在 3 月 21 日由 OpenStack 中国用户组主办的 OpenStack Meetup 活动上,UnitedStack 运维团队负责人,同时也是 OpenStack 社区核心开发者的余兴超分享了多年运维 OpenStack 服务的经验和体会。本文根据余兴超演讲的部分内容整理而成,主要包含 OpenStack 在实际服务运维工作中所遇到的具体挑战,以及统一运维的具体策略。
持续集成(CI)和持续交付(CD)是 OpenStack 运维工程师们所面临的两大课题。其中,持续集成是保证整个研发团队的开发进度保持同步,其目的是消除由于集成问题引起的项目延期;持续集成的最后一公里是交付,所谓交付,也就是将代码最终部署到线上环境,转变成生产环境中提供服务的软件。
六大挑战困扰OpenStack持续运维
要实现持续集成和持续交付的目标对于 UnitedStack 的运维团队是一项异常艰巨的任务。具体说来,运维的挑战来自以下六个方面。
- 项目和服务众多的问题。这其中包含了 Nova(计算)、Glance(镜像)、KeyStone(识别)、Neutron(网络)等常规的 OpenStack 的服务组件,也有 UnitedStack 内部开发的一系列服务,例如 Placebo(面板)、Kiki(消息通知)、Ticket(计费)、Gringotts(API 中间件 )等等。另外,还需要管理一系列的基础服务,例如消息队列、数据库、负载均衡、高可用软件等。
- 服务软件包的依赖复杂度。比方说,计算服务 Nova 的软件包的线上运营需要安装 13 个相关的 Nova 包、163 个相关依赖包,同时还要升级 9 个相关的依赖包。大多数依赖包都有非常严格的版本要求。
- 配置文件和选择繁多。还是以 Nova 为例,仅 Nova.conf 就有 835 个配置选项,算上注释,大约有 1700 多行。
- OpenStack 灵活的架构带来的运维挑战。OpenStack 可以将某些功能和后端驱动抽象为独立的 Filter 和 Plugin。比方说,你可以选择用 Nova-Network 还是 Neutron 来构建 SDN,可以选择用 Ceph 还是 Sheepdog 作为 Cinder backend,还可以选择 KVM 还是 Xen 作为 Nova-compute 的 Hypervisor。
- 私有 Patch 太多。事实上,UnitedStack 的服务运维团队对于私有 Patch 的态度是非常谨慎的。我们会尽量把 Patch 提交到社区,即便未提交的社区,也会尽可能地不去破坏 Patch 的代码逻辑,即便不得不进行修改,也会尽可能地保持代码的可维护性。但即便如何,运维的难度依然很大,目前 UnitedStack 团队运维的很多服务的私有 Patch 都超过了 100 个,例如 Keystone、Ceph 和 Neutron。
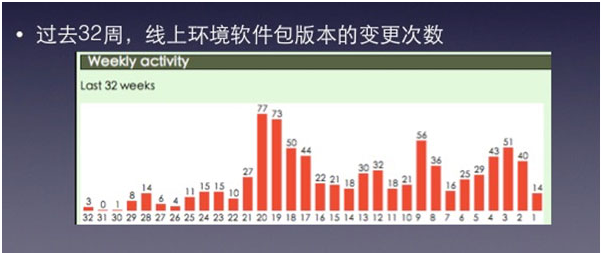
- 这些坑都趟过了,等着你的还有 OpenStack 各个项目版本频繁变更带来的运维陷阱。这也是由社区和我们自己的研发结构所决定的。大家都知道,每隔 6 个月,OpenStack 社区的各个项目都会发布新的版本。UnitedStack 的服务版本更新则穿插其间,过去的半年时间,我们每个月平均上线 2.6 个新项目。回顾 UnitedStack 过去 32 周的线上环境软件包版本的变更次数,我们发现,版本变更始在过去的半年多的时间里保持了相当高的变更频率,其中由两周的变更次数超过了 70 次。
**“四个统一”**实现运维自动化
越是复杂和多变的系统,就越需要统一的运维规范和框架。而这里说的统一是指统一的框架、统一的工具、统一的处理流程,以及统一的接口。
- 统一的框架
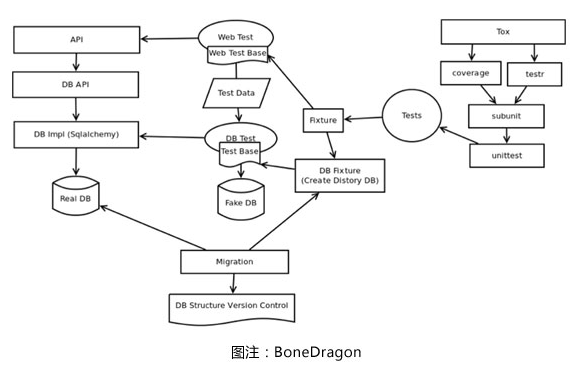
在 UOS 1.0 版本开发时,UnitedStack 活力四射的工程师们开发了很多项目,编程语言也是多种多样,Java、Python、Ruby 都有,持久化后端有的用 SQL,有的用 NoSQL,消息队列有的用 RabbitMQ,有的用 ZeroMQ。我们的运维团队很快就 Hold 不住这些大神们了。我们也曾经尝试过制定相关的开发规定,但是无法起到实际的约束作用。最后,还是由运维团队牵头,制定了名为 BoneDragon 的统一的开发框架。这一框架是用 Python 语言编写的,可以一键生成项目的基础开发框架,包含标准化的 API 模块、数据库模块和测试用例。BoneDragon 框架已经开源,并且发布到 GitHub 上。
2. 统一的工具 UnitedStack 已经建立了一套由统一的工具构成的持续交付系统工作流程。统一的工具组由 PSRForge(包管理系统)、Puppet(配置管理系统)、Ansible (任务编排系统)和 Jenkins(自动构建系统)组成。它们覆盖的软件打包、任务编排上线、任务部署、部署验证任务的完整流程。
其中,包管理系统 PSRForge 是我们自行开发的,因为当时我们没有找到合适的开源项目。我们的团队目前维护着大概 230 个软件包。包管理系统共分为三个子系统,分别是 Spec 管理系统、软件包自动构建系统和软件仓库管理系统。
配置管理系统是 OpenStack 服务持续交付工具链的核心组件。在谨慎的调研和考量后,我们选择了 Puppet 作为配置管理工具。在此我想强调的是,没有任何一个工具是万能的,既然选择使用一个工具,运维团队必须清晰地明确它的能力和局限。拿 Puppet 来说,它非常适合做软件包的安装、配置文件的管理、服务状态的管理、命令的执行等;但它也有一些天然的短板,比方说不太适合做源代码的管理、依赖包的管理,也不太适合做服务的初始化操作、服务状态的监控和恢复,以及节点间的依赖管理。
因为 Puppet 缺少任务编排能力,因此我们一直在寻找一个工具,可以达到我们的期望。任务编排系统我们最终选择使用的是 Ansible。在此之前,我们陆续使用过 Dispatcher、ClusterShell 和 Mcollective 。其中,Dispatcher 是我们基于 SSH+ini 配置文件自行编写的,后来我们发现开源项目 ClusterShell 同样是基于 SSH,并且功能十分完善。后来我们转向 Mcollective,这是 Puppet Lab 专门收购的一款配置管理工具,后来放弃 Mcollective 的主要原因是它的架构过重,同时是用 Ruby 语言编写的,而统一一直是我们追求的目标。Ansible 目前在 UnitedStack 的运维效果我们是比较满意的,它的优势体现在无代理、基于 yaml 的配置文件,并且可用于集群的任务编排。
Jenkins 是目前业内运用最为广泛的自动构建系统。目前,UnitedStack 所有重复性的工作,比如执行单元测试、集成测试、构建软件包等工作必须以 Jenkins 的 job 形式出现,这样使得打包和测试工作自助化,也是我们实现自动化运维的前提。目前,UOS 的各项目单元测试、UOS 各项目打包、Doctor 集成测试、UOS 环境构建和清理已经全部在 Jenkins 平台完成。
3. 统一的流程 在高速运转的持续交付流水线中,流程的统一举足轻重,这也就意味着流程的制定是非常关键的,要既合理,又尽量简单。目前,我们使用的流程包括软件包管理、线上服务变更、软件发布周期管理、部署逻辑代码提交、公共库变更等等。
我个人觉得非常值得分享的是我们的持续打磨的 OpenStack 跨大版本升级流程。我们是从 2011 年的 Diablo 版本开始接触 OpenStack,期间经历了数次的大版本升级,至今已经总结出了相对成熟的大版本升级的具体流程。
在研发端,研发团队需要确认项目的 upstream Base,也就是确认版本的合并点;然后,完成私有 patch 的合并工作;第三,给出依赖库的版本变更列表,放入 requirements 项目中;第四,给出配置选项的变更列表;第五,给出数据库 schema 的变更版本,以方便部署是的检查。
在部署端,我们首先需要更新 SPEC、SOURCES 文件,制作新版本软件包;然后更新 puppet-xxx module,合并私有 patch;接下来在开发环境上线进行调试,并且打上预发布版本号,在测试环境上线,同时需要通过集成测试。
线上的变更是需要特别谨慎的,稍有不慎就会有意外事件的发生。在版本最终上线前,开发团队需要给出线上业务变更单,说明业务变更内容,可能造成的影响,执行流程,回滚流程等;涉及公共库变更的,需要所有相关人员确认;业务的变更流程已预先制定完成,则必须借助工具自动执行。你只能与命令行工具做交互,输入 Yes or No,但不能输入任何命令。
4. 统一的接口 在 UnitedStack,我们的自研项目和 OpenStack 项目都提供了统一的 API,我们也有自己的命令行工具(UOS CLI)对一些资源操作进行封装和简化,这些前提使得我们的自动化测试工作变成可能。
以此为基础,我们构建起名为 Doctor 的健康检查服务。Doctor 服务主要的功能包括,诊断 UOS 所有的服务是否正常;恢复 UOS 所有的服务至正常状态;收集 UOS 服务的错误日志和相关的系统信息。
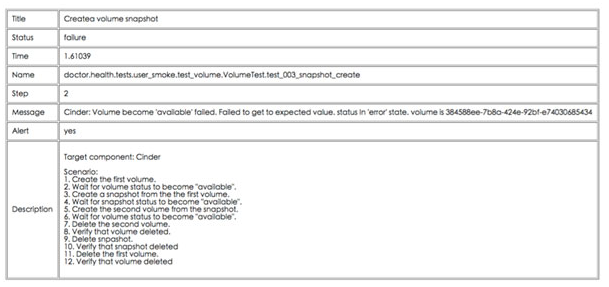
下图是创建 volume snapshot 操作失败后的反馈,Doctor 服务会描述操作的执行时间、执行过程、故障发生的步骤、服务的错误日志等,都会详细地展示并说明。
【注】演讲者余兴超是 UnitedStack 运维团队负责人、OpenStack 社区核心开发者,目前负责 UnitedStack 运维组的工作。他努力追求极致的运维管理服务技术,同时也是 OpenStack 多个项目的深度参与开发工程师。




