Espresso 是一个来自 LinkedIn 的分布式 NoSQL 数据库,其具有高性能、高扩展性、支持事务、容错能力等重要特征。在 LinkedIn,Espresso 有着强大的应用规模,它运行在十几个集群中,并且已有将近 30 个应用在使用 Espresso,如 Member Profile 、 InMail 、 LinkedIn 的手机客户端等。在高峰期,它能够每秒处理数百万的访问记录。Espresso 由 LinkedIn 的分布式数据系统团队基于高性能的数据抓取系统 Databus 、 R2D2 、通用的集群管理框架 Apache Helix 等开源技术开发,用来解决关系型数据库(如 MySQL、Oracle 等)不能满足当前线上并发业务的性能要求的问题以及关系型数据库固有的一些局限性,如扩展性差、容错处理能力差、成本高等。
Espresso 具有一个分层的数据模型,其结构为数据库(Database)-> 表(Table)> 集合(Collection)-> 文档(Document)。Espresso 使用 JSON 数据格式定义数据库 Schema 和表 Schema,使用数据序列化的系统 Apache Avro 定义文档 Schema。Espresso 的表是同一类型文档的容器,使用指定 Key 所确定的文档就是一个集合,一个指定的 Key 唯一确定一个文档,一个文档 Schema 对应一个 Avro 的 Schema。Espresso 提供了简单、易用的读 / 写操作的 REST 风格 API 和基于 Last-Modified 和 ETag 的条件操作 API,其中的写操作 API 还具有事务性。
Espresso 的整个架构如下图所示:
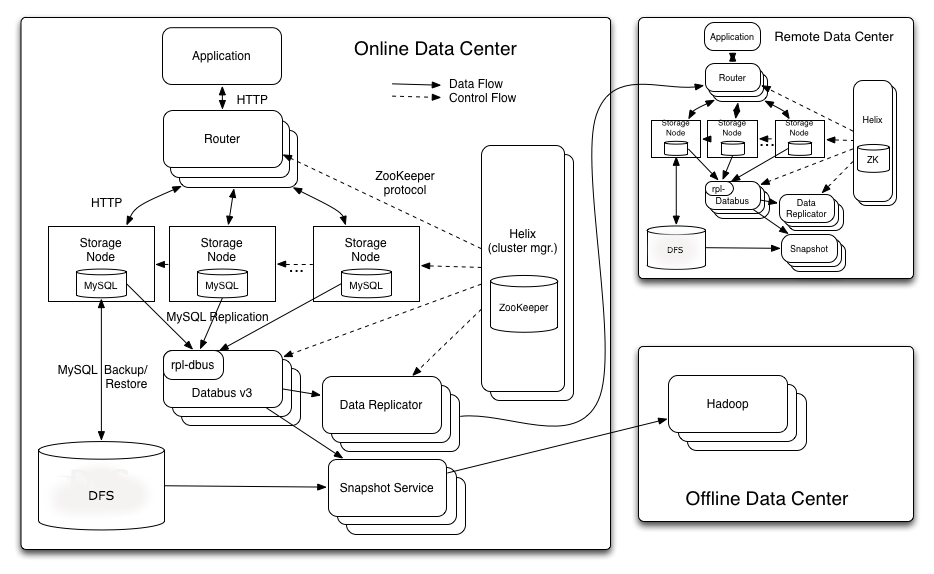
-
路由器(Router)路由器是一个无状态的 HTTP 代理,它是客户端访问 Espresso 的入口。路由器首先检查请求的 URL 以确定需要访问的数据库(除了内部的 Schema 注册数据库,该数据库能够映射到任何节点),并根据分区 Key 以确定请求对应的分区,并将请求转发到对应的存储节点。路由器还有一个本地的缓存路由表,该路由表映射分区的分布情况。当集群的状态发生变化时,路由表通过分布式应用程序协调服务应用 Apache ZooKeeper 实现路由器的更新,并以并行的方式实现跨分区的批量请求。
-
存储节点(Storage Node)存储节点是集群扩展和数据存储的基本单元,每个存储节点都包括一套分区。路由器能够将发送请求转发到存储节点,存储节点的功能包括查询处理、作为存储引擎、实现二级索引、处理节点状态的转换、支持本地事务、提交复制日志、定时备份以及一致性检查和数据验证等工具类功能。
-
集群管理框架 HelixEspresso 使用 Helix 进行集群管理。Espresso 的状态模型具有 OFFLINE、SLAVE 和 MASTER 状态。Espresso 的状态模型约束包括每个分区必须至少有一个 Master 节点和 n 个可配置的 Slave 节点、分区分布在所有的存储节点上、在同一个基点上不存在同一分区的副本、当 Master 节点出现故障时,Slave 节点要能够升级成为 Master 节点。
-
低延迟数据抓取系统 DatabusEspresso 使用 Databus 实现变化捕获机制,Databus 能够处理 Espresso 事务日志,Databus 的重要特征包括来源独立、可扩展、高度可用、低延迟、支持多种订阅机制和无限回溯等。Espresso 使用 Databus 目的包括:(1)将事件传递给下游消费者,如搜索的索引和缓存等;(2)实现 Espresso 的多数据中心的复制。Databus 的结构如下图所示:
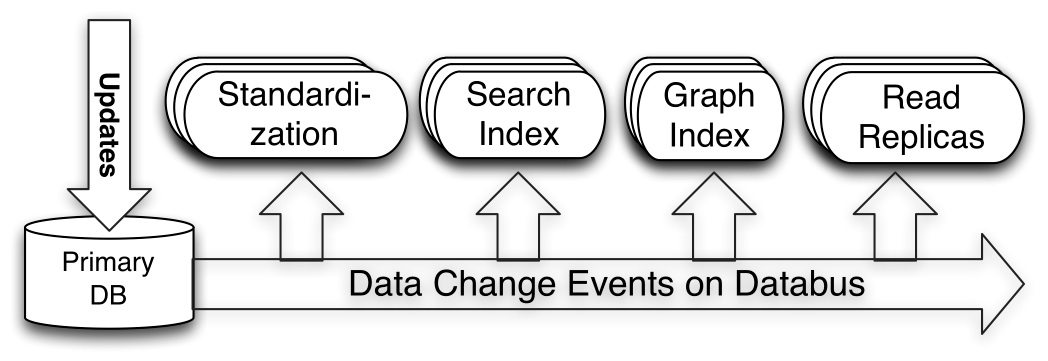
-
数据复制服务(Data Replicator)
数据复制是一个在跨地域复制的 Espresso 集群间转发提交请求的服务,该服务由 Helix 管理的无状态集群实例构成,并具有容错处理能力和线上 / 线下的 Helix 状态模型。数据复制服务是 Databus 的一个 Consumer,用来处理集群中的数据库分区事件,它还能够在数据中心之间批量处理事件以提升高延迟的链接线路的吞吐量。该服务定期检查 ZooKeeper 的复制进度以及节点故障、服务重启等,每个节点负责一定数量分区的复制,具体负责哪些分区由 Helix 指定。一旦节点发生故障,属于故障节点负责的分区会被重新分配给正常的节点。当一个节点开始处理新指派的分区时,它会从保存在 Zookeeper 中的最近检查点重新执行相关处理 / 操作。
-
快照服务(Snapshot Service)
快照服务能够自动、定期地备份数据中心的所有 Espresso 节点的数据,且对正在运行的集群影响非常小。快照服务本身也是一个分布式系统,并与数据复制服务一样具有相同的线上 / 下状态模型。最近备份的元数据信息也将写入到 ZooKeeper,叫做“znode”的节点是存储元数据的地方。
Espresso 的关键特征和实现细节内容如下:
-
序列号 -- Espresso 时钟Espresso 使用一个内置的时钟以确定事件的全序关系,时序对集群间的复制和 Databus 都是非常重要的。每个成功的操作(如插入、更新、删除)都分配了一个 64 位的系统改变码(SCN),SCN 由 MySQL 在事务提交时生成,其是单调递增且由每个分区独立维护。
-
Schema 的管理Espresso 的 Schema 存储在 ZooKeeper 中,该组件在所有服务中可共享。
-
Schema 的演变Espresso 的文档 Schema 根据 Avro 的 Schema 演化规则的改变而改变,且还有一些的规范限制。
-
容错处理
Espresso 的集群管理使用 Helix 来实现,存储节点是真是数据的来源,所以容错功能是至关重要的。在 Espresso 中,每个节点既有 Slave 分区,也有 Master 分区。容错处理的情况包括(1)当一个存储节点连接到 Helix 时,该节点会在 Zookeeper 中创建一个临时节点,该节点由 Helix 监视;(2)当一个节点出现故障时,如管理了 Socket 连接或者没有响应心跳检测,Zookeeper 移除该临时节点;(3)在删除一个节点出现故障时,Helix 会更新外部试图来排除出现故障的节点;(4)一旦生成“ideal state”,Helix 就会根据定义好的状态模型进行状态转换 。在 Espresso 中,每个受到影响的分区的 Slave 节点将会收到 SLAVE->MASTER 的转换信息。
-
备份恢复服务(Backup Restore )
Espresso 的存储节点能够定期备份所有分区,压缩后的存储节点数据流备份镜像会存储到一个分布式文件系统里,在每个分区生成的备份能够在扩展时跨迁移。备份数据能够用来恢复故障节点、启动新的集群、扩展已存在的集群等。
-
其它 Espresso 还有其他一些有趣的特性,如 集群扩展、每个数据库的定额管理、批量加载 HDFS 中的数据、自动实化集群、组提交、冲突解决等。
更多关于 Espresso 的相关信息,请读者阅读 2013 年 ACM SIGMOD 数据管理国际会议上关于Espresso 的论文和Swaroop Jagadish关于Espresso 的演示稿。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




