近日, Linkedin 宣布开源其正在使用的大数据计算引擎 Cubert ,该框架提供了一种新的数据模型来组织数据,并使用诸如 MeshJoin 和 Cube 算法等算法来对组织后的数据进行计算,从而减轻了系统负荷和节省了 CPU 资源,最终提供给用户一个简单、高效的查询。Cubert 比较适合的计算领域包括统计计算、聚合、时间距离计算、增量计算、图形计算等。
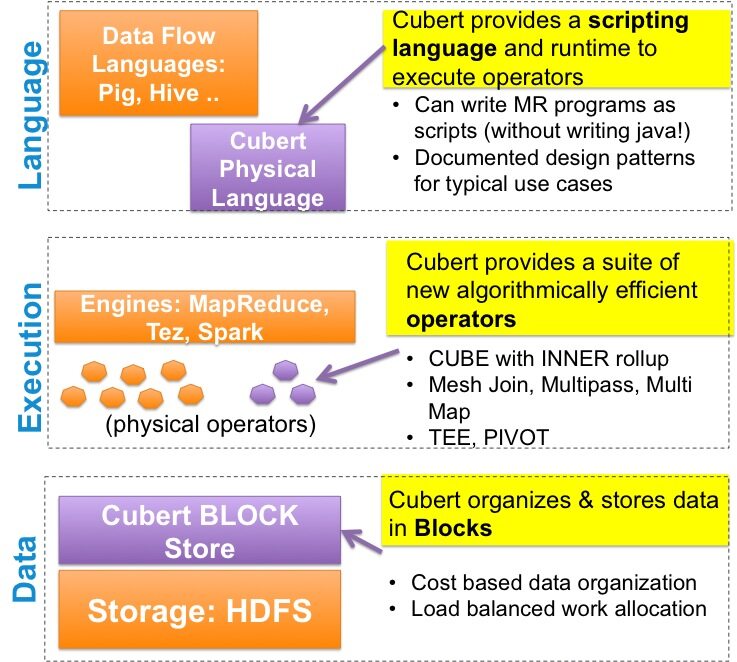
Cubert 整个架构可分为三层,第一层是数据流语言层,主要用来实现执行计划,包括 Apache Pig 、 Apache Hive 以及 Cubert Script;中间层是执行计划的分布式引擎层,包括 Map-Reduce、Tez 和 Spark 以及各个算法实现;最底层是数据存储层,Cubert 根据数据模型以数据分区的形式组织和存储,且数据分区由 HDFS 提供的文件系统管理。Cubert 架构如下图所示:
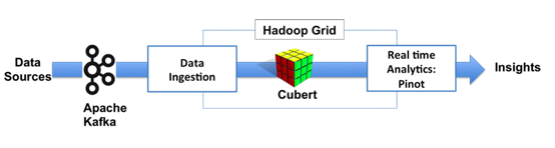
LinkedIn 把 Cubert 作为一个关键组件来处理数据,其中 Kafka 负责实时消息传递给 Hadoop,Hadoop 负责数据的存储,Cubert 负责处理数据,处理后数据流向 Pinot 进行实时分析。数据流向图如下所示:
另外,LinkedIn 还为 Cubert 创建了一门新语言 Cubert Script,该语言为不同的 Job 明确定义了 Mapper、Reducer 和 Combiner 等操作,其目的是使得开发人员无需做任何形式的自定义编码就能够轻松地使用 Cubert。Cubert 还提供了一套丰富的数据处理的操作,包括输入 / 输出操作(如 LOAD、STORE、TEE 等)、转换操作(如 FROM、GENERATE、FILTER 等)、聚合操作(如 GROUP BY、CUBE)、数据移动操作(如 SHUFFLE、BLOCKGEN、COMBINE 等)、字典操作等。接下来 Cubert 还将实现 Tez 执行引擎、Cubert Script v2、增量计算、用于分析的窗函数等。Cubert 遵循 Apache License Version 2.0 开源协议发布,读者朋友们如果想尝试或者研究 Cubert 的话,您可以参考 Cubert使用指导和Javadoc 。
感谢崔康对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




