_classes=0,
print_steps=PRINT_STEPS,
early_stopping_rounds=1000,
logdir=LOG_DIR)
regressor.fit(X[‘train’], y[‘train’], validation_monitor, logdir=LOG_DIR)
> last training steps
Step #32500, epoch #401, avg. train loss: 0.48248, avg. val loss: 15.98678
Step #33800, epoch #417, avg. train loss: 0.47391, avg. val loss: 15.92590
Step #35100, epoch #433, avg. train loss: 0.45570, avg. val loss: 15.77346
Step #36400, epoch #449, avg. train loss: 0.45853, avg. val loss: 15.61680
Step #37700, epoch #465, avg. train loss: 0.44212, avg. val loss: 15.48604
Step #39000, epoch #481, avg. train loss: 0.43224, avg. val loss: 15.43947
预测测试数据
mse = mean_squared_error(regressor.predict(X[‘test’]), y[‘test’])
print (“Error: {}”.format(mse))
61.024454351
真实的 x\*sin 函数

预测的 x\*sin 函数
译者信息:侠天,专注于大数据、机器学习和数学相关的内容,并有个人公众号:bigdata\_ny 分享相关技术文章。
英文原文:[Sequence prediction using recurrent neural networks(LSTM) with TensorFlow](http://mourafiq.com/2016/05/15/predicting-sequences-using-rnn-in-tensorflow.html)



