近日,百度位于硅谷的人工智能实验室(SVAIL)开源了其核心的人工智能系统:Warp-CTC,该系统是一种在 CPU 和 GPU 上快速的 CTC 的并行实现。这项举动举动对于促进机器学习、人工智能领域的技术研究与发展与有重要意义。Warp-CTC 可用于解决比如语音识别这样的,将输入序列映射到输出序列的监督问题。基于 Apache 协议,WARP-CTC 的 C 语言库和可选 Torch 绑定都已托管到 GitHub:
https://github.com/baidu-research/warp-ctc
简介
许多现实世界的序列学习任务都要求从嘈杂的、不分段的输入数据中进行标签序列的预测。例如语音识别中,声音信号就被转化成语句或单词。递归神经网络(RNN)对于这样的任务来说是有力的序列训练方法,然而由于 RNN 需要预分段的训练数据,以及需要后处理才能将输出数据转化成标签序列,因此 RNN 的性能受到了限制。Warp-CTC 使用了 Connectionist Temporal Classification 的方法,该方法可以直接训练 RNN 来标记未分段序列,从而规避上述问题。Connectionist Temporal Classification 是一种损失函数,用于执行针对序列数据的监督学习,不需要输入数据和标签之间进行对应。举例来说,CTC 可以用于训练语音识别中端对端系统,而这项技术在百度硅谷人工智能实验室中早已开始使用了。
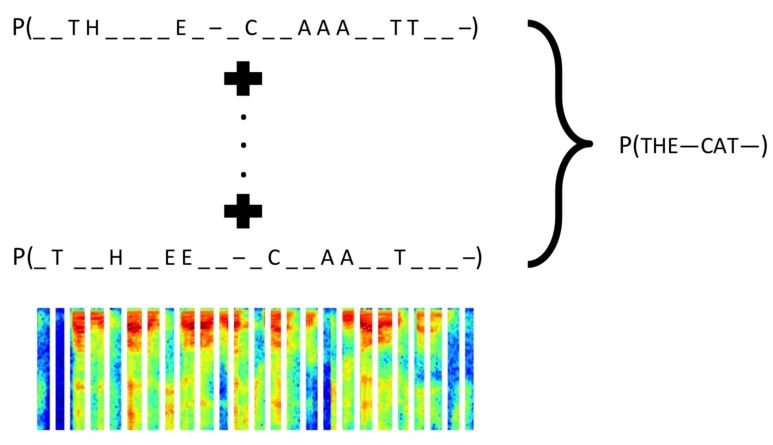
上图显示了 CTC 计算出输出序列“THE CAT”的可能性概率,考虑到由于标签可能延伸若干个输入数据的时间步长而导致标签被复制(用图像底部的光谱来表示),上图结果是所有输入序列可能映射到“THE CAT”上的比对总和。计算这些概率的总和由于涉及到组合学,显然是十分耗费时间和运算成本的,但是 CTC 利用动态编程极大地降低了运算成本。因为 CTC 是可微分的方程,它可用于深度神经网络的标准 SGD 训练。
百度实验室聚焦于扩展递归神经网络,CTC 损失就是一个十分重要的组成部分。为了使整个系统有效运行,百度将整个 CTC 算法并行化处理。该项目包含了百度的高性能 CPU 以及 CTC 损失的 CUDA 版本,并绑定了 Torch。代码库中提供了简单了 C 语言界面,以便于更好地融合深度学习框架。
这一实例通过执行更快地并行调度,极大地改进了性能,改善了训练的可扩展性。对于聚焦于 GPU 的训练管道来说,将数据本地化放置于 GPU 内存中可以用互联带宽增加数据的并行性。
性能
相对于其它公共开放的实例来说,Warp-CTC 要高效得多。该项目在编写时也是尽可能做到数值稳定。该算法对于数值十分敏感,甚至在内存消耗的多得多的单精度浮点运算当中,对于 Log 运算,其数值也是相当稳定。除了机器指令,此外还需要对于多重超越函数的评价。正因为如此,这些 CTC 实例的仅当使用相同方式计算时才能相互比较。
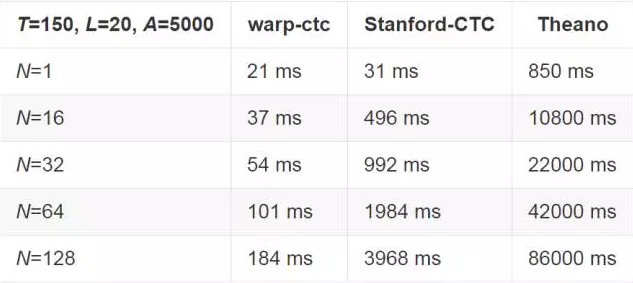
百度将 Warp-CTC 与运行在 Theano 上的 CTC 实例:Eesen,以及仅适用于 Cython CPU 的实例 Stanford-CTC 进行过比较。百度参照了 Theano 在 32 位浮点数字环境下进行 Log 运算,目的是与其它百度相比较的实例进行匹配。他们还将 Stanford-CTC 进行了改良,以便于在 Log 空间下进行运算,但是 Stanford-CTC 也不支持大于 1 的 minibatch。所以百度需要一个训练管道中更加庞大的内存布局,他们假设随着 minibatch 尺寸的增加,内存消耗是线性递增的。
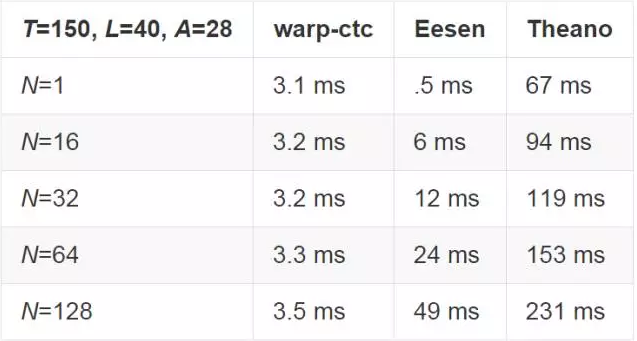
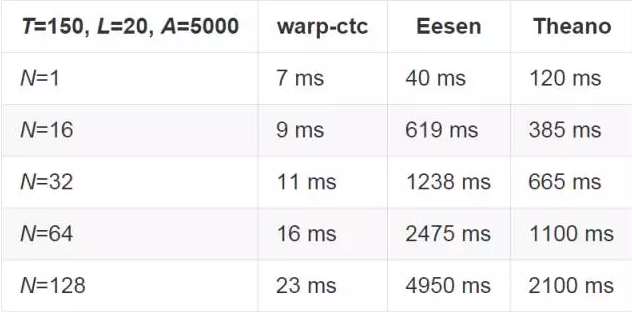
百度将与英文和中文端对端模型(end-to-end model)相关的两个问题尺寸的结果分别展示了出来,在这里 T 代表了输入 CTC 的时间步长的数目,L 代表了每个 example 的长度,A 代表了字母的大小。
在 GPU 上,每 64 个 example 的 minibatch 的表现都在比 Eesen 快 7 倍和快 155 倍、比 Theano 实例快 46 倍和快 68 倍的范围之间波动。
GPU 表现
基于单 NVIDIA Titan X GPU
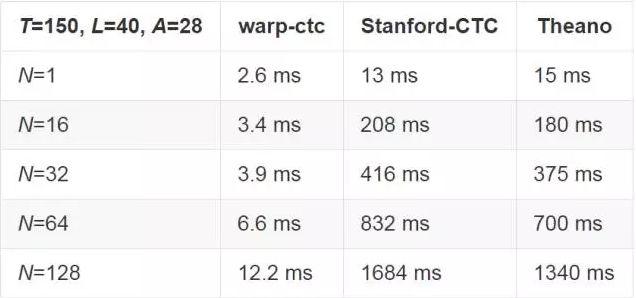
CPU 表现
基于两个 Intel E5-2660 v3 处理器的双卡插槽机器,Warp-CTC 用了 40 个线程去充分利用 CPU 资源,Eesen 没有提供 CPU 实例,Theano 实例没有进行跨多线程并行计算,Stanford-CTC 并未提供跨线程并行计算的机制。
接口
接口在 _include/ctc.h_ 里面,它支持 CPU 或 GPU 执行。如果运行在 CPU 上,你可以指定 OpenMP 并行;或者如果运行在 GPU 上,你可以指定 CUDA 流。百度针对该项目进行了设置,确保代码库不会在内部进行内存分配,目的在于避免由内存分配导致的同步和开销(synchronizations and overheads)。
编译
目前,Warp-CTC 已在 Ubuntu 14.04 和 OSX 10.10 上进行过测试,Windows 目前暂不支持。
首先获取以下代码:
git clone https://github.com/baidu-research/warp-ctc.git
cd warp-ctc
创建一个目录
mkdir build
cd build
如果你安装了非标准的 CUDA,则
export CUDA_BIN_PATH=/path_to_cuda以便于 CMake 可以检测到 CUDA,并且确保 Torch 也被检测到,确保 _th_ 在 _$PATH_ 里面。
运行 cmake 并创建
cmake ../
make
C 代码库和 Torch 共享库会随着测试的可执行文件一同被创建。如果 CUDA 被检测到,那么 _test_gpu_ 就会被创建;_test_cpu_ 无论何种情况都会被创建。
测试
为了运行该项测试,对于 OSX 系统来说,百度确保了 CUDA 库在 _LD_LIBRARY_PATH (DYLD_LIBRARY_PATH_。Torch 测试必须从 _torch_binding/tests/_ 库中运行。
Torch 安装
luarocks make torch_binding/rocks/warp-ctc-scm-1.rockspec我们也可以不克隆存储库来进行安装。
luarocks install http://raw.githubusercontent.com/baidu-research/warp-ctc/master/torch_binding/rocks/warp-ctc-scm-1.rockspec




