2015 年,将 Hadoop 的计算和存储分开成为一个重要的 Hadoop 主题。大数据解决方案提供商 BlueData 今年发表过多篇关于这个主题的文章。来自Gartner 的 Merv Adrian 年初也在 Twitter 上表示,该主题已经成为业内的一个主要议题。近日,BlueData 副总裁 Anant Chintamaneni 回顾了他与EMC 大数据解决方案首席技术官 Chris Harrold 就此议题举办的网络研讨会的内容。
从众心理导致人们将雅虎、Facebook 或 LinkedIn 等早期大数据采用者的大数据实现方式视为实现大数据的唯一方式。大数据生态系统使得 Hadoop 成为下述内容的代名词:
- 一大堆装有 Hadoop 的专用物理服务器;
- Hadoop 的计算和存储位于相同的硬件机器上;
- Hadoop 需要使用直连式存储(DAS)
Anant 认为,现在该废弃这些原则了。他给出了一种更好的实现大数据的方式,如下图所示:

新方法的指导思想主要有以下几项内容:
- Hadoop 可以运行在容器或虚拟机上,即可以使用虚拟机或容器作为Hadoop 节点。这种软件定义的基础设施可以提供干净的环境,保证部署的可预见性,而且交付速度更快,成本更低。在研讨会上,Chris 曾着重说明了 Adobe 的虚拟化 Hadoop 部署。借助虚拟化,他们可以快速增加 Hadoop 的工作节点。另外,所有 Hadoop 供应商提供的“快速入门”选项都是在虚拟机或容器上运行 Hadoop。Netflix 已经基于虚拟化 Hadoop 集群构建出了出色的服务。
- “数据本地化(data locality)”的概念已过时。数据本地化妨碍了企业采用 Hadoop,因为将 TB 级的数据复制到物理服务器,然后在每次有服务器宕机的时候进行数据平衡 / 再平衡,操作非常复杂,成本非常高昂。集群规模越大,情况越糟。像雅虎这样的互联网巨头之所以会那样做,是受以前的网络带宽所限。而现在,10Gbps 的网络也已很常见。将 Hadoop 的计算和存储分开还可以简化操作,用户可以分别扩展和管理计算和存储系统。另外,还有一个事实,就是在许多常见的 Hadoop 场景中,即使计算和存储在一起,Hadoop 任务也无法受益于数据本地化。
- HDFS 并不需要本地磁盘,即 Hadoop 不需要本地直连式存储(DAS)。HDFS 更多的是一种分布式文件系统协议,在本地磁盘上运行 HDFS 只是其中的一种实现方式。现如今,许多公司都拥有 TB 级的数据,且数据来源多样(音频、视频、文本等)。这些数据存储在共享的存储系统中,如 EMC Isilon 。BlueData 和 EMC Isilon 提供了 HDFS 接口,允许将共享存储中的数据提供给 Hadoop 计算过程,而不需要复制数据。
Anant 用 BlueData 一个客户的测试数据说明了新方法所带来的性能上的提升。图一是本地虚拟化 Hadoop 集群与物理 Hadoop 集群的对比:
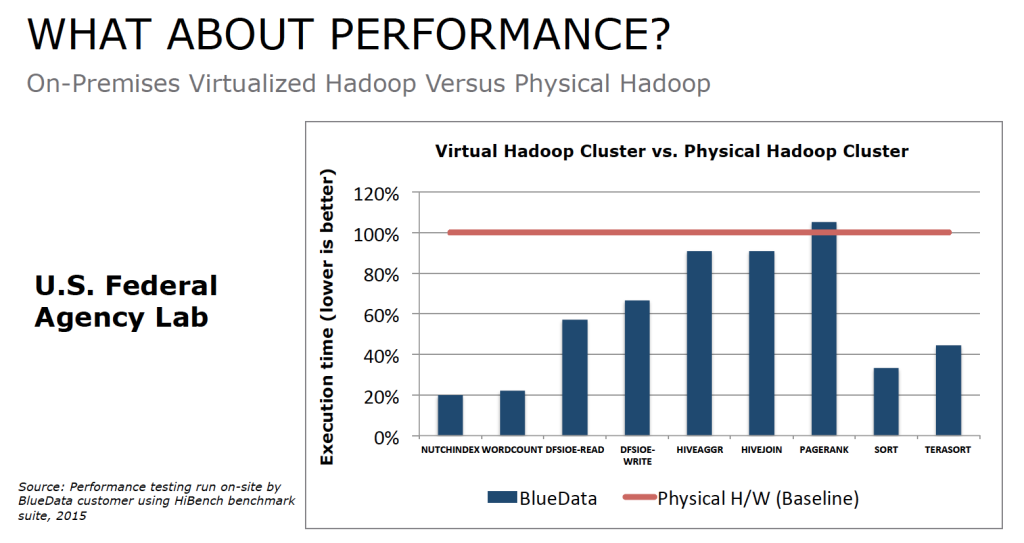
(图一)
可以看出,虚拟化 Hadoop 集群的性能比得上或超过了物理 Hadoop 集群的性能。图二比较了使用共享存储和 DAS 的虚拟化 Hadoop 集群:
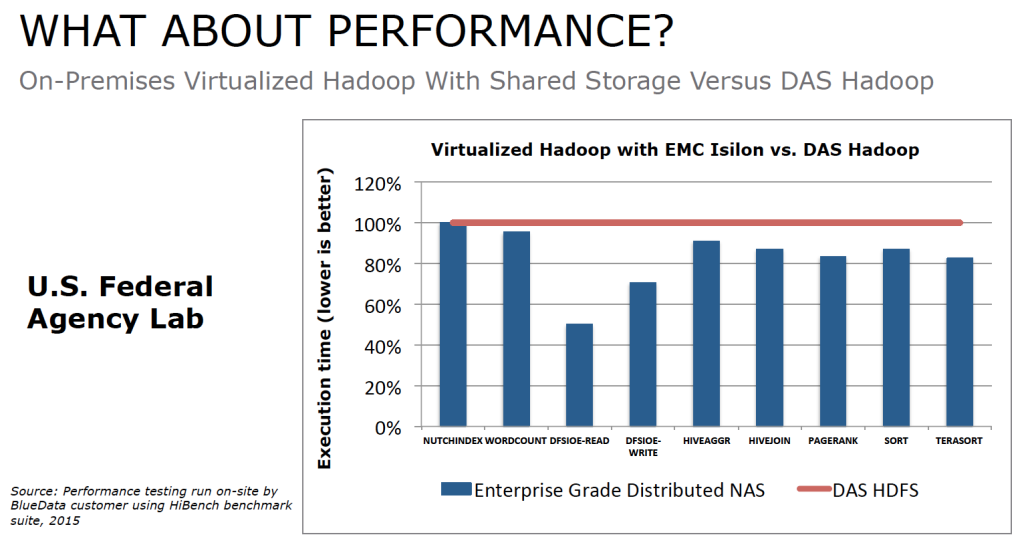
(图二)
可以看出,企业级 NFS 的性能要高于基于 DAS 的 HDFS 系统。
最后,Anant 将网络研讨会的共识总结为以下几点:
- 大数据是一个旅程:基础设施要经得起未来的挑战
- 计算和存储分开可以为所有的大数据涉众提供更大的灵活性
- 不要根据“数据本地化”做大数据基础设施的决策
Anant 期待更多的大数据部署使用共享存储,更多的部署使用容器和虚拟机,更多的企业将 Hadoop 的计算和存储分开。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




