【编者的话】如果能在一台服务器上应用人工智能和机器学习算法处理每天的股票交易,而自己则在夏威夷的海滩上享受生活,那将是多么惬意呀。虽然股票价格的变化受多种因素的影响,世上也没有免费的午餐,但是有些公司依然能够借助于开源的机器学习算法和数据分析平台得到“更好、更健康、更便宜的午餐”。本文搜集并整理了一些如何实现实时股票分析系统的资料,从架构和算法两个层面给出了一种可行的方案。
虽然股票交易市场一直在持续地变化,经济力量、新产品、竞争、全球性的事件、法规、甚至是 Tweet 都有可能引起市场的变动,但是在这个市场上,使用不同的模型通过股票的历史价格来预测未来的价格依然是一种常见的实践。一个实时的股票分析系统不仅需要将影响股票价格的各种数据集合起来进行分析,还需要具有响应低延迟的特性,因而架构必须是高可伸缩、高扩展的,一方面随着时间的流逝,系统将存储越来越多的数据;另一方面数据处理应用程序必须能够通过添加更多的节点进行水平扩展以保持实时地响应速度。
来自于 Pivotal 公司的企业应用解决方案架构师 William Markito 最近在公司的博客上发表了题为《实时股票预测系统开源参考架构》的文章,介绍了一个通过开源技术实现实时股票分析系统的参考架构。虽然该架构关注于金融交易,但是也适用于其他行业的实时用例场景。 William Markito 首先从最顶层的视角,给出了一个高层架构图:
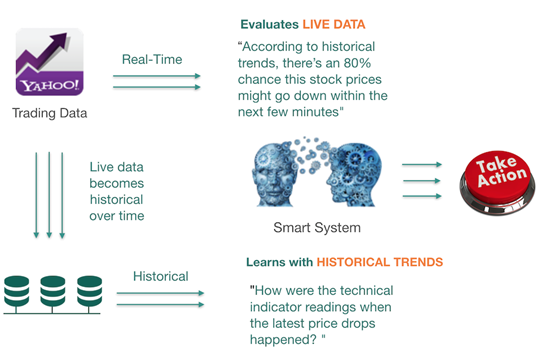
从最顶层的视角看,由预测模型驱动的最优化实时股票预测架构包含数据存储、模型训练、实时评估和采取行动四部分:首先,进入系统的实时交易数据必须被捕获并存储,作为历史数据。第二,系统必须能从数据的历史趋势中学习,识别出影响决定的模式和概率。第三,系统需要能够实时地将新传入的交易数据与从历史数据中学到的模式和概率进行比较。最后,系统还需要预测出输出并决定所要采取的行动。
之后, William Markito 又使用 Spring XD (现在称为 Spring Cloud Data Flow ,是一个统一并且可扩展的分布式系统,可用于数据抽取、实时分析、批量处理和数据导出场景)、 Apache Geode (一个针对高可扩展应用程序的开源分布式内存数据库,目前正在孵化中)、 Spark MLlib 、 Apache HAWQ (一个 Hadoop 原生的大规模并行 SQL 分析引擎)以及 Apache Hadoop™等开源组件对架构中的每一部分进行了细化:
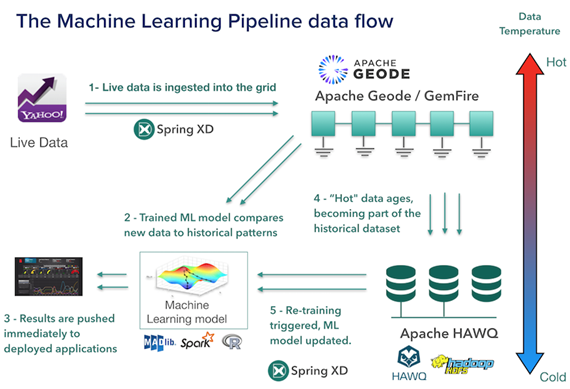
如图所示,整个数据流包含 6 步,每一部分都是松耦合并且可以水平扩展的:
- 使用 Spring XD 读取并处理通过 Yahoo! 金融 Web 服务 API 获取到的实时数据,然后通过 Apache Geode 将数据存储在内存中。
- 使用 Apache Geode 中的实时热数据,通过 Spark MLib 应用创建并训练模型,将新数据与历史模式进行比较。当然,也可以使用其他工具集创建模型,例如 Apache MADlib 或者 R 。
- 将训练出的机器学习模型推送到部署好的应用程序上,同时更新 Apache Geode 以便于进行实时预测和决策。
- 随着时间的推移,有一部分数据将变成冷数据,将这一部分数据从 Apache Geode 移动到 Apache HAWQ 上并最终存储到 Apache Hadoop™中。
- 周期性地基于整个历史数据集重新训练并更新机器学习模型。这一步让系统形成了一个闭环,当历史模式发生变化或者新的模式出现的时候,它会持续地更新和提升模型。
为了让读者能够在自己的笔记本上运行这一架构, William Markito 还给出了一个更为简化的实现,该版本移除了长期的数据存储组件Apache HAWQ 和Apache Hadoop™。
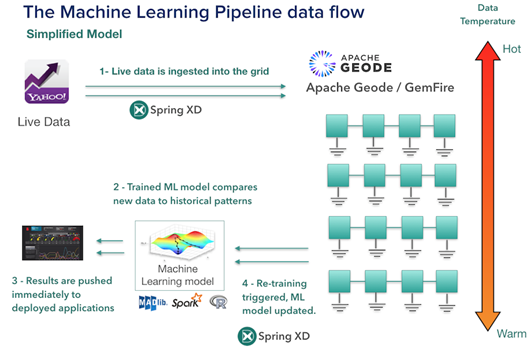
该解决方案中的每一个组件都责任明确,支持扩展并且能够在云环境中运行。那么除了架构之外,针对影响股票价格的不同因素,应该选择哪些算法来训练模型并预测股票价格趋势呢?
在SlideShare 上LargitData 的CEO David Chiu 介绍了如何通过隐马尔科夫模型(HMM)来预测股票价格, David Chiu 认为股票的历史行为与当前行为具有一定的相似性,明天的股票价格可能会遵循过去的某种模式:
另外,在 Vatsal H. Shah 的网站上还有一个文档介绍了Decision Stump 算法、线性回归、支持向量机、Boosting 算法和基于文本分析的方法在股票预测领域的应用,并对这些算法的预测结果进行了比较。
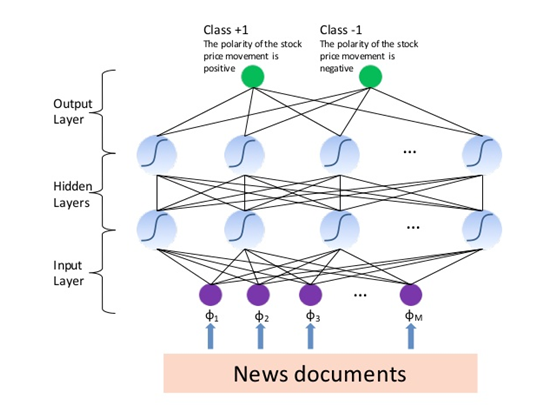
除此之外,与上市公司相关的新闻动态也会对股票价格造成影响,例如并购定增事项、公司领导人的离开等等,对于这一问题,新加坡的数据科学家Lim Zhi Yuan 在 SlideShare 上分享了一些自己的经验。Lim Zhi Yuan 在该分享中研究了外部事件对于股票价格的影响,在分析时他分别通过线性模型和非线性模型两种方法进行了实验,线性模型采用了支持向量机(SVM)算法,非线性模型采用了深度神经网络模型。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




