在美国最大的点评网站 Yelp 上,许多用户都会使用高级搜索过滤器准确地查找某个地方。像“价格”、“距离”、“评级”这样的过滤器很容易使用,但像“户外座位”或“现场音乐”这种更专门的过滤器就有些难用了。因此,他们需要寻找一种方法,在不影响用户体验的情况下,使用户更方便地使用高级过滤器。Yelp 数据挖掘工程师 Ray M. G. 近日撰文介绍了他们如何使用数据驱动搜索过滤器。
在设计新的过滤器之前,他们需要通过挖掘数据更好地理解用户如何使用过滤器。他们发现,用户选择的过滤器很大程度上取决于他们使用的查询词。而且,大部分用户都只使用一个过滤器。他们由此得出,他们需要一种简单的设计,只提供少数几个同查询词相关的过滤器。以下是设计变化前后的界面:
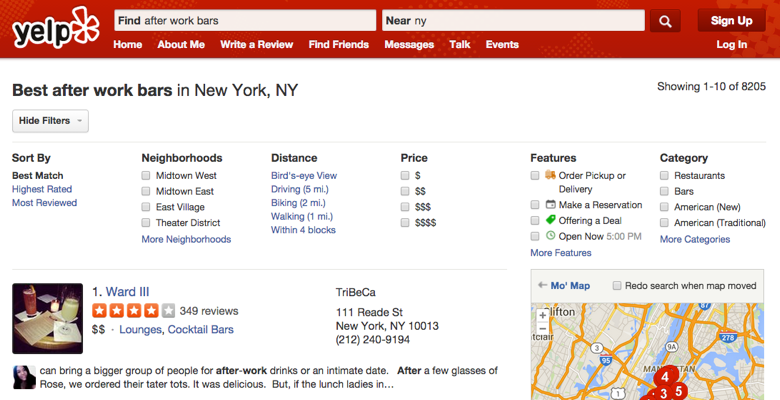
图一:旧搜索界面
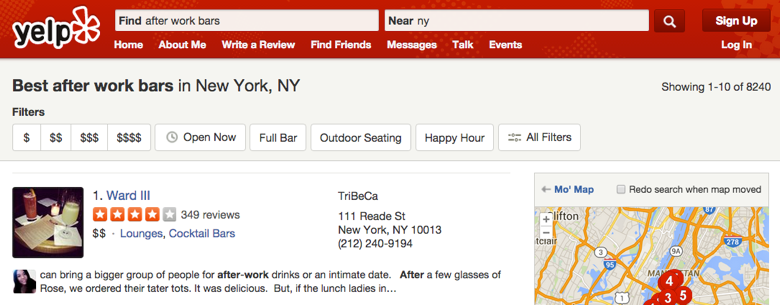
图二:新搜索界面
可以看出,新搜索界面隐藏了相关度较低的过滤器,极大地节省了页面空间。而且,如果 Yelp 展示的过滤器不能满足用户需求,那么他们仍然可以点击“所有过滤器”来选择需要的过滤器。
为了支撑这种变化,他们需要构建一个模型。该模型可以接受一组信息特征(如查询、日期 & 时间、位置、个人偏好及其他特征),并给出向客户展示哪些过滤器的建议。查询字符串是最为重要的特征,但查询文本是一种稀疏 & 长尾特征,且基数很大,很难为模型所用。他们希望可以构建一个函数,将查询文本映射成一个可以反映查询与特定过滤器相关度的数值。下图是他们构建的语言模型:

可以将该模型看作一个函数,输入一个单词序列,输出单词序列的概率估计。该模型是贝叶斯定理的一个简单应用。在查询一定的情况下,它可以计算出所有过滤器的先验概率 P(filter|query)。可以看出,对于查询词“业余酒吧(after work bars)”,过滤器“欢乐时光”和“户外座位”的概率值为正,说明它们与查询相关,而过滤器“适合早午餐”和“适合孩子”被认为是不相关的。
为了测试该模型的有效性,他们使用了如下两个指标:
- 过滤器使用率:由于 Yelp 搜索过滤器可以帮助用户更快地发现相关内容,所以他们希望该模型可以提高过滤器使用率;
- 搜索质量:他们希望该模型推荐的过滤器有助于提供相关度更高的内容,提升搜索体验。
测试发现,过滤器使用率较之前提高了 20%,像“现在开放”、“快乐时光”这样的过滤器使用次数明显增加,而其他过滤器的使用次数稍微减少。在搜索质量方面,他们通过连续的观察发现,在测试人群中,搜索会话 CRT(Click Through Rate,点进率)稳步上升。点击数非常容易度量,但也是一个很容易产生迷惑性的指标,因为用户点击搜索结果,并不能让被点击的结果相关。因此,他们还辅以其他指标,比如用户找到相关结果所用的时间。按照 Ray 的说法,重新设计的搜索过滤器界面得到了一致好评,效果超出预期。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




