结合去年年底谷歌宣布开源其机器学习开源库 TensorFlow,以及之前 InfoQ 报道的内容来看,数据科学界已经迎来了尝试将 TensorFlow 应用到自己的项目里的机会。
Databricks 公司的 Tim Hunter 通过 Spark 演示了使用 TensorFlow 生成模型选项和一定规模的神经网络处理。Hunter 在描述人工神经网络的时候,将之形容成一个在人脑的视觉皮层里模拟神经元一样,这样的模拟在经过大量充分训练之后,可以被用于处理复杂的输入数据,如图像或音频等等。

Hunter 详细讲述了他是如何把 TensorFlow 运行在各种 Spark 配置上来平衡对超参数的调整的。Hunter 说,目前 TensorFlow 支持 Python 和 C++ 这两种语言,帮助了“自动创建可用于各种形状和尺寸的神经网络的训练算法”,此训练算法是为了训练一个神经网络,用这个受训的神经网络来处理更大规模的数据,同时还能保证处理结果的高精度和最佳运行时性能。
Hunter 提到的一些超参数其实指的是各层神经元数据和学习率,这些数据都是从用于神经网络的训练算法本身分离出来的。
如何更好的调整超参数,让已经给定的算法对运行时间和模型精度产生最佳的影响。超参数的设置是经过相互比对的,目的是把在每一层神经元和错误测试数据里产生的变量关联起来,找到这之间的关系。
学习率是相当关键的点:如果学习率太低,神经网络是不会学习任何东西的。如果学习率太高,只能说明训练过程中可能出现了随机振荡,使得某些配置发生了偏离。
神经网络典型权衡曲线:
- 学习率非常关键,太低学不到东西(高测试误差),太高则训练过程可能随机振荡导致某些配置偏离。
- 神经元的数目对性能没那么重要,大量神经元的网络对学习率更敏感。
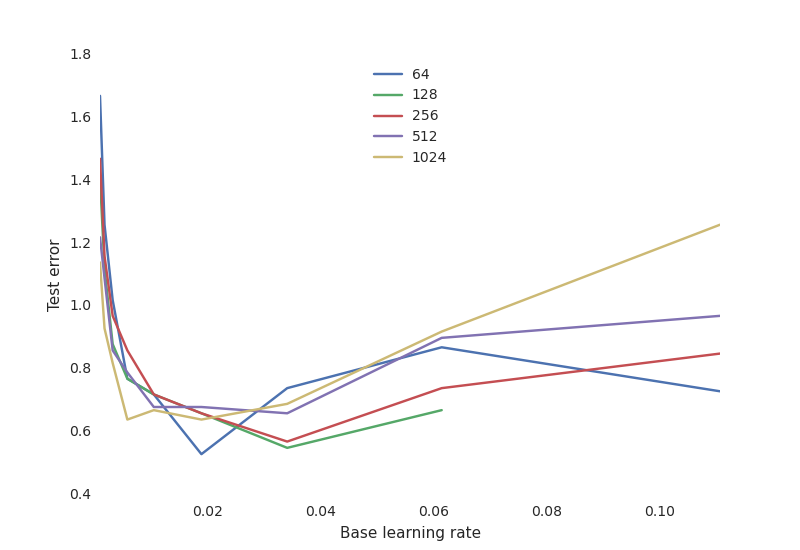
Databricks 建立了一项实验来测量基于 Spark 的 TensorFlow 神经网络训练算法对精度和运行时间性能的影响程度有多大。实验包括一个默认的超参数组,多个超参数的排列,一个测试数据集,一个单一节点,双节点和 13 节点的 Spark 集群。为了找出最优超参数设置,Hunter 使用 Spark 来分布式处理 TensorFlow 生成集,目的是并行测试模型的有效性。对于使用 Spark,Hunter 这样说:
为了传播数据和模型描述等常规元素,然后用容错的方式在一个机器集群里调度个别重复计算。
Hunter 指出,通过和 Spark 集成,在模型精确度和运行时间方面都有所改进:
尽管我们使用的神经网络框架本身只在单节点的时候起作用,但是我们可以使用 Spark 来分配超参数和模型部署。
选择分布式算法大大减少了训练时间,在超参数设置上将精度提高了 34% 以上,这也帮助 Databricks 更好地理解各种超参数的敏感性。它加快了模型验证速度,并证实了这种做法是单节点模型验证速度的七倍。一旦选择最佳的拟合模型和神经网络进行训练,神经网络就会被部署到 Spark 大数据集上运行。
Databricks 并没有谈到具体的硬件实现,但是一些迹象可以从为了这个实验而制作的基于 iPython notebook,以及 Databricks 为客户创建的集群选项里都可以看出来。测量模型选择和神经网络调整能力是通过采用像 Spark 和 TensorFlow 这样的工具而获得的,这可能是对数据科学和机器学习社区的一种恩惠,由于日益普及的云计算和大范围的并行资源在一定程度上帮助工程师们更好的选择实现方式。更多内容可以看看 Tim Hunter 之前写的博客《 Deep Learning with Spark and TensorFlow 》。
参考英文原文: Databricks Integrates Spark and TensorFlow for Deep Learning




