现在越来越多的银行业务依赖大数据和物联网基础设施,比如,移动支付、网上银行和智能售货机。但在这些交易过程中存在大量的个人敏感的身份信息需要保护。大数据安全是一个极大挑战的问题,因为作弊者在不断的寻求新方法来获取到有价值的数据。为了防止这些坏家伙,人们需要不断的去设计和发布新的大规模预测模型来预测作弊者的行为。不光银行需要大数据安全保护,任何含有对个人用户信息 personally identifiable information (PII) 处理的商业交易都要做好保护,比如,医疗机构和保险业。
最近有好消息称,有越来越多的机器学习的专家、新的技术和工具来提供有效的分析模型,能够鉴别潜在的欺诈交易和钓鱼式攻击。但不是所有公司都拥有机器学习专家来做这方面的工作,因此这些公司就需要从外面请一些专家来建立有效的模型来抵制作弊者。与此同时,他们又不想自己用户的信息让其他公司知道。通过匿名用户个人信息 PII 还保证不了这一点。那有没有一种较好的方法能够既利用外部力量而又不暴露本公司的敏感的数据呢?
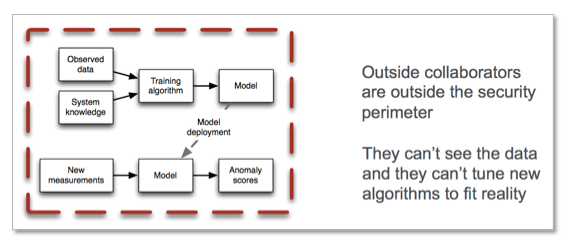
图一
在纽约最近的一次大数据会议上,大数据公司 MapR 的首席架构师 Ted Dunning 发表了一种新方法来解决上述问题。
找出被盗商家
现在一个新的趋势是:作弊者通过成千上万的用户盗取个人信息来进行许多小批量的欺诈交易。这样他们可以在很短的时间里盗取百万美元 / 英镑 / 欧元,通过被盗的商家或者网站来获取大量的顾客的金融信息。作弊者不是偷一张信用卡然后去购买大宗商品,因为这种行为容易被现在的安全软件探测到,而是通过欺骗交易来进行大批量的信用卡交易。这些小额购买常常被用户忽略,但是恰恰会被不良作弊者利用。
为了应对这种潜在的通过被盗商家来进行盗窃的行为,一家大型金融机构采用大数据公司 MapR 的技术来构建新的模型来检测这种分布式攻击。他们的目标是改善自己的欺诈检测的能力:a) 探测出更多的可疑事件,b) 更及时的检测,在出现严重的影响之前尽可能的快的去关闭受影响的账户。
银行有海量的个人交易行为数据,Ted 的方法是把银行的每个顾客的交易数据按时间序列转换,在商家出现被盗之前找出来。他采用的相似估计的方法把每个被盗商家的特征点提取出来,然后进行打分。但问题在于即使是出于打击盗取者,银行也不太愿意把敏感的数据分享出来。
为了克服这个问题,Ted 写了一个可根据个人需求定制的样本数据生成的代码 log-synth ,并开源在 Github 上。通过 log-synth 生成被盗过的用户历史数据模拟来找出被盗的特征。在模拟数据实验中,被盗商家有较高的打分。
构建好探测模型,并进行参数调优,然后将这个模型应用到真实的交易数据。真实的数据分析更令人振奋,一个商家打分超过 80 分的 (见图 2),经银行核实发现这个商家的确存在大量的数据泄露。
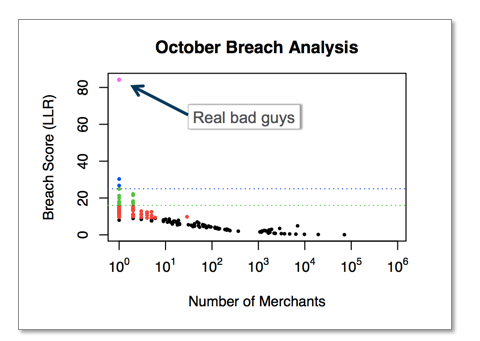
图 2 通过模拟数据构建的模型运用到真实数据中的情况
更好的数据模拟的方法
使用人为生成的数据来进行构建模型并不新鲜,但是这种方法却经常被人忽视。Ted 发现,想精确模拟真实世界的行为特征是非常难的一件事,而通过人为生成的数据就可以很好的构建好的模型,这样更快更容易。
这种方法不仅仅用于欺诈检测,也可以用于其它真实的情况。具体怎样使用开源 log-synth,在这里由于篇幅限制就不再细激昂,感兴趣的可以去看 Ted Dunning 和 Ellen Friedman 写的书《Sharing Big Data Safely: Managing Data Security》,可免费下载。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




