为了在 Pin 上展示有用的信息(如产品价格、位置数据)、做出更好的推荐及打击垃圾邮件,Pinterest 需要充分利用Pin 链接的Web 页面中的内容。除了要抓取、存储及处理页面内容外,还要低延迟地向Pinner 提供处理过的内容。为了满足这些需求,他们构建了爬虫框架Aragog,用于处理数以十亿计的URL。近日,Pinterest 核心基础设施团队工程师 Varun Sharma撰文介绍了该框架。
他们在构建 Aragog 时重点考虑了以下三个方面的问题:
- URL“标准化 / 规范化(Normalization/canonicalization)”:同样的 URL 可以表示成许多不同的形式,多个不同的 URL 可能会重定向到同一个 URL。URL 标准化 / 规范化的目标就是消除重复,减少数据量。
- 数据抓取礼仪:限定抓取频率,尊重 robots.txt 所设定的规则。
- URL 数据建模:存储从单个 URL 中提取的多段元数据,或者存储及更新与单个 URL 相关的入链和出链。
重要通知:接下来 InfoQ 将会选择性地将部分优秀内容首发在微信公众号中,欢迎关注 InfoQ 微信公众号第一时间阅读精品内容。

如下图所示,Aragog 包含两个服务: Aragog Fetcher 会将 URL 规范化,并按照限定频率抓取 Web 页面; Aragog UrlStore 则负责存储和提供与 URL 相关的元数据。
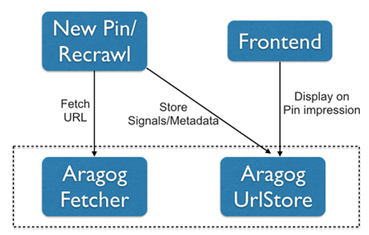
Aragog Fetcher
Aragog Fetcher 是一个 Thrift 服务。它会发出一个 HTTP 请求,并返回一个封装了页面内容、HTTP 头、抓取延迟、重定向链等数据的 Thrift 结构。为了实现礼貌抓取,Aragog Fetcher 会将特定域名的 robots.txt 文件内容缓存 7 天,并严格按照其中的规则进行抓取。此外,Aragog Fetcher 会使用 URL 域名调用“频率限制器(rate limiter)”获取允许的抓取频率。该限制器将单个域名的最大抓取频率限定为 10QPS。需要的话,可以通过配置管理系统修改这一限制。
Aragog UrlStore
Rich Pin 的数据即是由 Aragog UrlStore 提供的。Aragog UrlStore 存储着页面内容本身、页面中提取的半结构化数据及 Web 图元数据(如入链 / 出链),其设计主要遵循如下两个目标:
- 为整个组织提供所有 URL 元数据的一站式服务;
- 以可以接受的延迟为 Pinterest 全部在线读流量以及离线处理系统的读 - 写流量提供服务。
为此,他们在延迟、稳定性和一致性之间进行了权衡。Varun 举了两个例子。
关于页面内容
他们会存储 Web 页面的全部内容。这些数据检索次数少,而且仅用于离线处理管道。因此,他们选择将这些数据存储在 S3 上。每个 Web 页面都作为一个 S3 文件单独存储。他们以 URL 散列值作为 Web 页面的键,但发现,当许多键的前缀都一样时,会导致 S3 集群中的单台机器过载,降低了 S3 bucket 中部分键的性能。
关于 Pin 元数据
Aragog UrlStore 采用了一种灵活的数据模型表示 URL 元数据,其中包含一个字段名和值的映射。例如,一个产品 Pin 可能有一个“product_name”字段和一个“price”字段。在大多数情况下,一个 URL 的元数据由离线处理系统增量更新。
考虑到 URL 元数据访问要求低延迟,而 URL 入链 / 出链非常适合用图模型表示,他们选择使用 Zen (基于 Hbase)作为底层存储系统。Zen 是 Pinterest 的图存储服务,允许定义节点及连接这些节点的边。Zen 的属性用于存储节点元数据,而边用于为入链 / 出链建模。Zen 会在节点和边上创建索引,提供快速高效的 CRUD 操作。
Aragog 已经成为 Pinterest 的一个基础设施,许多管道都用它获取和处理数据及提供 URL 内容。目前,Aragog 每天获取数以百万计的 URL,并提供数以十亿计的在线 URL 请求。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




