从 Tachyon 的官网得知,Tachyon 是一个高性能、高容错、基于内存的开源分布式存储系统,并具有类Java 的文件API、插件式的底层文件系统、兼容Hadoop MapReduce 和 Apache Spark 等特征。Tachyon 能够为集群框架(如 Spark、MapReduce 等)提供内存级速度的跨集群文件共享服务。Tachyon 充分使用内存和文件对象之间的世代(Lineage)信息,因此速度很快,官方号称最高比HDFS 吞吐量高300 倍。目前,很多公司(如Pivotal、EMC、红帽等)已经在使用Tachyon,并且来自20 个组织或公司(如雅虎、英特、红帽等)的60 多个贡献者都在为其贡献代码。Tachyon 是于 UC Berkeley 数据分析栈 ( BDAS ) 的存储层,它还是 Fedroa 操作系统自带应用。
Tachyon 具有的重要特征如下:
- 类 Java 的文件 API: Tachyon 的原生 API 同 Java 的文件类非常相似,并提供了 InputStream 和 OutputStream 接口,还支持内存映射 IO;
- 兼容 MapReduce 和 Spark:Tachyon 实现了 Hadoop 的 FileSystem 接口,因此,MapReduce 和 Spark 无需做任何修改就可以使用 Tachyon;
- 插件式的底层文件系统:Tachyon 基于 Hadoop 并从底层重建了 Hadoop 平台。Tachyon 具有一个通用、方便于接入不同底层文件系统的接口。目前支持的文件系统包括 HDFS、S3、GlusterFS、单节点本地文件系统等,对其他文件系统的支持将很快实现。
- 支持本地原始表:Tachyon 提供了对多列数据的本地支持,且提供了选择项,以决定是否将 Hot 列放入内存以节省空间;
- 浏览文件系统的 Web 界面:用户能够通过 Web 界面浏览文件系统,尤其在 Debug 模式下,管理员还能够查看每个文件的详细信息,如文件位置、检查点(Checkpoint)路径等;
- 支持命令行交互: 用户能够使用命令“./bin/tachyon tfs”同 Tachyon 进行交互,如往文件系统中复制数据以及从文件系统往外复制数据;
- 高容错性:Tachyon 具有良好的容错机制,Master 和 Worker 都有自己的容错方式。Master 使用 ZooKeeper 进行容错,Master 中保存的元数据使用 Journal 进行容错,Master 还对各个 Worker 的状态进行监控,发现 Worker 失效时会自动重启对应的 Worker。对于具体的文件数据,Tachyon 使用世代关系进行容错。
Tachyon 采用了 Master-Worker 模式,运行中的 Tachyon 系统由一个 Master 和多个 Worker 构成。Tachyon Master 管理全部文件的元数据信息,同时也负责监控各个 Tachyon Worker 的状态。为了高效地对文件进行管理,Tachyon 文件在内存中按块组织。文件和块信息保存在 Master 端,每个 Worker 以块为单位进行存储和管理。Tachyon 的架构如下图所示:
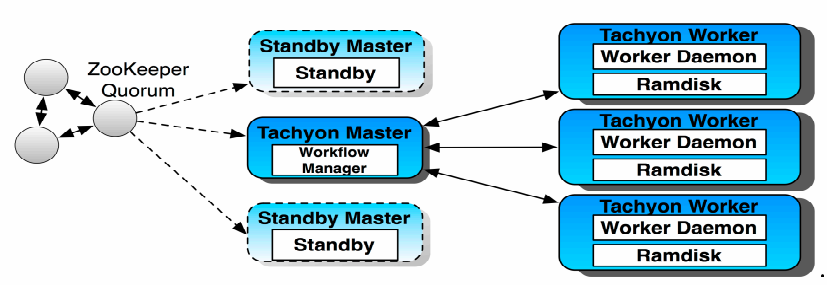
Tachyon 诞生于 UC Berkeley 的 AMPLab ,由该实验室的计算机在读博士李浩源初创,并基于 Apache License 2.0 开源协议发布,代码托管在 GitHub ,其当前最新版本为 0.6.1 。去年 10 份,李浩源在接受 InfoQ 采访时曾表示:
长期来讲,他们对待 Tachyon 会像对待 Apache Mesos 和 Apache Spark 一样,Tachyon 也会进入 Apache 软件基金会,这里欢迎更多的开发者加入。
近日,从华尔街日报消息得知,Tachyon 获得了硅谷风投 A16Z 的 750 万美元 A 轮投资。AMPLab 的项目还包括与 Hadoop 相似、启用了内存分布数据集的开源集群计算环境 Spark 、类似于基于键 / 值存储的 SQL 查询语言 PIQL 、基于分布式系统的机器学习系统 MLBase 、多核和大型 SMP 系统的操作系统 Akaros 、低延迟计算集群调度系统 Sparrow 等。此外,Tachyon 官网还提供了相关文档,如用户文档、开发者文档等。更多关于Tachyon 的信息,读者可以登录其官网或其GitHub 提供的 Wiki 页面查看。
感谢徐川对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(InfoQ)关注我们,并与我们的编辑和其他读者朋友交流。




