情感分析是自然语言处理(NLP)、文本分析和计算语言学中的一个挑战性问题。一般意义上,情感分析主要是分析用户对于各种对象或问题的意见。它最初是利用长文本(如信件、电子邮件等)来进行分析。随着互联网的发展,像 microbloging 网站、论坛和社交网络等互联网应用爆发式增长,情感分析也越来越受到重视。用户使用这些应用进行的各种交互行为(分享、评论、推荐、交友等)产生了大量的数据,被称为用户产生内容,这些数据蕴含着大量的信息,反映了用户的内在行为规律。庞大的数据量要求使用自动化技术来进行挖掘和分析。目前,利用微博数据进行情感分析是一项挑战性的工作,已有的工作主要采用了词法分析方法和机器学习方法,以及两种方法的融合。
背景
根据分析的载体不同,情感分析涉及到很多的主题,包括针对电影评论、商品评论,以及新闻和博客等的情感分析。在本文中,主要介绍针对 Twitter 内容的情感分析方法。对情感分析的研究到目前为止主要集中在两个方面:识别给定的文本实体是主观的还是客观的,以及识别主观的文本的极性。大多数情感分析研究都使用机器学习方法。
在情感分析领域,文本可以划分为积极的或消极的类,或者多种类别,即积极、消极和中性(或不相关)。针对 Twitter 内容的情感分析技术可以分为:
- 词法分析
- 基于机器学习的分析
- 混合分析
词法分析
这种技术主要使用了一个由预标记词汇组成的字典。输入文本通过词法分析器被转换为一个个单词。将每一个新的单词与字典中的词汇进行匹配。如果有一个积极的匹配,分数加到输入文本的分数总池中。例如,如果“戏剧性”在字典中是一个积极的匹配,然后文本的总分数会递增。相反,如果有一个消极的匹配,输入文本的总分数会减少。虽然这项技术本质上感觉有些业余,但已被证明是有价值的。词法分析技术的工作方式如下图。
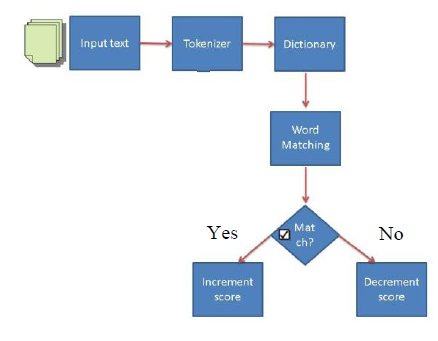
文本的分类取决于文本的总得分。目前有大量的工作致力于度量词法信息的有效性。对单个短语,通过手动标记词汇(仅仅包含形容词)的方式,大概能达到 80%的准确率,这是由评价文本的主观性所决定的。有研究者将同样的方法用于电影评论的数据中,准确率仅仅为 62%。除了手动标记词汇的方法,还有研究者利用互联网搜索引擎标记词汇的极性。他们使用两个 AltaVista 搜索引擎进行查询:目标词汇 +“good”和目标词汇 +“bad”,最后的得分根据搜索的结果的数量进行统计,准确率从 62% 提高到了 65%。后来还有研究者使用了 WordNet 数据库,他们通过在 WordNet pyramid 中计算目标词汇与“good”和“bad”之间的最小路径距离(Minimum Path Distance,MPD),并将 MPD 转换为分数值,存储在词汇字典中,这种方法的准确率可以达到 64%。还有研究者通过简单地从消极词汇集合中去除积极词汇,来评价语义差距,得到了 82%的准确度。词法分析也存在一个不足:其性能(时间复杂度和准确率)会随着字典大小(词汇的数量)的增加迅速下降。
基于机器学习的分析
机器学习技术由于其高的适应性和准确性受到了越来越多的关注。在情感分析中,主要使用的是监督学习方法。它可以分为三个阶段:数据收集、预处理、训练分类。在训练过程中,需要提供一个标记语料库作为训练数据。分类器使用一系列特征向量对目标数据进行分类。在机器学习技术中,决定分类器准确率的关键是合适的特征选择。通常来说,unigram(单个短语),bigrams(两个连续的短语),trigrams(三个连续的短语)都可以被选为特征向量。当然还有其他的一些特征,如积极词汇的数量,消极词汇的数量,文档的长度,支持向量机(SVM),和朴素贝叶斯(NB)算法等。取决于所选择的各种特征的组合,精度可以达到从 63%至 80%。下图是基于机器学习的分析所涉及到的主要步骤:
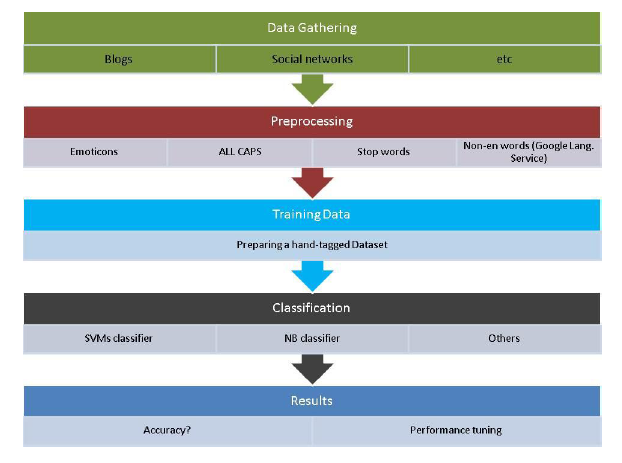
同时,机器学习技术也面临很多挑战:分类器的设计、训练的数据的获取、对一些未见过的短语的正确解释。相比词法分析方法,它在字典大小呈指数倍增长的时候依然工作得很好。
混合分析
情感分析研究的进步吸引大量研究者开始探讨将两种方法进行组合的可能性,既可以利用机器学习方法的高准确性,又可以利用词法分析方法的快速特点。有研究者利用由两个词组成的词汇和一个未标记的数据,将这些由两个词组成的词汇划分为积极的和消极的类。利用被选择的词汇集合中的所有单词产生一些伪文件。然后计算伪文件与未标记文件之间的余弦相似度。根据相似性量度,该文件被划分为积极的或消极的情感。这些训练数据集然后被送入朴素贝叶斯分类器进行训练。
有研究者使用背景词法信息作为单词类关联,提出了一种统一的框架,设计了一个 Polling 多项式分类器(PMC)(也称为多项式朴素贝叶斯),在训练中融入了手动标记数据。他们声称利用词法知识后性能得到了提高。
比较
在文献 [ 1 ] 中,研究者在电影评论及推荐、新闻评论领域相关的用户微博数据上进行测试,通过对所有的方法进行比较表明机器学习方法可以得到最好的结果,最差的是词法分析方法。但是,如果没有找到合适的分类器,机器学习方法可能会导致非常糟糕的结果。
出于分类器的训练目的,用户可以使用公开可用的数据集,包括:Cornel 电影评论集,通用询价形容词列表,雅虎网络搜索 API,WordNet Java API,WEKA M.L. Java API(仅适用于机器学习目的),SVM-light ML(M.L. 分类器)等。
文献 1
[ 1 ] R. Prabowo and M. Thelwall. Sentiment analysis: A combined approach. Journal of In-formatics (2009) 143-157
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。





{kind=link}
{kind=link}