Apache Falcon 是一个面向 Hadoop 的、新的数据处理和管理平台,设计用于数据移动、数据管道协调、生命周期管理和数据发现。它使终端用户可以快速地将他们的数据及其相关的处理和管理任务“上载(onboard)”到 Hadoop 集群。近日,Apache 基金会宣布 Falcon 升级为顶级项目。
Apache Falcon 项目副主管 Srikanth Sundarrajan 说:
Apache Falcon 解决了大数据领域中一个非常重要和关键的问题。升级为顶级项目是该项目的一个重大进展。Apache Falcon 有一个完善的路线图,可以减少应用程序开发和管理人员编写和管理复杂数据管理和处理应用程序的痛苦。
用户会发现,在 Apache Falcon 中,“基础设施端点(infrastructure endpoint)”、数据集(也称 Feed )、处理规则均是声明式的。这种声明式配置显式定义了实体之间的依赖关系。这也是该平台的一个特点,它本身只维护依赖关系,而并不做任何繁重的工作。所有的功能和工作流状态管理需求都委托给工作流调度程序来完成。下面是 Falcon 的架构图:
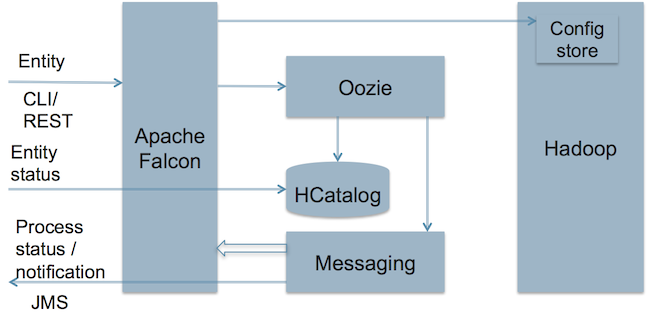
从上图可以看出,Apache Falcon:
- 在 Hadoop 环境中各种数据和“处理元素(processing element)”之间建立了联系;
- 可以与 Hive/HCatalog 集成;
- 根据可用的 Feed 组向最终用户发送通知。
而按照开发人员 Michael Miklavcic 的说法,Apache Falcon 使他们的团队逐步构建起一个复杂的管道。该管道包含超过 90 个 Process 和 200 个 Feed。如果单独使用 Apache Oozie,这会是一项重大挑战。Hortonworks 工程部门副总裁 Greg Pavlik 则表示,Apache Falcon 是用于“数据湖(Data lake)”建模、管理和操作的最好的、最成熟的构建模块。Hortonworks 官方网站上提供了一个在 Hadoop 中使用 Apache Falcon 的示例。
另外,在升级成为顶级项目之前,Apache Falcon 已经在多个行业中获得了广泛的应用,包括广告、医疗、移动应用等。InMobi 是该平台的最大用户之一。该公司的联合创始人兼首席技术官 Mohit Saxena 表示:
对于社区而言,Apache Falcon 项目毕业是一个令人自豪的时刻。他们一起解决了 Hadoop 生态系统中一个非常重大的数据处理和管理问题。
Apache Falcon 遵循 Apache 许可协议 2.0。要了解更多信息,请点击这里。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




